
add everything but lm eval harness
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +12 -0
- Dockerfile +33 -0
- LICENSE +21 -0
- README.md +328 -3
- data/cached_fineweb100B.py +16 -0
- data/cached_fineweb10B.py +16 -0
- data/cached_finewebedu10B.py +16 -0
- data/fineweb.py +126 -0
- data/requirements.txt +2 -0
- eval.sh +1 -0
- eval_grace.slurm +46 -0
- eval_grace_test.slurm +46 -0
- eval_test.sh +1 -0
- hellaswag.py +285 -0
- img/algo_optimizer.png +3 -0
- img/dofa.jpg +0 -0
- img/fig_optimizer.png +3 -0
- img/fig_tuned_nanogpt.png +3 -0
- img/nanogpt_speedrun51.png +3 -0
- img/nanogpt_speedrun52.png +0 -0
- img/nanogpt_speedrun53.png +3 -0
- img/nanogpt_speedrun54.png +0 -0
- logs/000_c2e7a920-6eca-4f21-8a3c-6022d81a4f29.txt +0 -0
- logs/000_c2e7a920-6eca-4f21-8a3c-6022d81a4f29/hellaswag.json +3 -0
- logs/000_c2e7a920-6eca-4f21-8a3c-6022d81a4f29/hellaswag.yaml +5 -0
- logs/000_c2e7a920-6eca-4f21-8a3c-6022d81a4f29/latest_model.pt +3 -0
- logs/000_c2e7a920-6eca-4f21-8a3c-6022d81a4f29/state_step057344.pt +3 -0
- modded-nanogpt-eval.16715025 +15 -0
- modded-nanogpt-eval.16715025.err +0 -0
- modded-nanogpt-train.16700835 +911 -0
- modded-nanogpt-train.16700835.err +0 -0
- pyproject.toml +19 -0
- records/010425_SoftCap/31d6c427-f1f7-4d8a-91be-a67b5dcd13fd.txt +0 -0
- records/010425_SoftCap/README.md +32 -0
- records/010425_SoftCap/curves_010425.png +3 -0
- records/011325_Fp8LmHead/README.md +1 -0
- records/011325_Fp8LmHead/c51969c2-d04c-40a7-bcea-c092c3c2d11a.txt +0 -0
- records/011625_Sub3Min/1d3bd93b-a69e-4118-aeb8-8184239d7566.txt +0 -0
- records/011625_Sub3Min/README.md +138 -0
- records/011625_Sub3Min/attn-entropy.png +0 -0
- records/011625_Sub3Min/attn-scales-pattern.gif +0 -0
- records/011625_Sub3Min/learned-attn-scales.png +0 -0
- records/011625_Sub3Min/long-short-swa.png +3 -0
- records/011825_GPT2Medium/241dd7a7-3d76-4dce-85a4-7df60387f32a.txt +0 -0
- records/011825_GPT2Medium/main.log +241 -0
- records/012625_BatchSize/0bdd5ee9-ac28-4202-bdf1-c906b102b0ec.txt +0 -0
- records/012625_BatchSize/README.md +38 -0
- records/012625_BatchSize/ablations.png +3 -0
- records/012625_BatchSize/c44090cc-1b99-4c95-8624-38fb4b5834f9.txt +0 -0
- records/012625_BatchSize/val_losses.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,15 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
img/algo_optimizer.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
img/fig_optimizer.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
img/fig_tuned_nanogpt.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
img/nanogpt_speedrun51.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
img/nanogpt_speedrun53.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
logs/000_c2e7a920-6eca-4f21-8a3c-6022d81a4f29/hellaswag.json filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
records/010425_SoftCap/curves_010425.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
records/011625_Sub3Min/long-short-swa.png filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
records/012625_BatchSize/ablations.png filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
records/102924_Optimizers/nanogpt_speedrun81w.png filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
records/102924_Optimizers/nanogpt_speedrun82w.png filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
records/110624_ShortcutsTweaks/nanogpt_speedrun111.png filter=lfs diff=lfs merge=lfs -text
|
Dockerfile
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM nvidia/cuda:12.6.2-cudnn-devel-ubuntu24.04
|
| 2 |
+
|
| 3 |
+
ENV DEBIAN_FRONTEND=noninteractive
|
| 4 |
+
ENV PYTHON_VERSION=3.12.7
|
| 5 |
+
ENV PATH=/usr/local/bin:$PATH
|
| 6 |
+
|
| 7 |
+
RUN apt update && apt install -y --no-install-recommends build-essential libssl-dev zlib1g-dev \
|
| 8 |
+
libbz2-dev libreadline-dev libsqlite3-dev curl git libncursesw5-dev xz-utils tk-dev libxml2-dev \
|
| 9 |
+
libxmlsec1-dev libffi-dev liblzma-dev \
|
| 10 |
+
&& apt clean && rm -rf /var/lib/apt/lists/*
|
| 11 |
+
|
| 12 |
+
RUN curl -O https://www.python.org/ftp/python/${PYTHON_VERSION}/Python-${PYTHON_VERSION}.tgz && \
|
| 13 |
+
tar -xzf Python-${PYTHON_VERSION}.tgz && \
|
| 14 |
+
cd Python-${PYTHON_VERSION} && \
|
| 15 |
+
./configure --enable-optimizations && \
|
| 16 |
+
make -j$(nproc) && \
|
| 17 |
+
make altinstall && \
|
| 18 |
+
cd .. && \
|
| 19 |
+
rm -rf Python-${PYTHON_VERSION} Python-${PYTHON_VERSION}.tgz
|
| 20 |
+
|
| 21 |
+
RUN ln -s /usr/local/bin/python3.12 /usr/local/bin/python && \
|
| 22 |
+
ln -s /usr/local/bin/pip3.12 /usr/local/bin/pip
|
| 23 |
+
|
| 24 |
+
COPY requirements.txt /modded-nanogpt/requirements.txt
|
| 25 |
+
WORKDIR /modded-nanogpt
|
| 26 |
+
|
| 27 |
+
RUN python -m pip install --upgrade pip && \
|
| 28 |
+
pip install -r requirements.txt
|
| 29 |
+
|
| 30 |
+
RUN pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu126 --upgrade
|
| 31 |
+
|
| 32 |
+
CMD ["bash"]
|
| 33 |
+
ENTRYPOINT []
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 Keller Jordan
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,3 +1,328 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Modded-NanoGPT
|
| 2 |
+
|
| 3 |
+
This repository hosts the *NanoGPT speedrun*, in which we (collaboratively|competitively) search for the fastest algorithm to use 8 NVIDIA H100 GPUs to train a language model that attains 3.28 cross-entropy loss on the [FineWeb](https://huggingface.co/datasets/HuggingFaceFW/fineweb) validation set.
|
| 4 |
+
|
| 5 |
+
The target (3.28 validation loss on FineWeb) follows Andrej Karpathy's [GPT-2 replication in llm.c, which attains that loss after running for 45 minutes](https://github.com/karpathy/llm.c/discussions/481#:~:text=By%20the%20end%20of%20the%20optimization%20we%27ll%20get%20to%20about%203.29).
