
YOLOv11 for Advanced Document Layout Analysis
![]()
This repository hosts three YOLOv11 models (nano, small, and medium) fine-tuned for high-performance Document Layout Analysis on the challenging DocLayNet dataset.
The goal is to accurately detect and classify key layout elements in a document, such as text, tables, figures, and titles. This is a fundamental task for document understanding and information extraction pipelines.
✨ Model Highlights
- 🚀 Three Powerful Variants: Choose between
nano,small, andmediummodels to fit your performance needs. - 🎯 High Accuracy: Trained on the comprehensive DocLayNet dataset to recognize 11 distinct layout types.
- ⚡ Optimized for Efficiency: The recommended
yolo11n(nano) model offers an exceptional balance of speed and accuracy, making it ideal for production environments.
🚀 Get Started
Get up and running with just a few lines of code.
1. Installation
First, install the necessary libraries.
pip install ultralytics huggingface_hub
2. Inference Example
This Python snippet shows how to download a model from the Hub and run inference on a local document image.
from pathlib import Path
from huggingface_hub import hf_hub_download
from ultralytics import YOLO
# Define the local directory to save models
DOWNLOAD_PATH = Path("./models")
DOWNLOAD_PATH.mkdir(exist_ok=True)
# Choose which model to use
# 0: nano, 1: small, 2: medium
model_files = [
"yolo11n_doc_layout.pt",
"yolo11s_doc_layout.pt",
"yolo11m_doc_layout.pt",
]
selected_model_file = model_files[0] # Using the recommended nano model
# Download the model from the Hugging Face Hub
model_path = hf_hub_download(
repo_id="Armaggheddon/yolo11-document-layout",
filename=selected_model_file,
repo_type="model",
local_dir=DOWNLOAD_PATH,
)
# Initialize the YOLO model
model = YOLO(model_path)
# Run inference on an image
# Replace 'path/to/your/document.jpg' with your file
results = model('path/to/your/document.jpg')
# Process and display results
results[0].print() # Print detection details
results[0].show() # Display the image with bounding boxes
📊 Model Performance & Evaluation
We fine-tuned three YOLOv11 variants, allowing you to choose the best model for your use case.
yolo11n_doc_layout.pt(train4): Recommended. The nano model offers the best trade-off between speed and accuracy.yolo11s_doc_layout.pt(train5): A larger, slightly more accurate model.yolo11m_doc_layout.pt(train6): The largest model, providing the highest accuracy with a corresponding increase in computational cost.
