

Upload all models and assets for ang (latest)
Browse files- README.md +93 -89
- models/embeddings/aligned/ang_128d.bin +1 -1
- models/embeddings/aligned/ang_128d.projection.npy +1 -1
- models/embeddings/aligned/ang_32d.bin +1 -1
- models/embeddings/aligned/ang_32d.projection.npy +1 -1
- models/embeddings/aligned/ang_64d.bin +1 -1
- models/embeddings/aligned/ang_64d.projection.npy +1 -1
- models/embeddings/monolingual/ang_128d.bin +1 -1
- models/embeddings/monolingual/ang_32d.bin +1 -1
- models/embeddings/monolingual/ang_64d.bin +1 -1
- models/subword_markov/ang_markov_ctx1_subword.parquet +2 -2
- models/subword_markov/ang_markov_ctx2_subword.parquet +2 -2
- models/subword_markov/ang_markov_ctx3_subword.parquet +2 -2
- models/subword_markov/ang_markov_ctx4_subword.parquet +2 -2
- models/subword_ngram/ang_2gram_subword.parquet +2 -2
- models/subword_ngram/ang_3gram_subword.parquet +2 -2
- models/subword_ngram/ang_4gram_subword.parquet +2 -2
- models/subword_ngram/ang_5gram_subword.parquet +2 -2
- models/tokenizer/ang_tokenizer_16k.model +1 -1
- models/tokenizer/ang_tokenizer_32k.model +1 -1
- models/tokenizer/ang_tokenizer_64k.model +1 -1
- models/tokenizer/ang_tokenizer_8k.model +1 -1
- models/word_markov/ang_markov_ctx1_word.parquet +2 -2
- models/word_markov/ang_markov_ctx2_word.parquet +2 -2
- models/word_markov/ang_markov_ctx3_word.parquet +2 -2
- models/word_markov/ang_markov_ctx4_word.parquet +2 -2
- models/word_ngram/ang_2gram_word.parquet +2 -2
- models/word_ngram/ang_3gram_word.parquet +2 -2
- models/word_ngram/ang_4gram_word.parquet +2 -2
- models/word_ngram/ang_5gram_word.parquet +2 -2
- visualizations/embedding_alignment_quality.png +0 -0
- visualizations/embedding_isotropy.png +0 -0
- visualizations/embedding_norms.png +0 -0
- visualizations/embedding_similarity.png +2 -2
- visualizations/embedding_tsne_multilingual.png +2 -2
- visualizations/ngram_perplexity.png +0 -0
- visualizations/performance_dashboard.png +2 -2
- visualizations/position_encoding_comparison.png +2 -2
- visualizations/tsne_sentences.png +2 -2
- visualizations/tsne_words.png +2 -2
README.md
CHANGED
|
@@ -36,7 +36,7 @@ metrics:
|
|
| 36 |
value: 4.012
|
| 37 |
- name: best_isotropy
|
| 38 |
type: isotropy
|
| 39 |
-
value: 0.
|
| 40 |
- name: vocabulary_size
|
| 41 |
type: vocab
|
| 42 |
value: 0
|
|
@@ -99,32 +99,32 @@ We analyze tokenizers, n-gram models, Markov chains, vocabulary statistics, and
|
|
| 99 |
|
| 100 |
Below are sample sentences tokenized with each vocabulary size:
|
| 101 |
|
| 102 |
-
**Sample 1:** `
|
| 103 |
|
| 104 |
| Vocab | Tokens | Count |
|
| 105 |
|-------|--------|-------|
|
| 106 |
-
| 8k | `▁
|
| 107 |
-
| 16k | `▁
|
| 108 |
-
| 32k | `▁
|
| 109 |
-
| 64k | `▁
|
| 110 |
|
| 111 |
-
**Sample 2:** `
|
| 112 |
|
| 113 |
| Vocab | Tokens | Count |
|
| 114 |
|-------|--------|-------|
|
| 115 |
-
| 8k | `▁
|
| 116 |
-
| 16k | `▁
|
| 117 |
-
| 32k | `▁
|
| 118 |
-
| 64k | `▁
|
| 119 |
|
| 120 |
-
**Sample 3:** `
|
| 121 |
|
| 122 |
| Vocab | Tokens | Count |
|
| 123 |
|-------|--------|-------|
|
| 124 |
-
| 8k | `▁
|
| 125 |
-
| 16k | `▁
|
| 126 |