|
| 6 |
+
The speedrun code also descends from llm.c's [PyTorch trainer](https://github.com/karpathy/llm.c/blob/master/train_gpt2.py), which itself descends from NanoGPT, hence the name of the repo.
|
| 7 |
+
Thanks to the efforts of many contributors, this repo now contains a training algorithm which attains the target performance in:
|
| 8 |
+
* 3 minutes on 8xH100 (the llm.c GPT-2 replication needed 45)
|
| 9 |
+
* 0.73B tokens (the llm.c GPT-2 replication needed 10B)
|
| 10 |
+
|
| 11 |
+
This improvement in training speed has been brought about by the following techniques:
|
| 12 |
+
* Modernized architecture: Rotary embeddings, QK-Norm, and ReLU²
|
| 13 |
+
* The Muon optimizer [[writeup](https://kellerjordan.github.io/posts/muon/)] [[repo](https://github.com/KellerJordan/Muon)]
|
| 14 |
+
* Untie head from embedding, use FP8 matmul for head, and softcap logits (the latter following Gemma 2)
|
| 15 |
+
* Initialization of projection and classification layers to zero (muP-like)
|
| 16 |
+
* Skip connections from embedding to every block as well as between blocks in U-net pattern
|
| 17 |
+
* Extra embeddings which are mixed into the values in attention layers (inspired by Zhou et al. 2024)
|
| 18 |
+
* FlexAttention with long-short sliding window attention pattern (inspired by Gemma 2) and window size warmup
|
| 19 |
+
|
| 20 |
+
As well as many systems optimizations.
|
| 21 |
+
|
| 22 |
+
Contributors list (growing with each new record): [@bozavlado](https://x.com/bozavlado); [@brendanh0gan](https://x.com/brendanh0gan);
|
| 23 |
+
[@fernbear.bsky.social](https://bsky.app/profile/fernbear.bsky.social); [@Grad62304977](https://x.com/Grad62304977);
|
| 24 |
+
[@jxbz](https://x.com/jxbz); [@kellerjordan0](https://x.com/kellerjordan0);
|
| 25 |
+
[@KoszarskyB](https://x.com/KoszarskyB); [@leloykun](https://x.com/@leloykun);
|
| 26 |
+
[@YouJiacheng](https://x.com/YouJiacheng); [@jadenj3o](https://x.com/jadenj3o);
|
| 27 |
+
[@KonstantinWilleke](https://github.com/KonstantinWilleke), [@alexrgilbert](https://github.com/alexrgilbert), [@adricarda](https://github.com/adricarda),
|
| 28 |
+
[@tuttyfrutyee](https://github.com/tuttyfrutyee), [@vdlad](https://github.com/vdlad);
|
| 29 |
+
[@ryanyang0](https://x.com/ryanyang0)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
---
|
| 33 |
+
|
| 34 |
+
## Running the current record
|
| 35 |
+
|
| 36 |
+
To run the current record, run the following commands.
|
| 37 |
+
```bash
|
| 38 |
+
git clone https://github.com/KellerJordan/modded-nanogpt.git && cd modded-nanogpt
|
| 39 |
+
pip install -r requirements.txt
|
| 40 |
+
pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu126 --upgrade
|
| 41 |
+
# downloads only the first 800M training tokens to save time
|
| 42 |
+
python data/cached_fineweb10B.py 8
|
| 43 |
+
./run.sh
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
**Note: torch.compile will add around 5 minutes of latency the first time you run the code.**
|
| 47 |
+
|
| 48 |
+
## Alternative: Running with Docker (recommended for precise timing)
|
| 49 |
+
|
| 50 |
+
For cases where CUDA or NCCL versions aren't compatible with your current system setup, Docker can be a helpful alternative.
|
| 51 |
+
This approach standardizes versions for CUDA, NCCL, CUDNN, and Python, reducing dependency issues and simplifying setup.
|
| 52 |
+
Note: an NVIDIA driver must already be installed on the system (useful if only the NVIDIA driver and Docker are available).
|
| 53 |
+
|
| 54 |
+
```bash
|
| 55 |
+
git clone https://github.com/KellerJordan/modded-nanogpt.git && cd modded-nanogpt
|
| 56 |
+
sudo docker build -t modded-nanogpt .
|
| 57 |
+
sudo docker run -it --rm --gpus all -v $(pwd):/modded-nanogpt modded-nanogpt python data/cached_fineweb10B.py 8
|
| 58 |
+
sudo docker run -it --rm --gpus all -v $(pwd):/modded-nanogpt modded-nanogpt sh run.sh
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
To get an interactive docker, you can use
|
| 62 |
+
```bash
|
| 63 |
+
sudo docker run -it --rm --gpus all -v $(pwd):/modded-nanogpt modded-nanogpt bash
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
---
|
| 67 |
+
|
| 68 |
+
## World record history
|
| 69 |
+
|
| 70 |
+
The following is the historical progression of world speed records for the following competitive task:
|
| 71 |
+
|
| 72 |
+
> *Train a neural network to ≤3.28 validation loss on FineWeb using 8x NVIDIA H100s.*
|
| 73 |
+
|
| 74 |
+
Note: The 3.28 target was selected to match [Andrej Karpathy's GPT-2 (small) reproduction](https://github.com/karpathy/llm.c/discussions/481).