As shown in the analysis below, performance gains are marginal when moving from the small to the medium model, making the nano and small variants the most practical choices.
Nano vs. Small vs. Medium Comparison
Here's how the three models stack up across key metrics. The plots compare their performance for each document layout label.
| mAP@50-95 (Strict IoU) | mAP@50 (Standard IoU) |
|---|---|
 |
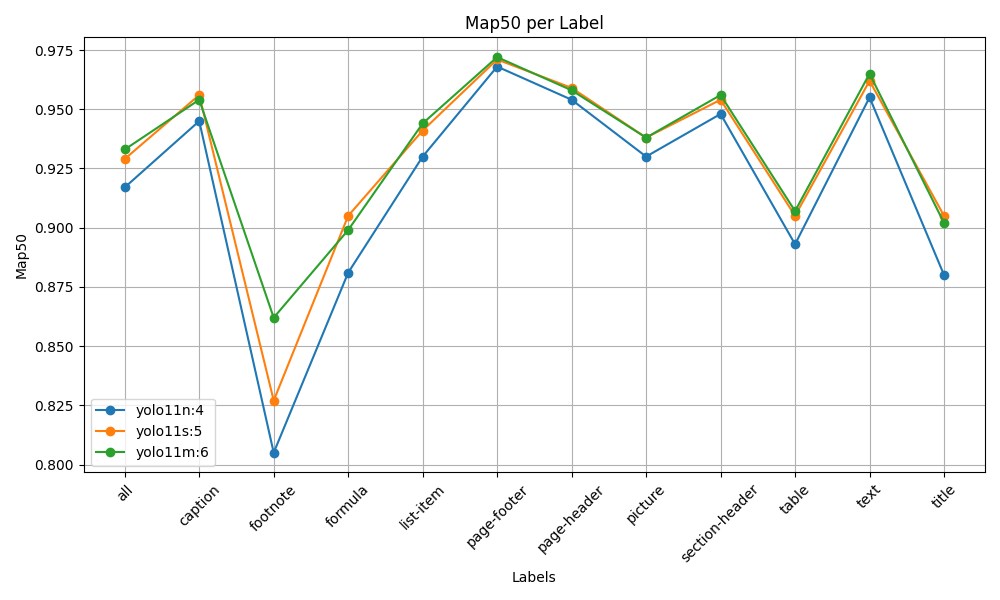 |
| Precision (Box Quality) | Recall (Detection Coverage) |
|---|---|
 |
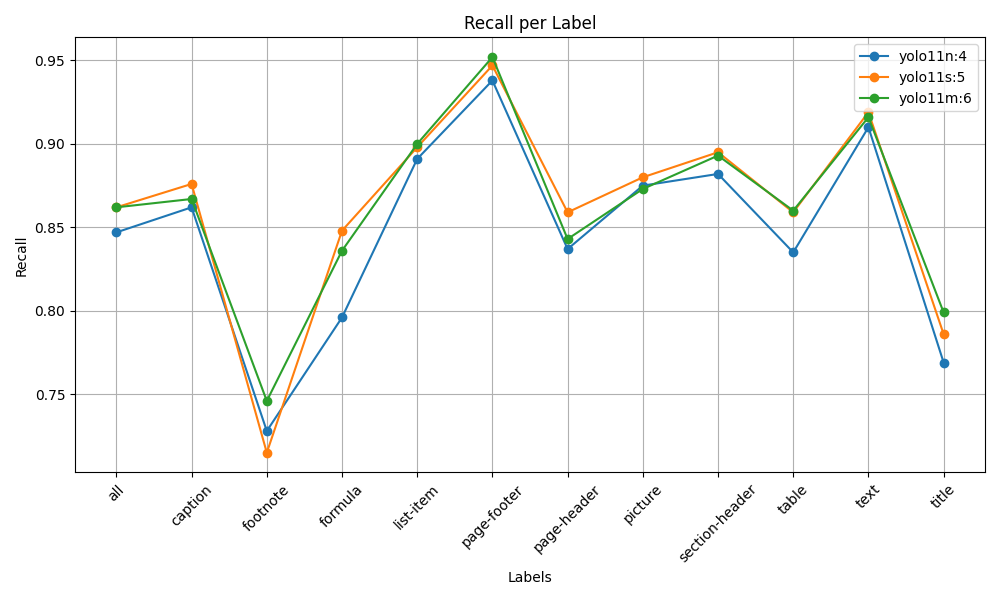 |
Click to see detailed Training Metrics & Confusion Matrices
| Model | Training Metrics | Normalized Confusion Matrix |
|---|---|---|
yolo11n (train4) |
 |
 |
yolo11s (train5) |
 |
 |
yolo11m (train6) |
 |
 |
🏆 The Champion: Why train4 (Nano) is the Best Choice
While all nano-family models performed well, a deeper analysis revealed that train4 stands out for its superior localization quality.
We compared it against train9 (another strong nano contender), which achieved a slightly higher recall by sacrificing bounding box precision. For applications where data integrity and accurate object boundaries are critical, train4 is the clear winner.
Key Advantages of train4:
- Superior Box Precision: It delivered significantly more accurate bounding boxes, with a +9.0% precision improvement for the
titleclass and strong gains forsection-headerandtable. - Higher Quality Detections: It achieved a +2.4% mAP50 and +2.05% mAP50-95 improvement for the difficult
footnoteclass, proving its ability to meet stricter IoU thresholds.
| Box Precision Improvement | mAP50 Improvement | mAP50-95 Improvement |
|---|---|---|
 |
 |
 |
In short, train4 prioritizes quality over quantity, making it the most reliable and optimal choice for production systems.
📚 About the Dataset: DocLayNet
The models were trained on the DocLayNet dataset, which provides a rich and diverse collection of document images annotated with 11 layout categories:
- Text, Title, Section-header
- Table, Picture, Caption
- List-item, Formula
- Page-header, Page-footer, Footnote
Training Resolution: All models were trained at 1280x1280 resolution. Initial tests at the default 640x640 resulted in a significant performance drop, especially for smaller elements like footnote and caption.

💻 Code & Training Details
This model card focuses on results and usage. For the complete end-to-end pipeline, including training scripts, dataset conversion utilities, and detailed examples, please visit the main GitHub repository:
- Downloads last month
- 632
Model tree for Armaggheddon/yolo11-document-layout
Base model
Ultralytics/YOLO11