-
| 32k | `▁
|
| 127 |
-
| 64k | `▁
|
| 128 |
|
| 129 |
|
| 130 |
### Key Findings
|
|
@@ -274,27 +274,27 @@ Below are text samples generated from each word-based Markov chain model:
|
|
| 274 |
|
| 275 |
**Context Size 1:**
|
| 276 |
|
| 277 |
-
1. `and
|
| 278 |
-
2. `on
|
| 279 |
-
3. `is
|
| 280 |
|
| 281 |
**Context Size 2:**
|
| 282 |
|
| 283 |
-
1. `on þǣm
|
| 284 |
-
2. `in þǣm
|
| 285 |
-
3. `in þæm
|
| 286 |
|
| 287 |
**Context Size 3:**
|
| 288 |
|
| 289 |
-
1. `td valign top
|
| 290 |
-
2. `is þorp in
|
| 291 |
-
3. `eoferwicscīre þæs geānedan cynerīces
|
| 292 |
|
| 293 |
**Context Size 4:**
|
| 294 |
|
| 295 |
1. `on eoferwicscīre þæs geānedan cynerīces`
|
| 296 |
-
2. `is eoferƿicscire dǣl on
|
| 297 |
-
3. `eoferƿicscire dǣl on englum
|
| 298 |
|
| 299 |
|
| 300 |
### Generated Text Samples (Subword-based)
|
|
@@ -303,27 +303,27 @@ Below are text samples generated from each subword-based Markov chain model:
|
|
| 303 |
|
| 304 |
**Context Size 1:**
|
| 305 |
|
| 306 |
-
1. `
|
| 307 |
-
2. `
|
| 308 |
-
3. `
|
| 309 |
|
| 310 |
**Context Size 2:**
|
| 311 |
|
| 312 |
-
1. `
|
| 313 |
-
2. `
|
| 314 |
-
3. `
|
| 315 |
|
| 316 |
**Context Size 3:**
|
| 317 |
|
| 318 |
-
1. `
|
| 319 |
-
2. `
|
| 320 |
-
3. `
|
| 321 |
|
| 322 |
**Context Size 4:**
|
| 323 |
|
| 324 |
-
1. `
|
| 325 |
-
2. `
|
| 326 |
-
3. `
|
| 327 |
|
| 328 |
|
| 329 |
### Key Findings
|
|
@@ -428,18 +428,18 @@ Below are text samples generated from each subword-based Markov chain model:
|
|
| 428 |
|
| 429 |
| Model | Dimension | Isotropy | Semantic Density | Alignment R@1 | Alignment R@10 |
|
| 430 |
|-------|-----------|----------|------------------|---------------|----------------|
|
| 431 |
-
| **mono_32d** | 32 | 0.
|
| 432 |
-
| **mono_64d** | 64 | 0.
|
| 433 |
-
| **mono_128d** | 128 | 0.
|
| 434 |
-
| **aligned_32d** | 32 | 0.
|
| 435 |
-
| **aligned_64d** | 64 | 0.
|
| 436 |
-
| **aligned_128d** | 128 | 0.
|
| 437 |
|
| 438 |
### Key Findings
|
| 439 |
|
| 440 |
-
- **Best Isotropy:**
|
| 441 |
-
- **Semantic Density:** Average pairwise similarity of 0.
|
| 442 |
-
- **Alignment Quality:** Aligned models achieve up to 8
|
| 443 |
- **Recommendation:** 128d aligned for best cross-lingual performance
|
| 444 |
|
| 445 |
---
|
|
@@ -461,17 +461,19 @@ These are the most productive prefixes and suffixes identified by sampling the v
|
|
| 461 |
#### Productive Prefixes
|
| 462 |
| Prefix | Examples |
|
| 463 |
|--------|----------|
|
| 464 |
-
| `-ge` |
|
| 465 |
|
| 466 |
#### Productive Suffixes
|
| 467 |
| Suffix | Examples |
|
| 468 |
|--------|----------|
|
| 469 |
-
| `-e` |
|
| 470 |
-
| `-
|
| 471 |
-
| `-es` |
|
| 472 |
-
| `-
|
| 473 |
-
| `-
|
| 474 |
-
| `-
|
|
|
|
|
|
|
| 475 |
|
| 476 |
### 6.3 Bound Stems (Lexical Roots)
|
| 477 |
|
|
@@ -479,18 +481,18 @@ Bound stems are high-frequency subword units that are semantically cohesive but
|
|
| 479 |
|
| 480 |
| Stem | Cohesion | Substitutability | Examples |
|
| 481 |
|------|----------|------------------|----------|
|
| 482 |
-
| `
|
| 483 |
-
| `
|
| 484 |
-
| `
|
| 485 |
-
| `
|
| 486 |
-
| `unge` | 1.