|
| 75 |
+
|
| 76 |
+
| # | Record time | Description | Date | Log | Contributors |
|
| 77 |
+
| - | - | - | - | - | - |
|
| 78 |
+
1 | 45 minutes | [llm.c baseline](https://github.com/karpathy/llm.c/discussions/481) | 05/28/24 | [log](records/101324_llmc/main.log) | @karpathy, llm.c contributors
|
| 79 |
+
2 | 31.4 minutes | [Tuned learning rate & rotary embeddings](https://x.com/kellerjordan0/status/1798863559243513937) | 06/06/24 | [log](records/060624_AdamW/f66d43d7-e449-4029-8adf-e8537bab49ea.log) | @kellerjordan0
|
| 80 |
+
3 | 24.9 minutes | [Introduced the Muon optimizer](https://x.com/kellerjordan0/status/1842300916864844014) | 10/04/24 | none | @kellerjordan0, @jxbz
|
| 81 |
+
4 | 22.3 minutes | [Muon improvements](https://x.com/kellerjordan0/status/1844820919061287009) | 10/11/24 | [log](records/101024_Muon/eb5659d0-fb6a-49e5-a311-f1f89412f726.txt) | @kellerjordan0, @bozavlado
|
| 82 |
+
5 | 15.2 minutes | [Pad embeddings, ReLU², zero-init projections, QK-norm](https://x.com/kellerjordan0/status/1845865698532450646) | 10/14/24 | [log](records/101424_ModernArch/dabaaddd-237c-4ec9-939d-6608a9ed5e27.txt) | @Grad62304977, @kellerjordan0
|
| 83 |
+
6 | 13.1 minutes | [Distributed the overhead of Muon](https://x.com/kellerjordan0/status/1847291684016783746) | 10/18/24 | [log](records/101724_DistributedMuon/22d24867-eb5a-4fcc-ae2c-263d0277dfd1.txt) | @kellerjordan0
|
| 84 |
+
7 | 12.0 minutes | [Upgraded PyTorch 2.5.0](https://x.com/kellerjordan0/status/1847358578686152764) | 10/18/24 | [log](records/101824_PyTorch25/d4bfb25f-688d-4da5-8743-33926fad4842.txt) | @kellerjordan0
|
| 85 |
+
8 | 10.8 minutes | [Untied embedding and head](https://x.com/kellerjordan0/status/1853188916704387239) | 11/03/24 | [log](records/110324_UntieEmbed/d6b50d71-f419-4d26-bb39-a60d55ae7a04.txt) | @Grad62304977, @kellerjordan0
|
| 86 |
+
9 | 8.2 minutes | [Value and embedding skip connections, momentum warmup, logit softcap](https://x.com/kellerjordan0/status/1854296101303800108) | 11/06/24 | [log](records/110624_ShortcutsTweaks/dd7304a6-cc43-4d5e-adb8-c070111464a1.txt) | @Grad62304977, @kellerjordan0
|
| 87 |
+
10 | 7.8 minutes | [Bfloat16 activations](https://x.com/kellerjordan0/status/1855267054774865980) | 11/08/24 | [log](records/110824_CastBf16/a833bed8-2fa8-4cfe-af05-58c1cc48bc30.txt) | @kellerjordan0
|
| 88 |
+
11 | 7.2 minutes | [U-net pattern skip connections & double lr](https://x.com/kellerjordan0/status/1856053121103093922) | 11/10/24 | [log](records/111024_UNetDoubleLr/c87bb826-797b-4f37-98c7-d3a5dad2de74.txt) | @brendanh0gan
|
| 89 |
+
12 | 5.03 minutes | [1024-ctx dense causal attention → 64K-ctx FlexAttention](https://x.com/kellerjordan0/status/1859331370268623321) | 11/19/24 | [log](records/111924_FlexAttention/8384493d-dba9-4991-b16b-8696953f5e6d.txt) | @KoszarskyB
|
| 90 |
+
13 | 4.66 minutes | [Attention window warmup](https://x.com/hi_tysam/status/1860851011797053450) | 11/24/24 | [log](records/112424_WindowWarmup/cf9e4571-c5fc-4323-abf3-a98d862ec6c8.txt) | @fernbear.bsky.social
|
| 91 |
+
14 | 4.41 minutes | [Value Embeddings](https://x.com/KoszarskyB/status/1864746625572257852) | 12/04/24 | [log](records/120424_ValueEmbed) | @KoszarskyB
|
| 92 |
+
15 | 3.95 minutes | [U-net pattern value embeddings, assorted code optimizations](https://x.com/YouJiacheng/status/1865761473886347747) | 12/08/24 | [log](records/120824_UNetValueEmbedsTweaks) | @leloykun, @YouJiacheng
|
| 93 |
+
16 | 3.80 minutes | [Split value embeddings, block sliding window, separate block mask](https://x.com/YouJiacheng/status/1866734331559071981) | 12/10/24 | [log](records/121024_MFUTweaks) | @YouJiacheng
|
| 94 |
+
17 | 3.57 minutes | [Sparsify value embeddings, improve rotary embeddings, drop an attn layer](https://x.com/YouJiacheng/status/1868938024731787640) | 12/17/24 | [log](records/121724_SparsifyEmbeds) | @YouJiacheng
|
| 95 |
+
18 | 3.4 minutes | [Lower logit softcap from 30 to 15](https://x.com/kellerjordan0/status/1876048851158880624) | 01/04/25 | [log](records/010425_SoftCap/31d6c427-f1f7-4d8a-91be-a67b5dcd13fd.txt) | @KoszarskyB
|
| 96 |
+
19 | 3.142 minutes | [FP8 head, offset logits, lr decay to 0.1 instead of 0.0](https://x.com/YouJiacheng/status/1878827972519772241) | 01/13/25 | [log](records/011325_Fp8LmHead/c51969c2-d04c-40a7-bcea-c092c3c2d11a.txt) | @YouJiacheng
|
| 97 |
+
20 | 2.992 minutes | [Merged QKV weights, long-short attention, attention scale, lower Adam epsilon, batched Muon](https://x.com/leloykun/status/1880301753213809016) | 01/16/25 | [log](records/011625_Sub3Min/1d3bd93b-a69e-4118-aeb8-8184239d7566.txt) | @leloykun, @fernbear.bsky.social, @YouJiacheng, @brendanh0gan, @scottjmaddox, @Grad62304977
|
| 98 |
+
21 | 2.933 minutes | [Reduced batch size](https://x.com/leloykun/status/1885640350368420160) | 01/26/25 | [log](records/012625_BatchSize/c44090cc-1b99-4c95-8624-38fb4b5834f9.txt) | @leloykun
|
| 99 |
+
21 | 2.997 minutes | 21st record with new timing | 02/01/25 | [log](records/020125_RuleTweak/eff63a8c-2f7e-4fc5-97ce-7f600dae0bc7.txt) | not a new record, just re-timing #21 with the [updated rules](#timing-change-after-record-21)
|
| 100 |
+
21 | 3.014 minutes | 21st record with latest torch | 05/24/25 | [log](records/052425_StableTorch/89d9f224-3b01-4581-966e-358d692335e0.txt) | not a new record, just re-timing #21 with latest torch
|
| 101 |
+
22 | 2.990 minutes | [Faster gradient all-reduce](https://x.com/KonstantinWille/status/1927137223238909969) | 05/24/25 | [log](records/052425_FasterReduce/23f40b75-06fb-4c3f-87a8-743524769a35.txt) | @KonstantinWilleke, @alexrgilbert, @adricarda, @tuttyfrutyee, @vdlad; The Enigma project
|
| 102 |
+
23 | 2.979 minutes | [Overlap computation and gradient communication](https://x.com/kellerjordan0/status/1927460573098262616) | 05/25/25 | [log](records/052525_EvenFasterReduce/6ae86d05-5cb2-4e40-a512-63246fd08e45.txt) | @ryanyang0
|
| 103 |
+
24 | 2.966 minutes | Replace gradient all_reduce with reduce_scatter | 05/30/25 | [log](records/053025_noallreduce/8054c239-3a18-499e-b0c8-dbd27cb4b3ab.txt) | @vagrawal
|
| 104 |
+
25 | 2.896 minutes | Upgrade PyTorch to 2.9.0.dev20250713+cu126 | 07/13/25 | [log](records/071325_UpgradeTorch190/692f80e0-5e64-4819-97d4-0dc83b7106b9.txt ) | @kellerjordan0
|
| 105 |
+
26 | 2.863 minutes | Align training batch starts with EoS, increase cooldown frac to .45 | 07/13/25 | [log](records/071225_BosAlign/c1fd8a38-bb9f-45c4-8af0-d37f70c993f3.txt) | @ClassicLarry
|
| 106 |
+
|
| 107 |
+
## Rules
|
| 108 |
+
|
| 109 |
+
The only rules are that new records must:
|
| 110 |
+
|
| 111 |
+
1. Not modify the train or validation data pipelines. (You can change the batch size, sequence length, attention structure etc.; just don't change the underlying streams of tokens.)
