
metadata
title: Data Analyst Chatbot
emoji: 😻
colorFrom: green
colorTo: green
sdk: docker
app_port: 8501
tags:
- streamlit
pinned: false
short_description: YDATA Agents Assignment 1 - Chatbot on Bitext CustomerSvc
license: cc-by-nc-sa-4.0
Welcome to the Data Analyst Chatbot on the Bitext Customer Service Dataset
Bitext Customer Service Dataset is available from: https://huggingface.co/datasets/bitext/Bitext-customer-support-llm-chatbot-training-dataset
Folder Structure
src
|---streamlit_app.py - Code for our chatbot app hosted on Streamlit. Since a recent update, HuggingFace creates the Streamlit app file at 'src/streamlit_app.py' instead of 'app.py' in the root folder.
|---Bitext_Sample_Customer_Support_Training_Dataset_27K_responses-v11.csv
documentation
|---workings_in_jupyter.ipynb - includes (tested) code that was translated to our Streamlit app, and the last section (which was dropped) on chunking and uploading file parts to Gemini
|---Architecture_Diagram.png
|---Architecture_Diagram.drawio
|---<test*>.pdf - tests of our Streamlit app
.gitattributes - created by huggingface
Dockerfile - created by huggingface
README.md - you are in this file, which walks you through our chatbot's design
requirements.txt
Requirements
- We wanted to build a data analyst chatbot which answers questions which a user might have about the Bitext Customer Service Dataset.
- The chatbot should be able to answer the following types of questions defined by the rubric
- Structured questions (eg What are the most frequent categories?)
- Unstructured questions (eg Summarize )
- Dataset 'instruction' questions (eg Do you ship to ?) - Something extra we (as students) added
- Classify category or intent (eg What is the category of this question: ''?) - Something extra we (as students) added
- Out of domain questions (eg Who is Magnus Carlsen?)
Design Considerations and Constraints
- A Streamlit app
- A free LLM API which allows us to test without running into concerns with running out of credits - gemini-2.5-flash-preview-04-17-thinking
- A way to send relevant information/grounding context to the LLM
- We tried sending the full dataset in a dataframe containing approx 4.1m tokens. This failed because Gemini only accepts a maximum of 1m tokens as input
- We tried splitting the full dataset into 5 equal chunks (worked), uploaded each chunk for the chat interface (worked), but unable to use all 5 chunks (ie the full dataset) in the chat (failed)
- Since we were unable to send the huge dataset to Gemini, we explored sending a summary of the dataset
- Using questions in the rubric as a base, we also looked at the questions users might ask about the Bitext customer support dataset
- From these questions, we curated a summary which can be used by the LLM, then pass it to the LLM every time a user asks a question
dict_df_summary = {"df_head": str_df_head, "df_info": str_df_info, "df_shape": str_df_shape, "unique_category_intent": str_unique_category_intent, "category_counts": str_category_count, "intent_counts": str_intent_count, "category_intent_counts": str_category_intent_count, "5examples_per_category_intent": str_5examples_per_category_intent}
- Tools
- A way for the LLM to do a search on the web to answer out of domain questions - Equipped the LLM with the 'GoogleSearch' tool
- A way for users to verify the claims of a LLM if it performed a search on the web - Show search results below the answer for users to visit and verify the LLM's claims
- Because the LLM was able to answer questions in the rubric without any additional functions to analyse the dataset as tool calls, we have not added more tools, to simplify the model's architecture
- A way for the LLM to do a search on the web to answer out of domain questions - Equipped the LLM with the 'GoogleSearch' tool
- Dropped having a 'Clear Chat' button - We explored ways for a 'Clear Chat' button to work with streamlit's chat_input, and the button just does not seem to work (failed).
- A free, open-source LLM evaluation platform to track usage of our chatbot after deploying publicly - Opik
Architecture
- With the above design considerations and constraints, we created the chatbot with the following architecture
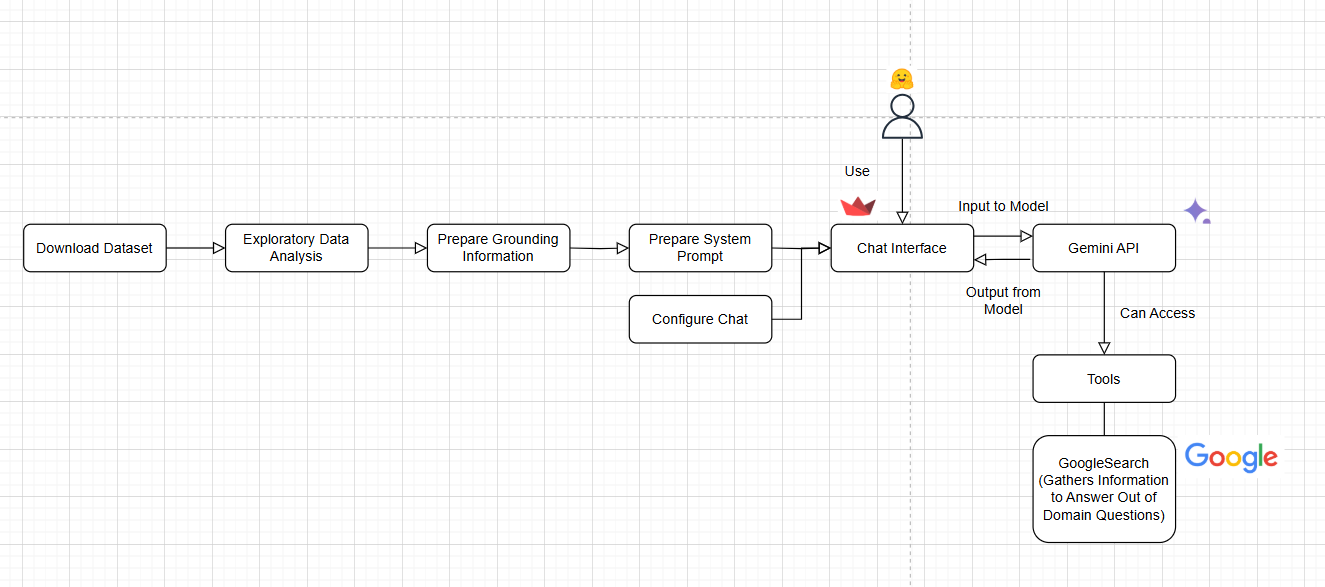
- Preparation steps
- For dataset and model
- Download dataset
- Exploratory data analysis
- Prepare grounding information
- Prepare system prompt
- Gemini API chat configuration
- Tool call - GoogleSearch
- For Streamlit app
- Configure chat interface
- For dataset and model
- During normal usage of the chatbot
- User loads the chat interface and picks a question from the 'Example questions' section
- User types their question in the 'Ask a question' box and submits their question to Gemini (our LLM)
- The system prompt (which contains the dataframe summary, i.e. grounding information) also gets sent to Gemini
- Gemini can
- Analyse the user's question and respond directly, sending the response back to our Streamlit app, which processes the response and shows on the chat box
- Alternatively assess whether a tool call is required
- If Gemini decides that a tool call is required to answer an 'out of domain' question', Gemini make 1 or more calls to the GoogleSearch tool
- Then Gemini will formulate a response, sends that response to our Streamlit app, to process and show on the chat box
- We also extract the search links and show below the LLM's answer, for users to verify the LLM's response if they wish
- If a user
- wishes to continue a chat (eg for multi-turn chats), they can submit a new question in the chat box
- wishes to clear all chats, please refresh the page
- Please note that the free Gemini API has rate limits. Please give around a 5 seconds pause after your previous answer, before you submit your next question.