|
| 487 |
-
| `tion` | 2.
|
| 488 |
-
| `inga` | 1.
|
| 489 |
-
| `ning` | 1.
|
| 490 |
-
| `aste` | 1.
|
| 491 |
-
| `ynin` | 2.
|
| 492 |
-
| `afod` | 1.
|
| 493 |
-
| `nisc` | 1.
|
| 494 |
|
| 495 |
### 6.4 Affix Compatibility (Co-occurrence)
|
| 496 |
|
|
@@ -498,12 +500,14 @@ This table shows which prefixes and suffixes most frequently co-occur on the sam
|
|
| 498 |
|
| 499 |
| Prefix | Suffix | Frequency | Examples |
|
| 500 |
|--------|--------|-----------|----------|
|
| 501 |
-
| `-ge` | `-e` |
|
| 502 |
-
| `-ge` | `-
|
| 503 |
-
| `-ge` | `-
|
| 504 |
-
| `-ge` | `-
|
| 505 |
-
| `-ge` | `-
|
| 506 |
-
| `-ge` | `-
|
|
|
|
|
|
|
| 507 |
|
| 508 |
### 6.5 Recursive Morpheme Segmentation
|
| 509 |
|
|
@@ -511,21 +515,21 @@ Using **Recursive Hierarchical Substitutability**, we decompose complex words in
|
|
| 511 |
|
| 512 |
| Word | Suggested Split | Confidence | Stem |
|
| 513 |
|------|-----------------|------------|------|
|
| 514 |
-
|
|
| 515 |
-
|
|
| 516 |
-
|
|
| 517 |
-
|
|
| 518 |
-
|
|
| 519 |
-
|
|
| 520 |
-
|
|
| 521 |
-
|
|
| 522 |
-
|
|
| 523 |
-
|
|
| 524 |
-
|
|
| 525 |
-
|
|
| 526 |
-
|
|
| 527 |
-
|
|
| 528 |
-
|
|
| 529 |
|
| 530 |
### 6.6 Linguistic Interpretation
|
| 531 |
|
|
@@ -759,4 +763,4 @@ MIT License - Free for academic and commercial use.
|
|
| 759 |
---
|
| 760 |
*Generated by Wikilangs Models Pipeline*
|
| 761 |
|
| 762 |
-
*Report Date: 2026-01-03
|
|
|
|
| 36 |
value: 4.012
|
| 37 |
- name: best_isotropy
|
| 38 |
type: isotropy
|
| 39 |
+
value: 0.7896
|
| 40 |
- name: vocabulary_size
|
| 41 |
type: vocab
|
| 42 |
value: 0
|
|
|
|
| 99 |
|
| 100 |
Below are sample sentences tokenized with each vocabulary size:
|
| 101 |
|
| 102 |
+
**Sample 1:** `Grēat Coldūn () is þorp in þæm East Þriding, se is Eoferƿicscire dǣl, on Englum....`
|
| 103 |
|
| 104 |
| Vocab | Tokens | Count |
|
| 105 |
|-------|--------|-------|
|
| 106 |
+
| 8k | `▁grēat ▁c old ūn ▁() ▁is ▁þorp ▁in ▁þæm ▁east ... (+15 more)` | 25 |
|
| 107 |
+
| 16k | `▁grēat ▁c old ūn ▁() ▁is ▁þorp ▁in ▁þæm ▁east ... (+15 more)` | 25 |
|
| 108 |
+
| 32k | `▁grēat ▁cold ūn ▁() ▁is ▁þorp ▁in ▁þæm ▁east ▁þriding ... (+14 more)` | 24 |
|
| 109 |
+