|
| 112 |
+
2. Attain ≤3.28 mean val loss. (Due to inter-run variance, submissions must provide enough run logs to attain a statistical significance level of p<0.01 that their mean val loss is ≤3.28. Example code to compute p-value can be found [here](records/010425_SoftCap#softer-softcap). For submissions which improve speed by optimizing the systems performance, without touching the ML, this requirement is waived.)
|
| 113 |
+
3. Not use any extra `torch._inductor.config` or `torch.compile` flags. (These can save a few seconds, but they can also make compilation take >30min. This rule was introduced after the 21st record.)
|
| 114 |
+
|
| 115 |
+
> Note: `torch._inductor.config.coordinate_descent_tuning` is allowed for GPT-2 Medium track (a.k.a. 2.92 track).
|
| 116 |
+
|
| 117 |
+
Other than that, anything and everything is fair game!
|
| 118 |
+
|
| 119 |
+
[further clarifications](https://github.com/KellerJordan/modded-nanogpt/discussions/23?sort=new#discussioncomment-12109560)
|
| 120 |
+
|
| 121 |
+
---
|
| 122 |
+
|
| 123 |
+
### Comment on the target metric
|
| 124 |
+
|
| 125 |
+
The target metric is *cross-entropy loss on the FineWeb val set*. To speak mathematically, the goal of the speedrun is *to obtain a probability model of language which assigns a probability of at least `math.exp(-3.28 * 10485760)` to the first 10,485,760 tokens of the FineWeb valset. Hence, e.g., we allow evaluation at any sequence length, so long as we still have a valid probability model of language.
|
| 126 |
+
|
| 127 |
+
---
|
| 128 |
+
|
| 129 |
+
### Timing change after record 21
|
| 130 |
+
|
| 131 |
+
After the 21st record, we made two changes to the timing. First, there used to be an initial "grace period" of 10 untimed steps to allow kernel warmup. We replaced this with an explicit kernel-warmup section which is untimed and uses dummy data. This results in an extra runtime of 850ms from the 10 extra timed steps.
|
| 132 |
+
Second, we banned the use of `torch._inductor.config.coordinate_descent_tuning`. This saves ~25min of untimed pre-run compilation, but results in an extra runtime of ~3s.
|
| 133 |
+
|
| 134 |
+
<!--Note: The original llm.c baseline is intended to be closer to a replication of GPT-2 than to an optimized LLM training.
|
| 135 |
+
So it's no surprise that there is room to improve; as @karpathy has said, 'llm.c still has a lot of pending optimizations.'
|
| 136 |
+
In addition, many of the techniques used in these records are completely standard, such as rotary embeddings.
|
| 137 |
+
The goal of this benchmark/speedrun is simply to find out which techniques actually work, and maybe come up with some new ones.-->
|
| 138 |
+
<!--The goal of this benchmark is simply to find out all the techniques which actually work, because I'm going crazy reading all these
|
| 139 |
+
LLM training papers
|
| 140 |
+
which claim a huge benefit but then use their own idiosyncratic non-competitive benchmark and therefore no one in the community has any idea if it's legit for months.-->
|
| 141 |
+
<!--[LLM](https://arxiv.org/abs/2305.14342) [training](https://arxiv.org/abs/2402.17764) [papers](https://arxiv.org/abs/2410.01131)-->
|
| 142 |
+
<!--I mean hello??? We're in a completely empirical field; it is insane to not have a benchmark. Ideally everyone uses the same LLM training benchmark,
|
| 143 |
+
and then reviewing LLM training papers becomes as simple as checking if they beat the benchmark. It's not like this would be unprecedented, that's how things
|
| 144 |
+
were in the ImageNet days.
|
| 145 |
+
The only possible 'benefit' I can think of for any empirical field to abandon benchmarks is that it would make it easier to publish false results. Oh, I guess that's why it happened.
|
| 146 |
+
Hilarious to think about how, in the often-commented-upon and ongoing collapse of the peer review system, people blame the *reviewers* --
|
| 147 |
+
yeah, those guys doing free labor who everyone constantly musters all of their intelligence to lie to, it's *their* fault! My bad, you caught me monologuing.-->
|
| 148 |
+
|
| 149 |
+
---
|
| 150 |
+
|
| 151 |
+
### Important note about records 22-25
|
| 152 |
+
|
| 153 |
+
Thanks to the statistical testing of [@agrawal](https://www.github.com/agrawal) (holder of the 24th record), we have learned that records 23, 24, and in all likelihood 22 and 25, actually attain a mean loss of 3.281, which is slightly above the 3.28 target.
|
| 154 |
+
Therefore if we were to completely adhere to the speedrun rules, we would have to deny that these are valid records.
|
| 155 |
+
However, we have decided to leave them in place as valid, because of the following two reasons: (a) the extra loss is most likely my (@kellerjordan0) own fault rather than that of the records, and (b) it is most likely easily addressable.
|
| 156 |
+
|
| 157 |
+
Here's what happened: Records #22 to #25 each change only the systems/implementation of the speedrun.
|
| 158 |
+
Therefore, the requirement to do statistical testing to confirm they hit the target was waived, since in theory they should have hit it automatically, by virtue of the fact that they didn't touch the ML (i.e., they didn't change the architecture, learning rate, etc.).
|
| 159 |
+
|
| 160 |
+
So if these records shouldn't have changed the ML, what explains the regression in val loss?
|
| 161 |
+
We think that most likely, the answer is that this regression was indeed not introduced by any of these records. Instead, it was
|
| 162 |
+
probably caused by my own non-record in which I retimed record #21 with newest torch,
|
| 163 |
+
because in this non-record I also changed the constants used to cast the lm_head to fp8.
|
| 164 |
+
I thought that this change should cause only a (small) strict improvement, but apparently that was not the case.
|
| 165 |
+
|
| 166 |
+
Therefore, it is probable that each of records #22-25 could be easily made fully valid by simply reverting the change I made to those constants.
|
| 167 |
+
Therefore they shall be upheld as valid records.
|
| 168 |
+
|
| 169 |
+
For the future, fortunately record #26 brought the speedrun back into the green in terms of <3.28 loss, so (with high p-value) it should be in a good state now.
|
| 170 |
+
|
| 171 |
+
---
|
| 172 |
+
|
| 173 |
+
### Notable attempts & forks
|
| 174 |
+
|
| 175 |
+
**Notable runs:**
|
| 176 |
+
|
| 177 |
+
* [@alexjc's 01/20/2025 2.77-minute TokenMonster-based record](https://x.com/alexjc/status/1881410039639863622).
|
| 178 |
+
This record is technically outside the rules of the speedrun, since we specified that the train/val tokens must be kept fixed.
|
| 179 |
+
However, it's very interesting, and worth including. The run is not more data-efficient; rather, the speedup comes from the improved tokenizer allowing
|
| 180 |
+
the vocabulary size to be reduced (nearly halved!) while preserving the same bytes-per-token, which saves lots of parameters and FLOPs in the head and embeddings.
