

Submitted by
 akhaliq
akhaliq
akhaliqGet trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
akhaliq
 taesiri
taesiri taesiri
taesiri
 ChrisDing1105
ChrisDing1105
 zengyh1900
zengyh1900 nuojohnchen
nuojohnchen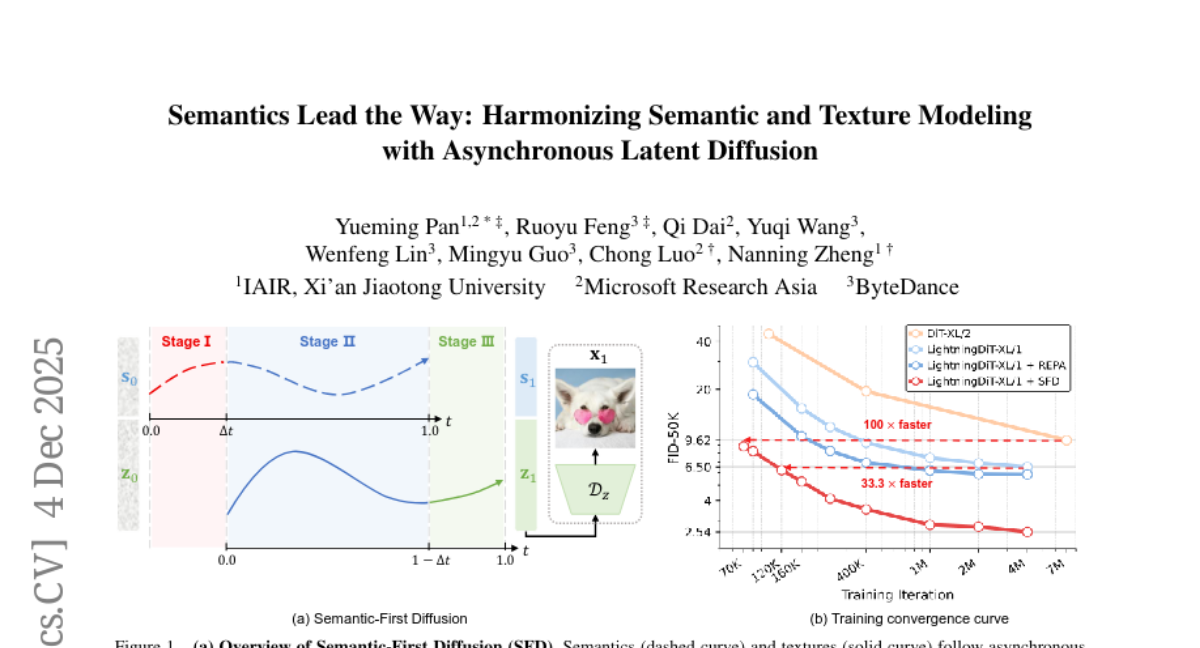
 RuoyuFeng
RuoyuFeng
 Beckham808
Beckham808 kairunwen
kairunwen
 yulunliu
yulunliu
 zhuhz22
zhuhz22 akhaliq
akhaliq taesiri
taesiri taesiri
taesiri
 hba123
hba123
 toshas
toshas
 CaraJ
CaraJ taesiri
taesiri
 HelenMao
HelenMao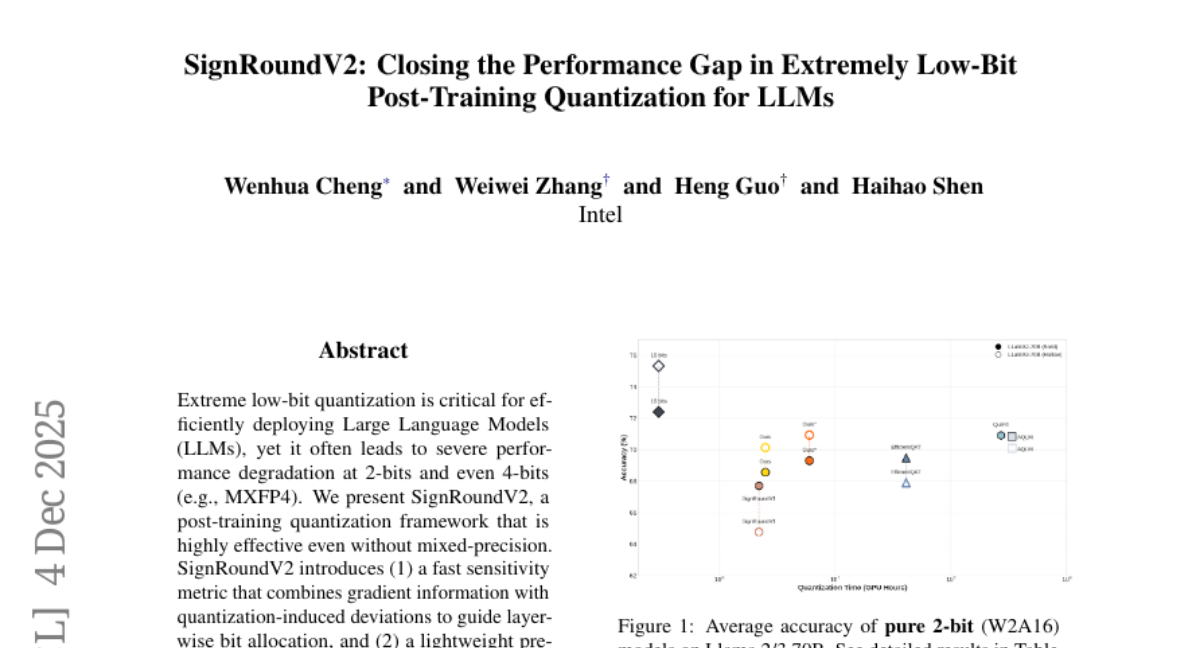
 Haihao
Haihao
 kaipochang0810
kaipochang0810
 ZeqiangLai
ZeqiangLai
 nahyeonkaty
nahyeonkaty
 zichuan-lin
zichuan-lin
 Tianle
Tianle
 YJ-142150
YJ-142150 akhaliq
akhaliq ghyouk
ghyouk SteveZeyuZhang
SteveZeyuZhang
 atsuki-yamaguchi
atsuki-yamaguchi
 dghadiya
dghadiya
 weichium
weichium
 Jim137
Jim137
 melisocal
melisocal
 ChristinaW
ChristinaW
 akhadangi
akhadangi
 danielhzlin
danielhzlin
 XYHan
XYHan