| 64k | `▁grēat ▁cold ūn ▁() ▁is ▁þorp ▁in ▁þæm ▁east ▁þriding ... (+14 more)` | 24 |
|
| 110 |
|
| 111 |
+
**Sample 2:** `Lingua Franca Nova is gehugod sprǣc. Utweardlice bendas elefen.org gereord`
|
| 112 |
|
| 113 |
| Vocab | Tokens | Count |
|
| 114 |
|-------|--------|-------|
|
| 115 |
+
| 8k | `▁l ing ua ▁franc a ▁nov a ▁is ▁geh ug ... (+11 more)` | 21 |
|
| 116 |
+
| 16k | `▁l ing ua ▁franc a ▁nova ▁is ▁geh ug od ... (+10 more)` | 20 |
|
| 117 |
+
| 32k | `▁ling ua ▁franca ▁nova ▁is ▁gehugod ▁sprǣc . ▁utweardlice ▁bendas ... (+5 more)` | 15 |
|
| 118 |
+
| 64k | `▁lingua ▁franca ▁nova ▁is ▁gehugod ▁sprǣc . ▁utweardlice ▁bendas ▁ele ... (+4 more)` | 14 |
|
| 119 |
|
| 120 |
+
**Sample 3:** `Andreas Iǣxcūn ƿæs se seofoða Foresittend þāra Geānlǣhtra Rīca, fram þǣm gēare ō...`
|
| 121 |
|
| 122 |
| Vocab | Tokens | Count |
|
| 123 |
|-------|--------|-------|
|
| 124 |
+
| 8k | `▁andreas ▁i ǣ x c ūn ▁ƿæs ▁se ▁seof oða ... (+17 more)` | 27 |
|
| 125 |
+
| 16k | `▁andreas ▁iǣx c ūn ▁ƿæs ▁se ▁seofoða ▁foresittend ▁þāra ▁geānlǣhtra ... (+14 more)` | 24 |
|
| 126 |
+
| 32k | `▁andreas ▁iǣx c ūn ▁ƿæs ▁se ▁seofoða ▁foresittend ▁þāra ▁geānlǣhtra ... (+14 more)` | 24 |
|
| 127 |
+
| 64k | `▁andreas ▁iǣxcūn ▁ƿæs ▁se ▁seofoða ▁foresittend ▁þāra ▁geānlǣhtra ▁rīca , ... (+12 more)` | 22 |
|
| 128 |
|
| 129 |
|
| 130 |
### Key Findings
|
|
|
|
| 274 |
|
| 275 |
**Context Size 1:**
|
| 276 |
|
| 277 |
+
1. `and bedældede hine in þǣm geānedum rīcum þā protest sang rocc and sīþe hrēðcyninges hām to`
|
| 278 |
+
2. `on francum in þæm miclum burgum and his ƿæter hit hê hê willgesweostor shes laid back`
|
| 279 |
+
3. `is unesco æfter déaðe drepe þrōƿade heorosƿeng heardn ond sēo hēafodmearc iesuitisces rǣses it was f...`
|
| 280 |
|
| 281 |
**Context Size 2:**
|
| 282 |
|
| 283 |
+
1. `on þǣm fylle þǣm þe nāhwæþer ne þā ġeānedan land sculon ne ǣniġ land sceal ætfōn oþþe`
|
| 284 |
+
2. `in þǣm indiscum lande uttar pradesh þæt land þæt ƿæs corēan independence activist politicians and jo...`
|
| 285 |
+
3. `in þæm east þriding se is eoferƿicscire dǣl on englum hit hæfþ 11 351 būendas on eoferwicscīre`
|
| 286 |
|
| 287 |
**Context Size 3:**
|
| 288 |
|
| 289 |
+
1. `td valign top ualentinianus ii td valign top td to 297 td valign top co emperor with honorius`