|
| 181 |
+
|
| 182 |
+
**Notable forks:**
|
| 183 |
+
* [https://github.com/BlinkDL/modded-nanogpt-rwkv](https://github.com/BlinkDL/modded-nanogpt-rwkv)
|
| 184 |
+
* [https://github.com/nikhilvyas/modded-nanogpt-SOAP](https://github.com/nikhilvyas/modded-nanogpt-SOAP)
|
| 185 |
+
|
| 186 |
+
---
|
| 187 |
+
|
| 188 |
+
## Speedrun track 2: GPT-2 Medium
|
| 189 |
+
|
| 190 |
+
The target loss for this track is lowered from 3.28 to 2.92, as per Andrej Karpathy's 350M-parameter llm.c baseline.
|
| 191 |
+
This baseline generates a model with performance similar to the original GPT-2 Medium, whereas the first track's baseline generates a model on par with GPT-2 Small.
|
| 192 |
+
All other rules remain the same.
|
| 193 |
+
|
| 194 |
+
> Note: `torch._inductor.config.coordinate_descent_tuning` is turned on after the record 6 (*).
|
| 195 |
+
|
| 196 |
+
| # | Record time | Description | Date | Log | Contributors |
|
| 197 |
+
| - | - | - | - | - | - |
|
| 198 |
+
1 | 5.8 hours | [llm.c baseline (350M parameters)](https://github.com/karpathy/llm.c/discussions/481) | 05/28/24 | [log](records/011825_GPT2Medium/main.log) | @karpathy, llm.c contributors
|
| 199 |
+
2 | 29.3 minutes | [Initial record based on scaling up the GPT-2 small track speedrun](https://x.com/kellerjordan0/status/1881959719012847703) | 01/18/25 | [log](records/011825_GPT2Medium/241dd7a7-3d76-4dce-85a4-7df60387f32a.txt) | @kellerjordan0
|
| 200 |
+
3 | 28.1 minutes | [Added standard weight decay](https://x.com/kellerjordan0/status/1888320690543284449) | 02/08/25 | [log](records/020825_GPT2MediumWeightDecay/b01743db-605c-4326-b5b1-d388ee5bebc5.txt) | @kellerjordan0
|
| 201 |
+
4 | 27.7 minutes | [Tuned Muon Newton-Schulz coefficients](https://x.com/leloykun/status/1892793848163946799) | 02/14/25 | [log](records/021425_GPT2MediumOptCoeffs/1baa66b2-bff7-4850-aced-d63885ffb4b6.txt) | @leloykun
|
| 202 |
+
5 | 27.2 minutes | [Increased learning rate cooldown phase duration](records/030625_GPT2MediumLongerCooldown/779c041a-2a37-45d2-a18b-ec0f223c2bb7.txt) | 03/06/25 | [log](records/030625_GPT2MediumLongerCooldown/779c041a-2a37-45d2-a18b-ec0f223c2bb7.txt) | @YouJiacheng
|
| 203 |
+
6 | 25.95 minutes* | [2x MLP wd, qkv norm, all_reduce/opt.step() overlap, optimized skip pattern](https://x.com/YouJiacheng/status/1905861218138804534) | 03/25/25 | [log](records/032525_GPT2MediumArchOptTweaks/train_gpt-20250329.txt) | @YouJiacheng
|
| 204 |
+
7 | 25.29 minutes | [Remove FP8 head; ISRU logits softcap; New sharded mixed precision Muon; merge weights](https://x.com/YouJiacheng/status/1912570883878842527) | 04/16/25 | [log](records/041625_GPT2Medium_Record7/223_3310d0b1-b24d-48ee-899f-d5c2a254a195.txt) | @YouJiacheng
|
| 205 |
+
8 | 24.50 minutes | [Cubic sliding window size schedule, 2× max window size (24.84 minutes)](https://x.com/jadenj3o/status/1914893086276169754) [24.5min repro](https://x.com/YouJiacheng/status/1915667616913645985) | 04/22/25 | [log](records/042225_GPT2Medium_Record8/075_640429f2-e726-4e83-aa27-684626239ffc.txt) | @jadenj3o
|
| 206 |
+
|
| 207 |
+
---
|
| 208 |
+
|
| 209 |
+
### Q: What is the point of NanoGPT speedrunning?
|
| 210 |
+
|
| 211 |
+
A: The officially stated goal of NanoGPT speedrunning is as follows: `gotta go fast`. But for something a little more verbose involving an argument for good benchmarking, here's some kind of manifesto, adorned with a blessing from the master. [https://x.com/karpathy/status/1846790537262571739](https://x.com/karpathy/status/1846790537262571739)
|
| 212 |
+
|
| 213 |
+
### Q: What makes "NanoGPT speedrunning" not just another idiosyncratic benchmark?
|
| 214 |
+
|
| 215 |
+
A: Because it is a *competitive* benchmark. In particular, if you attain a new speed record (using whatever method you want), there is an open invitation for you
|
| 216 |
+
to post that record (on arXiv or X) and thereby vacuum up all the clout for yourself. I will even help you do it by reposting you as much as I can.
|
| 217 |
+
|
| 218 |
+
<!--On the contrary, for example, the benchmark used in the [Sophia](https://arxiv.org/abs/2305.14342) paper does *not* have this property.
|
| 219 |
+
There is no such open invitation for anyone to compete on the benchmark they used. In particular, if, for a random and definitely not weirdly specific example, you happen to find better AdamW hyperparameters for their training setup than
|
| 220 |
+
the ones they used which significantly close the gap between AdamW and their proposed optimizer,
|
| 221 |
+
then there is no clear path for you to publish that result in *any* form.
|
| 222 |
+
You could try posting it on X.com, but then you would be risking being perceived as aggressive/confrontational, which is *not a good look* in this racket.
|
| 223 |
+
So if you're rational, the result probably just dies with you and no one else learns anything
|
| 224 |
+
(unless you're in a frontier lab, in which case you can do a nice internal writeup. Boy I'd love to get my hands on those writeups).-->
|
| 225 |
+
|
| 226 |
+
["Artificial intelligence advances by inventing games and gloating to goad others to play" - Professor Ben Recht](https://www.argmin.net/p/too-much-information)
|
| 227 |
+
|
| 228 |
+
### Q: NanoGPT speedrunning is cool and all, but meh it probably won't scale and is just overfitting to val loss
|
| 229 |
+
|
| 230 |
+
A: This is hard to refute, since "at scale" is an infinite category (what if the methods stop working only for >100T models?), making it impossible to fully prove.
|
| 231 |
+
Also, I would agree that some of the methods used in the speedrun are unlikely to scale, particularly those which *impose additional structure* on the network, such as logit softcapping.
|
| 232 |
+
But if the reader cares about 1.5B models, they might be convinced by this result:
|
| 233 |
+
|
| 234 |
+
*Straightforwardly scaling up the speedrun (10/18/24 version) to 1.5B parameters yields a model with GPT-2 (1.5B)-level HellaSwag performance 2.5x more cheaply than [@karpathy's baseline](https://github.com/karpathy/llm.c/discussions/677) ($233 instead of $576):*
|
| 235 |
+
|
| 236 |
+

|
| 237 |
+
[[reproducible log](https://github.com/KellerJordan/modded-nanogpt/blob/master/records/102024_ScaleUp1B/ad8d7ae5-7b2d-4ee9-bc52-f912e9174d7a.txt)]
|
| 238 |
+

|
| 239 |
+
|
| 240 |
+
---
|
| 241 |
+
|
| 242 |
+
## [Muon optimizer](https://github.com/KellerJordan/Muon)
|
| 243 |
+
|
| 244 |
+
Muon is defined as follows:
|
| 245 |
+
|
| 246 |
+

|
| 247 |
+
|
| 248 |
+
Where NewtonSchulz5 is the following Newton-Schulz iteration [2, 3], which approximately replaces `G` with `U @ V.T` where `U, S, V = G.svd()`.
