
DocExplainer: Document VQA with Bounding Box Localization
DocExplainer is a an approach to Document Visual Question Answering (Document VQA) with bounding box localization.
Unlike standard VLMs that only provide text-based answers, DocExplainer adds visual evidence through bounding boxes, making model predictions more interpretable.
It is designed as a plug-and-play module to be combined with existing Vision-Language Models (VLMs), decoupling answer generation from spatial grounding.
- Authors: Alessio Chen, Simone Giovannini, Andrea Gemelli, Fabio Coppini, Simone Marinai
- Affiliations: Letxbe AI, University of Florence
- License: apache-2.0
- Paper: "Towards Reliable and Interpretable Document Question Answering via VLMs" by Alessio Chen et al.

Model Details
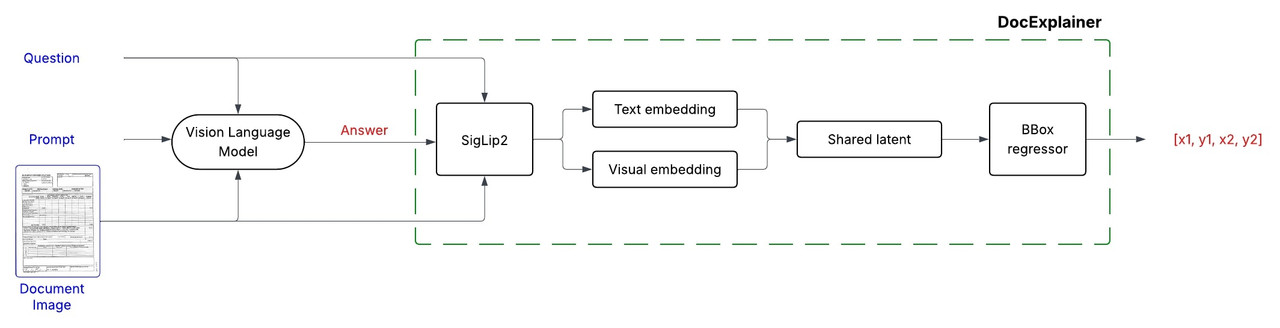
DocExplainer is a fine-tuned SigLIP2 Giant-based regressor that predicts bounding box coordinates for answer localization in document images. The system operates in a two-stage process:
- Question Answering: Any VLM is used as a black box component to generate a textual answer given in input a document image and question.
- Bounding Box Explanation: DocExplainer takes the image, question, and generated answer to predict the coordinates of the supporting evidence.
Model Architecture
DocExplainer builds on SigLIP2 Giant visual and text embeddings.
Training Procedure
- Visual and textual embeddings from SigLiP2 are projected into a shared latent space, fused via fully connected layers.
- A regression head outputs normalized coordinates
[x1, y1, x2, y2]. - Backbone: SigLiP2 Giant (frozen).
- Loss Function: Smooth L1 (Huber loss) applied to normalized coordinates in [0,1].
Training Setup
- Dataset: BoundingDocs v2.0
- Epochs: 20
- Optimizer: AdamW
- Hardware: 1 × NVIDIA L40S-1-48G GPU
- Model Selection: Best checkpoint chosen by highest mean IoU on the validation split.
Quick Start
Here is a simple example of how to use DocExplainer to get an answer and its corresponding bounding box from a document image.
from PIL import Image
import requests
import torch
from transformers import AutoModel, AutoModelForImageTextToText, AutoProcessor
import json
url = "https://i.postimg.cc/BvftyvS3/image-1d100e9.jpg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
question = "What is the invoice number?"
# -----------------------
# 1. Load SmolVLM2-2.2B for answer generation
# -----------------------
vlm_model = AutoModelForImageTextToText.from_pretrained(
"HuggingFaceTB/SmolVLM2-2.2B-Instruct",
torch_dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2"
)
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM2-2.2B-Instruct")
PROMPT = """Based only on the document image, answer the following question:
Question: {QUESTION}
Provide ONLY a JSON response in the following format (no trailing commas!):
{{
"content": "answer"
}}
"""
prompt_text = PROMPT.format(QUESTION=question)
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": prompt_text},
]
},
]
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(vlm_model.device, dtype=torch.bfloat16)
input_length = inputs['input_ids'].shape[1]
generated_ids = vlm_model.generate(**inputs, do_sample=False, max_new_tokens=2056)
output_ids = generated_ids[:, input_length:]
generated_texts = processor.batch_decode(
output_ids,
skip_special_tokens=True,
)
decoded_output = generated_texts[0].replace("Assistant:", "", 1).strip()
answer = json.loads(decoded_output)['content']
print(f"Answer: {answer}")
# -----------------------
# 2. Load DocExplainer for bounding box prediction
# -----------------------
explainer = AutoModel.from_pretrained("letxbe/DocExplainer", trust_remote_code=True)
bbox = explainer.predict(image, answer)
print(f"Predicted bounding box (normalized): {bbox}")
|
Example Output:
Question: What is the invoice number? |
Visualized Answer Location:

|
Performance
| Architecture | Prompting | ANLS | MeanIoU |
|---|---|---|---|
| Smolvlm-2.2B | Zero-shot | 0.527 | 0.011 |
| Anchors | 0.543 | 0.026 | |
| CoT | 0.561 | 0.011 | |
| Qwen2-vl-7B | Zero-shot | 0.691 | 0.048 |
| Anchors | 0.694 | 0.051 | |
| CoT | 0.720 | 0.038 | |
| Claude Sonnet 4 | Zero-shot | 0.737 | 0.031 |
| Smolvlm-2.2B + DocExplainer | Zero-shot | 0.572 | 0.175 |
| Qwen2-vl-7B + DocExplainer | Zero-shot | 0.689 | 0.188 |
| Smol + Naive OCR | Zero-shot | 0.556 | 0.405 |
| Qwen + Naive OCR | Zero-shot | 0.690 | 0.494 |
Document VQA performance of different models and prompting strategies on the BoundingDocs v2.0 dataset.
The best value is shown in bold, the second-best value is underlined.
Citation
If you use DocExplainer, please cite:
@misc{chen2025reliableinterpretabledocumentquestion,
title={Towards Reliable and Interpretable Document Question Answering via VLMs},
author={Alessio Chen and Simone Giovannini and Andrea Gemelli and Fabio Coppini and Simone Marinai},
year={2025},
eprint={2509.10129},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2509.10129},
}
Limitations
- Prototype only: Intended as a first approach, not a production-ready solution.
- Dataset constraints: Current evaluation is limited to cases where an answer fits in a single bounding box. Answers requiring reasoning over multiple regions or not fully captured by OCR cannot be properly
- Downloads last month
- 7