|
| 290 |
+
2. `is þorp in soria on castile and leóne in spēonlande and þorpas on sorie`
|
| 291 |
+
3. `eoferwicscīre þæs geānedan cynerīces and hēafodman þæs behealdenda hēapes siþðan mǣdmōnaþ he is gebē...`
|
| 292 |
|
| 293 |
**Context Size 4:**
|
| 294 |
|
| 295 |
1. `on eoferwicscīre þæs geānedan cynerīces`
|
| 296 |
+
2. `is eoferƿicscire dǣl on englalande on eoferwicscīre þæs geānedan cynerīces`
|
| 297 |
+
3. `eoferƿicscire dǣl on englum mid grēatum hǣþfelda ġesċieppaþ hie þone burgsċipe of hǣþfelda on eoferw...`
|
| 298 |
|
| 299 |
|
| 300 |
### Generated Text Samples (Subword-based)
|
|
|
|
| 303 |
|
| 304 |
**Context Size 1:**
|
| 305 |
|
| 306 |
+
1. `_htofunes_anōre_`
|
| 307 |
+
2. `e_c_weaþǣfyn_sca`
|
| 308 |
+
3. `n_þeal_wun_berie`
|
| 309 |
|
| 310 |
**Context Size 2:**
|
| 311 |
|
| 312 |
+
1. `e_of_fi_94oðbe_tw`
|
| 313 |
+
2. `an_thoseadand_īeg`
|
| 314 |
+
3. `n_nīƿ_mesprytt,_þ`
|
| 315 |
|
| 316 |
**Context Size 3:**
|
| 317 |
|
| 318 |
+
1. `and_und_ofher_mā_s`
|
| 319 |
+
2. `nd_titutede_him._h`
|
| 320 |
+
3. `an_asscran_betwa_ǣ`
|
| 321 |
|
| 322 |
**Context Size 4:**
|
| 323 |
|
| 324 |
+
1. `and_belalan_(mother`
|
| 325 |
+
2. `_and_ġecosta_tƿiste`
|
| 326 |
+
3. `_on_þā_habbað_nofgo`
|
| 327 |
|
| 328 |
|
| 329 |
### Key Findings
|
|
|
|
| 428 |
|
| 429 |
| Model | Dimension | Isotropy | Semantic Density | Alignment R@1 | Alignment R@10 |
|
| 430 |
|-------|-----------|----------|------------------|---------------|----------------|
|
| 431 |
+
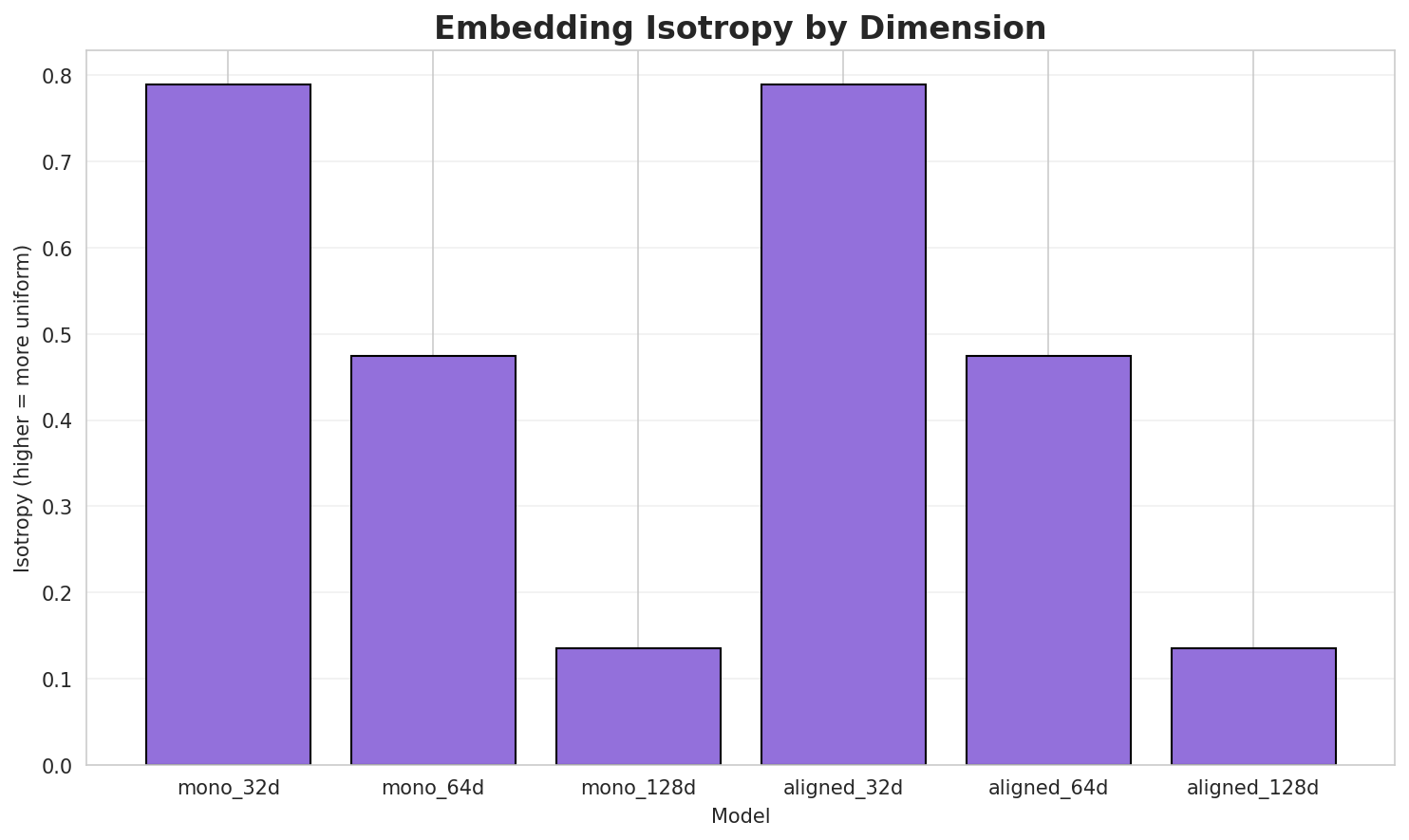
| **mono_32d** | 32 | 0.7896 | 0.3585 | N/A | N/A |
|
| 432 |
+
| **mono_64d** | 64 | 0.4746 | 0.3175 | N/A | N/A |
|
| 433 |
+
| **mono_128d** | 128 | 0.1353 | 0.3004 | N/A | N/A |
|
| 434 |
+
| **aligned_32d** | 32 | 0.7896 🏆 | 0.3555 | 0.0300 | 0.2480 |
|
| 435 |
+
| **aligned_64d** | 64 | 0.4746 | 0.3090 | 0.0860 | 0.3400 |
|
| 436 |
+
| **aligned_128d** | 128 | 0.1353 | 0.3041 | 0.1280 | 0.4020 |
|
| 437 |
|
| 438 |
### Key Findings
|
| 439 |
|
| 440 |
+
- **Best Isotropy:** aligned_32d with 0.7896 (more uniform distribution)
|
| 441 |
+
- **Semantic Density:** Average pairwise similarity of 0.3242. Lower values indicate better semantic separation.