|
| 249 |
+
```python
|
| 250 |
+
@torch.compile
|
| 251 |
+
def zeroth_power_via_newtonschulz5(G, steps=5, eps=1e-7):
|
| 252 |
+
assert len(G.shape) == 2
|
| 253 |
+
a, b, c = (3.4445, -4.7750, 2.0315)
|
| 254 |
+
X = G.bfloat16() / (G.norm() + eps)
|
| 255 |
+
if G.size(0) > G.size(1):
|
| 256 |
+
X = X.T
|
| 257 |
+
for _ in range(steps):
|
| 258 |
+
A = X @ X.T
|
| 259 |
+
B = b * A + c * A @ A
|
| 260 |
+
X = a * X + B @ X
|
| 261 |
+
if G.size(0) > G.size(1):
|
| 262 |
+
X = X.T
|
| 263 |
+
return X.to(G.dtype)
|
| 264 |
+
```
|
| 265 |
+
|
| 266 |
+
For this training scenario, Muon has the following favorable properties:
|
| 267 |
+
* Lower memory usage than Adam
|
| 268 |
+
* ~1.5x better sample-efficiency
|
| 269 |
+
* <2% wallclock overhead
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
### Provenance
|
| 273 |
+
|
| 274 |
+
Many of the choices made to generate this optimizer were obtained experimentally by our pursuit of [CIFAR-10 speedrunning](https://github.com/KellerJordan/cifar10-airbench).
|
| 275 |
+
In particular, we experimentally obtained the following practices:
|
| 276 |
+
* Using Nesterov momentum inside the update, with orthogonalization applied after momentum.
|
| 277 |
+
* Using a specifically quintic Newton-Schulz iteration as the method of orthogonalization.
|
| 278 |
+
* Using non-convergent coefficients for the quintic polynomial in order to maximize slope at zero, and thereby minimize the number of necessary Newton-Schulz iterations.
|
| 279 |
+
It turns out that the variance doesn't actually matter that much, so we end up with a quintic that rapidly converges to the range 0.68, 1.13 upon repeated application, rather than converging more slowly to 1.
|
| 280 |
+
* Running the Newton-Schulz iteration in bfloat16 (whereas Shampoo implementations often depend on inverse-pth-roots run in fp32 or fp64).
|
| 281 |
+
|
| 282 |
+
Our use of a Newton-Schulz iteration for orthogonalization traces to [Bernstein & Newhouse (2024)](https://arxiv.org/abs/2409.20325),
|
| 283 |
+
who suggested it as a way to compute Shampoo [5, 6] preconditioners, and theoretically explored Shampoo without preconditioner accumulation.
|
| 284 |
+
In particular, Jeremy Bernstein @jxbz sent us the draft, which caused us to experiment with various Newton-Schulz iterations as the
|
| 285 |
+
orthogonalization method for this optimizer.
|
| 286 |
+
If we had used SVD instead of a Newton-Schulz iteration, this optimizer would have been too slow to be useful.
|
| 287 |
+
Bernstein & Newhouse also pointed out that Shampoo without preconditioner accumulation is equivalent to steepest descent in the spectral norm,
|
| 288 |
+
and therefore Shampoo can be thought of as a way to smooth out spectral steepest descent.
|
| 289 |
+
The proposed optimizer can be thought of as a second way of smoothing spectral steepest descent, with a different set of memory and runtime tradeoffs
|
| 290 |
+
compared to Shampoo.
|
| 291 |
+
|
| 292 |
+
---
|
| 293 |
+
|
| 294 |
+
## Running on fewer GPUs
|
| 295 |
+
|
| 296 |
+
* To run experiments on fewer GPUs, simply modify `run.sh` to have a different `--nproc_per_node`. This should not change the behavior of the training.
|
| 297 |
+
* If you're running out of memory, you may need to reduce the sequence length for FlexAttention (which does change the training. see [here](https://github.com/KellerJordan/modded-nanogpt/pull/38) for a guide)
|
| 298 |
+
|
| 299 |
+
---
|
| 300 |
+
|
| 301 |
+
## References
|
| 302 |
+
|
| 303 |
+
1. [Guilherme Penedo et al. "The fineweb datasets: Decanting the web for the finest text data at scale." arXiv preprint arXiv:2406.17557 (2024).](https://arxiv.org/abs/2406.17557)
|
| 304 |
+
2. Nicholas J. Higham. Functions of Matrices. Society for Industrial and Applied Mathematics (2008). Equation 5.22.
|
| 305 |
+
3. Günther Schulz. Iterative Berechnung der reziproken Matrix. Z. Angew. Math. Mech., 13:57â59 (1933).
|
| 306 |
+
4. [Jeremy Bernstein and Laker Newhouse. "Old Optimizer, New Norm: An Anthology." arxiv preprint arXiv:2409.20325 (2024).](https://arxiv.org/abs/2409.20325)
|
| 307 |
+
5. [Vineet Gupta, Tomer Koren, and Yoram Singer. "Shampoo: Preconditioned stochastic tensor optimization." International Conference on Machine Learning. PMLR, 2018.](https://arxiv.org/abs/1802.09568)
|
| 308 |
+
6. [Rohan Anil et al. "Scalable second order optimization for deep learning." arXiv preprint arXiv:2002.09018 (2020).](https://arxiv.org/abs/2002.09018)
|
| 309 |
+
7. [Alexander Hägele et al. "Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations." arXiv preprint arXiv:2405.18392 (2024).](https://arxiv.org/abs/2405.18392)
|
| 310 |
+
8. [Zhanchao Zhou et al. "Value Residual Learning For Alleviating Attention Concentration In Transformers." arXiv preprint arXiv:2410.17897 (2024).](https://arxiv.org/abs/2410.17897)
|
| 311 |
+
9. [Team, Gemma, et al. "Gemma 2: Improving open language models at a practical size." arXiv preprint arXiv:2408.00118 (2024).](https://arxiv.org/abs/2408.00118)
|
| 312 |
+
10. [Alec Radford et al. "Language models are unsupervised multitask learners." OpenAI blog 1.8 (2019).](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