|
| 442 |
+
- **Alignment Quality:** Aligned models achieve up to 12.8% R@1 in cross-lingual retrieval.
|
| 443 |
- **Recommendation:** 128d aligned for best cross-lingual performance
|
| 444 |
|
| 445 |
---
|
|
|
|
| 461 |
#### Productive Prefixes
|
| 462 |
| Prefix | Examples |
|
| 463 |
|--------|----------|
|
| 464 |
+
| `-ge` | geondrīcisce, gebold, gemyndgung |
|
| 465 |
|
| 466 |
#### Productive Suffixes
|
| 467 |
| Suffix | Examples |
|
| 468 |
|--------|----------|
|
| 469 |
+
| `-e` | ārwurðnysse, cǣġe, farende |
|
| 470 |
+
| `-s` | celebrations, villages, annivs |
|
| 471 |
+
| `-es` | villages, ides, missiles |
|
| 472 |
+
| `-an` | þēodacynewīsan, hāligan, europiscan |
|
| 473 |
+
| `-um` | dorsætum, maniȝum, elpendum |
|
| 474 |
+
| `-de` | farende, ungeƿilde, bestandende |
|
| 475 |
+
| `-en` | ƿriten, eċġen, hyrneġen |
|
| 476 |
+
| `-on` | edmonton, huffington, aragon |
|
| 477 |
|
| 478 |
### 6.3 Bound Stems (Lexical Roots)
|
| 479 |
|
|
|
|
| 481 |
|
| 482 |
| Stem | Cohesion | Substitutability | Examples |
|
| 483 |
|------|----------|------------------|----------|
|
| 484 |
+
| `enne` | 2.04x | 48 contexts | fenne, etenne, cenneþ |
|
| 485 |
+
| `mani` | 2.03x | 43 contexts | amani, maniȝ, maniġ |
|
| 486 |
+
| `wear` | 1.91x | 43 contexts | wearð, wearg, weard |
|
| 487 |
+
| `ster` | 1.67x | 59 contexts | sister, ēaster, faster |
|
| 488 |
+
| `unge` | 1.77x | 46 contexts | tunge, tunges, jungen |
|
| 489 |
+
| `tion` | 2.19x | 19 contexts | motion, nation, action |
|
| 490 |
+
| `inga` | 1.72x | 34 contexts | þinga, minga, ðinga |
|
| 491 |
+
| `ning` | 1.64x | 35 contexts | mining, cining, cyning |
|
| 492 |
+
| `aste` | 1.69x | 27 contexts | taste, easte, ēaste |
|
| 493 |
+
| `ynin` | 2.21x | 11 contexts | cynin, cyning, cyninȝ |
|
| 494 |
+
| `afod` | 1.82x | 18 contexts | hēafod, heafod, ƿafode |
|
| 495 |
+
| `nisc` | 1.49x | 27 contexts | rūnisc, denisc, dēnisc |
|
| 496 |
|
| 497 |
### 6.4 Affix Compatibility (Co-occurrence)
|
| 498 |
|
|
|
|
| 500 |
|
| 501 |
| Prefix | Suffix | Frequency | Examples |
|
| 502 |
|--------|--------|-----------|----------|
|
| 503 |
+
| `-ge` | `-e` | 79 words | geƿorhte, geƿǣre |
|
| 504 |
+
| `-ge` | `-en` | 35 words | getimbroden, geferræden |
|
| 505 |
+
| `-ge` | `-de` | 35 words | geanede, gehiersomode |
|
| 506 |
+
| `-ge` | `-s` | 29 words | genus, geardas |
|
| 507 |
+
| `-ge` | `-an` | 20 words | gegildan, gemæccan |
|
| 508 |
+
| `-ge` | `-um` | 20 words | gerādum, germanicum |
|
| 509 |
+
| `-ge` | `-es` | 17 words | geofones, geānlǣhtes |
|
| 510 |
+
| `-ge` | `-on` | 9 words | gestaðoledon, gestrēon |
|
| 511 |
|
| 512 |
### 6.5 Recursive Morpheme Segmentation
|
| 513 |
|
|
|
|
| 515 |
|
| 516 |
| Word | Suggested Split | Confidence | Stem |
|
| 517 |
|------|-----------------|------------|------|
|
| 518 |
+
| gehƿilcum | **`ge-hƿilc-um`** | 6.0 | `hƿilc` |
|
| 519 |
+
| gefeahten | **`ge-feaht-en`** | 6.0 | `feaht` |
|
| 520 |
+
| underbyrigum | **`underbyrig-um`** | 4.5 | `underbyrig` |
|
| 521 |
+
| geþoftscipe | **`ge-þoftscipe`** | 4.5 | `þoftscipe` |
|
| 522 |
+
| sanghordes | **`sanghord-es`** | 4.5 | `sanghord` |
|
| 523 |
+
| gesweoster | **`ge-sweoster`** | 4.5 | `sweoster` |
|
| 524 |
+
| russlandes | **`russland-es`** | 4.5 | `russland` |
|
| 525 |
+
| þēodisclandes | **`þēodiscland-es`** | 4.5 | `þēodiscland` |
|
| 526 |
+
| gestrēonum | **`ge-strē-on-um`** | 4.5 | `strē` |
|
| 527 |
+
| drȳġelandes | **`drȳġeland-es`** | 4.5 | `drȳġeland` |
|
| 528 |
+
| drēamhordes | **`drēamhord-es`** | 4.5 | `drēamhord` |
|
| 529 |
+
| andweardum | **`andweard-um`** | 4.5 | `andweard` |
|
| 530 |
+
| engliscan | **`englisc-an`** | 4.5 | `englisc` |
|
| 531 |
+
| stǣrlican | **`stǣrlic-an`** | 4.5 | `stǣrlic` |
|
| 532 |
+
| bedæleden | **`bedæled-en`** | 4.5 | `bedæled` |
|
| 533 |
|
| 534 |
### 6.6 Linguistic Interpretation
|
| 535 |
|
|
|
|
| 763 |
---
|
| 764 |
*Generated by Wikilangs Models Pipeline*
|
| 765 |
|
| 766 |
+
*Report Date: 2026-01-03 16:22:13*
|
models/embeddings/aligned/ang_128d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1034408961
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4042fcd252c39668ffd282b54a7959049dca6a2fa2494d370faeffe4781a8f96
|
| 3 |
size 1034408961
|
models/embeddings/aligned/ang_128d.projection.npy
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 65664
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8cef629d215fae2a8d4f6d0757920e964a035b8e6ddc4ce58bc93bd2a48cd3ee
|
| 3 |
size 65664
|
models/embeddings/aligned/ang_32d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 258728193
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7386137c71165a0deab23014e63a9dab73ec6a8ba0a1f42c0ee53ddb3189b496
|
| 3 |
size 258728193
|
models/embeddings/aligned/ang_32d.projection.npy
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4224
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0ccb3f646a1f22afcafedaa07234038b8eb0a81333e2639d062d8e005227b599
|
| 3 |
size 4224
|
models/embeddings/aligned/ang_64d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 517288449
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:43f6d782da9fc3ba7f04cc21fd7e473b4bf33cf249fa39d5f48d9b3fd8683cdd
|
| 3 |
size 517288449
|
models/embeddings/aligned/ang_64d.projection.npy
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 16512
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:32cfa410833fe9bfa29b598a89a4320b14c48b98059aa50a02d59ad523514af2
|
| 3 |
size 16512
|
models/embeddings/monolingual/ang_128d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1034408961
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4042fcd252c39668ffd282b54a7959049dca6a2fa2494d370faeffe4781a8f96
|
| 3 |
size 1034408961
|
models/embeddings/monolingual/ang_32d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 258728193
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7386137c71165a0deab23014e63a9dab73ec6a8ba0a1f42c0ee53ddb3189b496
|
| 3 |
size 258728193
|
models/embeddings/monolingual/ang_64d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 517288449
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:43f6d782da9fc3ba7f04cc21fd7e473b4bf33cf249fa39d5f48d9b3fd8683cdd
|
| 3 |
size 517288449
|
models/subword_markov/ang_markov_ctx1_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a3d0e9296297f8dedcde600098131e69215f012f86ea97793a8e1080e8128c44
|
| 3 |
+
size 66921
|
models/subword_markov/ang_markov_ctx2_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:29bbca0b68aa28374aeeb514ff149d22cae2ccc2374dcc906d83f03a4bc5ba01
|
| 3 |
+
size 365734
|
models/subword_markov/ang_markov_ctx3_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:395c5ce0a7f4fcc034376cb9661ac1b61aa5fe4083f091797c2c5f7a19ac9da3
|
| 3 |
+
size 1376530
|
models/subword_markov/ang_markov_ctx4_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eb6b7720d371619b051d6a22c2b70ac3c30be0259c80a7665e5d7cb3583fd0d2
|
| 3 |
+
size 3782214
|
models/subword_ngram/ang_2gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2c29aed8334b7b6162a0bf48ffc4670ac15eaee132268818982da5a677631114
|
| 3 |
+
size 40739
|