|
| 313 |
+
|
| 314 |
+
## Citation
|
| 315 |
+
|
| 316 |
+
```
|
| 317 |
+
@misc{modded_nanogpt_2024,
|
| 318 |
+
author = {Keller Jordan and Jeremy Bernstein and Brendan Rappazzo and
|
| 319 |
+
@fernbear.bsky.social and Boza Vlado and You Jiacheng and
|
| 320 |
+
Franz Cesista and Braden Koszarsky and @Grad62304977},
|
| 321 |
+
title = {modded-nanogpt: Speedrunning the NanoGPT baseline},
|
| 322 |
+
year = {2024},
|
| 323 |
+
url = {https://github.com/KellerJordan/modded-nanogpt}
|
| 324 |
+
}
|
| 325 |
+
```
|
| 326 |
+
|
| 327 |
+
<img src="img/dofa.jpg" alt="itsover_wereback" style="width:100%;">
|
| 328 |
+
|
data/cached_fineweb100B.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
from huggingface_hub import hf_hub_download
|
| 4 |
+
# Download the GPT-2 tokens of Fineweb100B from huggingface. This
|
| 5 |
+
# saves about an hour of startup time compared to regenerating them.
|
| 6 |
+
def get(fname):
|
| 7 |
+
local_dir = os.path.join(os.path.dirname(__file__), 'fineweb100B')
|
| 8 |
+
if not os.path.exists(os.path.join(local_dir, fname)):
|
| 9 |
+
hf_hub_download(repo_id="kjj0/fineweb100B-gpt2", filename=fname,
|
| 10 |
+
repo_type="dataset", local_dir=local_dir)
|
| 11 |
+
get("fineweb_val_%06d.bin" % 0)
|
| 12 |
+
num_chunks = 1030 # full fineweb100B. Each chunk is 100M tokens
|
| 13 |
+
if len(sys.argv) >= 2: # we can pass an argument to download less
|
| 14 |
+
num_chunks = int(sys.argv[1])
|
| 15 |
+
for i in range(1, num_chunks+1):
|
| 16 |
+
get("fineweb_train_%06d.bin" % i)
|
data/cached_fineweb10B.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
from huggingface_hub import hf_hub_download
|
| 4 |
+
# Download the GPT-2 tokens of Fineweb10B from huggingface. This
|
| 5 |
+
# saves about an hour of startup time compared to regenerating them.
|
| 6 |
+
def get(fname):
|
| 7 |
+
local_dir = os.path.join(os.path.dirname(__file__), 'fineweb10B')
|
| 8 |
+
if not os.path.exists(os.path.join(local_dir, fname)):
|
| 9 |
+
hf_hub_download(repo_id="kjj0/fineweb10B-gpt2", filename=fname,
|
| 10 |
+
repo_type="dataset", local_dir=local_dir)
|
| 11 |
+
get("fineweb_val_%06d.bin" % 0)
|
| 12 |
+
num_chunks = 103 # full fineweb10B. Each chunk is 100M tokens
|
| 13 |
+
if len(sys.argv) >= 2: # we can pass an argument to download less
|
| 14 |
+
num_chunks = int(sys.argv[1])
|
| 15 |
+
for i in range(1, num_chunks+1):
|
| 16 |
+
get("fineweb_train_%06d.bin" % i)
|
data/cached_finewebedu10B.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
from huggingface_hub import hf_hub_download
|
| 4 |
+
# Download the GPT-2 tokens of FinewebEDU10B from huggingface. This
|
| 5 |
+
# saves about an hour of startup time compared to regenerating them.
|
| 6 |
+
def get(fname):
|
| 7 |
+
local_dir = os.path.join(os.path.dirname(__file__), 'finewebedu10B')
|
| 8 |
+
if not os.path.exists(os.path.join(local_dir, fname)):
|
| 9 |
+
hf_hub_download(repo_id="kjj0/finewebedu10B-gpt2", filename=fname,
|
| 10 |
+
repo_type="dataset", local_dir=local_dir)
|
| 11 |
+
get("finewebedu_val_%06d.bin" % 0)
|
| 12 |
+
num_chunks = 99 # full FinewebEDU10B. Each chunk is 100M tokens
|
| 13 |
+
if len(sys.argv) >= 2: # we can pass an argument to download less
|
| 14 |
+
num_chunks = int(sys.argv[1])
|
| 15 |
+
for i in range(1, num_chunks+1):
|
| 16 |
+
get("finewebedu_train_%06d.bin" % i)
|
data/fineweb.py
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
FineWeb dataset (for srs pretraining)
|
| 3 |
+
https://huggingface.co/datasets/HuggingFaceFW/fineweb
|
| 4 |
+
|
| 5 |
+
example doc to highlight the structure of the dataset:
|
| 6 |
+
{
|
| 7 |
+
"text": "Posted by mattsmith on 20th April 2012\nStraight from...",
|
| 8 |
+
"id": "<urn:uuid:d853d453-196e-4488-a411-efc2b26c40d2>",
|
| 9 |
+
"dump": "CC-MAIN-2013-20",
|
| 10 |
+
"url": "http://nleastchatter.com/philliesphandom/tag/freddy-galvis/",
|
| 11 |
+
"date": "2013-05-18T07:24:47Z",
|
| 12 |
+
"file_path": "s3://commoncrawl/long.../path.../file.gz",
|
| 13 |
+
"language": "en",
|
| 14 |
+
"language_score": 0.9185474514961243,
|
| 15 |
+
"token_count": 594
|
| 16 |
+
}
|
| 17 |
+
"""
|
| 18 |
+
import os
|
| 19 |
+
import argparse
|
| 20 |
+
import multiprocessing as mp
|
| 21 |
+
import numpy as np
|
| 22 |
+
import tiktoken
|
| 23 |
+
# from huggingface_hub import snapshot_download
|
| 24 |
+
from datasets import load_dataset
|
| 25 |
+
from tqdm import tqdm
|
| 26 |
+
import argparse
|
| 27 |
+
import numpy as np
|
| 28 |
+
def write_datafile(filename, toks):
|
| 29 |
+
"""
|
| 30 |
+
Saves token data as a .bin file, for reading in C.