models/subword_ngram/ang_3gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1afdcf65c813b813b9f7167b71a86e2ed39b8472d93eb94894396d88f272f0c9
|
| 3 |
+
size 290617
|
models/subword_ngram/ang_4gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:66b000da624816424df2f6e6a6553cfc1cc8c61a7abb8f07d8a679486bfaecdc
|
| 3 |
+
size 1209861
|
models/subword_ngram/ang_5gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d02d41d0aeffee68af91ecb738ccd5e09afea80746ffbd0c2b4587fe7124c75c
|
| 3 |
+
size 2557033
|
models/tokenizer/ang_tokenizer_16k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 507562
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7acdfd4c40e61701b3c752556981df6787ce11c50ebb3526c7a9fc756f4ad69f
|
| 3 |
size 507562
|
models/tokenizer/ang_tokenizer_32k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 785162
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1b247988006b8533aac3130c934db31dad60edd556804ac0cb222338b7f1a996
|
| 3 |
size 785162
|
models/tokenizer/ang_tokenizer_64k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 1395192
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3e8a3d118894e1a975ad1fff32919ea29007260b0c52dade56cef8a1339ad50e
|
| 3 |
size 1395192
|
models/tokenizer/ang_tokenizer_8k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 372530
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8cda0d4bd94f33872e22279abe24e04c56a98809d2caef495cf50e1306614ba7
|
| 3 |
size 372530
|
models/word_markov/ang_markov_ctx1_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2d984506f93bc12a615d11f8673288f8b486297370aea808062a825b039b007b
|
| 3 |
+
size 2832246
|
models/word_markov/ang_markov_ctx2_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:44a93c0e23326da84f4adfb9922498a0150b7776c64ad13512e2c8cac1f0b09b
|
| 3 |
+
size 5756090
|
models/word_markov/ang_markov_ctx3_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:58b09f9cf4546dfd1942066e7985ab66b49cd7d5de114ab4d137b46a255cb02d
|
| 3 |
+
size 7368188
|
models/word_markov/ang_markov_ctx4_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e5e3d039cc0295413db5595736159f713ab902083e1161c02a9fbebec5add409
|
| 3 |
+
size 8219077
|
models/word_ngram/ang_2gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:53842c7854c682bf6b33d37af0123022da18d7f0a3209576dbc3578b43182725
|
| 3 |
+
size 107141
|
models/word_ngram/ang_3gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b5a29ef33847dff6003ed529dd6a0eeb6991cb931c8c1d52f463c3daeca18c95
|
| 3 |
+
size 110953
|
models/word_ngram/ang_4gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f53e17ffa9d4a1f899d7ed060df75a23e530911203da730f48b1050f37a35fc8
|
| 3 |
+
size 222381
|
models/word_ngram/ang_5gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c9fb9acd2ed808ea08685fbe13baaef8c3a0ebbd981d5dd368178cbd489e818e
|
| 3 |
+
size 165202
|
visualizations/embedding_alignment_quality.png
CHANGED

|

|
visualizations/embedding_isotropy.png
CHANGED

|
|
visualizations/embedding_norms.png
CHANGED

|
|
visualizations/embedding_similarity.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
visualizations/embedding_tsne_multilingual.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
visualizations/ngram_perplexity.png
CHANGED

|

|
visualizations/performance_dashboard.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
visualizations/position_encoding_comparison.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
visualizations/tsne_sentences.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
visualizations/tsne_words.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|