|
| 31 |
+
- First comes a header with 256 int32s
|
| 32 |
+
- The tokens follow, each as a uint16
|
| 33 |
+
"""
|
| 34 |
+
assert len(toks) < 2**31, "token count too large" # ~2.1B tokens
|
| 35 |
+
# construct the header
|
| 36 |
+
header = np.zeros(256, dtype=np.int32)
|
| 37 |
+
header[0] = 20240520 # magic
|
| 38 |
+
header[1] = 1 # version
|
| 39 |
+
header[2] = len(toks) # number of tokens after the 256*4 bytes of header (each 2 bytes as uint16)
|
| 40 |
+
# construct the tokens numpy array, if not already
|
| 41 |
+
if not isinstance(toks, np.ndarray) or not toks.dtype == np.uint16:
|
| 42 |
+
# validate that no token exceeds a uint16
|
| 43 |
+
maxtok = 2**16
|
| 44 |
+
assert all(0 <= t < maxtok for t in toks), "token dictionary too large for uint16"
|
| 45 |
+
toks_np = np.array(toks, dtype=np.uint16)
|
| 46 |
+
else:
|
| 47 |
+
toks_np = toks
|
| 48 |
+
# write to file
|
| 49 |
+
print(f"writing {len(toks):,} tokens to {filename}")
|
| 50 |
+
with open(filename, "wb") as f:
|
| 51 |
+
f.write(header.tobytes())
|
| 52 |
+
f.write(toks_np.tobytes())
|
| 53 |
+
# ------------------------------------------
|
| 54 |
+
|
| 55 |
+
parser = argparse.ArgumentParser(description="FineWeb dataset preprocessing")
|
| 56 |
+
parser.add_argument("-v", "--version", type=str, default="10B", help="Which version of fineweb to use 10B|100B")
|
| 57 |
+
parser.add_argument("-s", "--shard_size", type=int, default=10**8, help="Size of each shard in tokens")
|
| 58 |
+
args = parser.parse_args()
|
| 59 |
+
|
| 60 |
+
# FineWeb has a few possible subsamples available
|
| 61 |
+
assert args.version in ["10B", "100B"], "version must be one of 10B, 100B"
|
| 62 |
+
if args.version == "10B":
|
| 63 |
+
local_dir = "fineweb10B"
|
| 64 |
+
remote_name = "sample-10BT"
|
| 65 |
+
elif args.version == "100B":
|
| 66 |
+
local_dir = "fineweb100B"
|
| 67 |
+
remote_name = "sample-100BT"
|
| 68 |
+
|
| 69 |
+
# create the cache the local directory if it doesn't exist yet
|
| 70 |
+
DATA_CACHE_DIR = os.path.join(os.path.dirname(__file__), local_dir)
|
| 71 |
+
os.makedirs(DATA_CACHE_DIR, exist_ok=True)
|
| 72 |
+
|
| 73 |
+
# download the dataset
|
| 74 |
+
fw = load_dataset("HuggingFaceFW/fineweb", name=remote_name, split="train")
|
| 75 |
+
|
| 76 |
+
# init the tokenizer
|
| 77 |
+
enc = tiktoken.get_encoding("gpt2")
|
| 78 |
+
eot = enc._special_tokens['<|endoftext|>'] # end of text token
|
| 79 |
+
def tokenize(doc):
|
| 80 |
+
# tokenizes a single document and returns a numpy array of uint16 tokens
|
| 81 |
+
tokens = [eot] # the special <|endoftext|> token delimits all documents
|
| 82 |
+
tokens.extend(enc.encode_ordinary(doc["text"]))
|
| 83 |
+
tokens_np = np.array(tokens)
|
| 84 |
+
assert (0 <= tokens_np).all() and (tokens_np < 2**16).all(), "token dictionary too large for uint16"
|
| 85 |
+
tokens_np_uint16 = tokens_np.astype(np.uint16)
|
| 86 |
+
return tokens_np_uint16
|
| 87 |
+
|
| 88 |
+
# tokenize all documents and write output shards, each of shard_size tokens (last shard has remainder)
|
| 89 |
+
nprocs = max(1, os.cpu_count() - 2) # don't hog the entire system
|
| 90 |
+
with mp.Pool(nprocs) as pool:
|
| 91 |
+
shard_index = 0
|
| 92 |
+
# preallocate buffer to hold current shard
|
| 93 |
+
all_tokens_np = np.empty((args.shard_size,), dtype=np.uint16)
|
| 94 |
+
token_count = 0
|
| 95 |
+
progress_bar = None
|
| 96 |
+
for tokens in pool.imap(tokenize, fw, chunksize=16):
|
| 97 |
+
|
| 98 |
+
# is there enough space in the current shard for the new tokens?
|
| 99 |
+
if token_count + len(tokens) < args.shard_size:
|
| 100 |
+
# simply append tokens to current shard
|
| 101 |
+
all_tokens_np[token_count:token_count+len(tokens)] = tokens
|
| 102 |
+
token_count += len(tokens)
|
| 103 |
+
# update progress bar
|
| 104 |
+
if progress_bar is None:
|
| 105 |
+
progress_bar = tqdm(total=args.shard_size, unit="tokens", desc=f"Shard {shard_index}")
|
| 106 |
+
progress_bar.update(len(tokens))
|
| 107 |
+
else:
|
| 108 |
+
# write the current shard and start a new one
|
| 109 |
+
split = "val" if shard_index == 0 else "train"
|
| 110 |
+
filename = os.path.join(DATA_CACHE_DIR, f"fineweb_{split}_{shard_index:06d}.bin")
|
| 111 |
+
# split the document into whatever fits in this shard; the remainder goes to next one
|
| 112 |
+
remainder = args.shard_size - token_count
|
| 113 |
+
progress_bar.update(remainder)
|
| 114 |
+
all_tokens_np[token_count:token_count+remainder] = tokens[:remainder]
|
| 115 |
+
write_datafile(filename, all_tokens_np)
|
| 116 |
+
shard_index += 1
|
| 117 |
+
progress_bar = None
|
| 118 |
+
# populate the next shard with the leftovers of the current doc
|
| 119 |
+
all_tokens_np[0:len(tokens)-remainder] = tokens[remainder:]
|
| 120 |
+
token_count = len(tokens)-remainder
|
| 121 |
+
|
| 122 |
+
# write any remaining tokens as the last shard
|
| 123 |
+
if token_count != 0:
|
| 124 |
+
split = "val" if shard_index == 0 else "train"
|
| 125 |
+
filename = os.path.join(DATA_CACHE_DIR, f"fineweb_{split}_{shard_index:06d}.bin")
|
| 126 |
+
write_datafile(filename, all_tokens_np[:token_count])
|
data/requirements.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets
|
| 2 |
+
tiktoken
|
eval.sh
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
uv run hellaswag.py logs DEBUG
|
eval_grace.slurm
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
##NECESSARY JOB SPECIFICATIONS
|
| 4 |
+
#SBATCH --job-name=modded-nanogpt-eval # Set the job name to "get_activations"
|
| 5 |
+
#SBATCH --time=2:00:00 # Set the wall clock limit to 24 hours
|
| 6 |
+
#SBATCH --ntasks=1 # Total number of tasks (processes) across all nodes
|
| 7 |
+
#SBATCH --ntasks-per-node=1 # Number of tasks per node
|
| 8 |
+
#SBATCH --mem=16G # Request 16GB per node
|
| 9 |
+
#SBATCH --output=modded-nanogpt-eval.%j # Send stdout/err to "modded-nanogpt-eval.[jobID]"
|
| 10 |
+
#SBATCH --error=modded-nanogpt-eval.%j.err # Send stderr to separate file
|
| 11 |
+
#SBATCH --gres=gpu:a100:1 # Request 1 a100 per node
|
| 12 |
+
#SBATCH --partition=gpu # Request the GPU partition/queue
|
| 13 |
+
|
| 14 |
+
##OPTIONAL JOB SPECIFICATIONS
|
| 15 |
+
##SBATCH --account=123456 # Set billing account to 123456
|
| 16 |
+
##SBATCH --mail-type=ALL # Send email on all job events
|
| 17 |
+
##SBATCH --mail-user=email_address # Send all emails to email_address
|
| 18 |
+
|
| 19 |
+
# Enable detailed logging
|
| 20 |
+
set -x
|
| 21 |
+
|
| 22 |
+
export MASTER_ADDR=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
|
| 23 |
+
export MASTER_PORT=$(expr 10000 + $(echo -n $SLURM_JOBID | tail -c 4))
|
| 24 |
+
export RANK=$SLURM_PROCID
|
| 25 |
+
export WORLD_SIZE=$SLURM_NTASKS
|
| 26 |
+
|
| 27 |
+
# Print SLURM environment information for debugging
|
| 28 |
+
echo "SLURM Job ID: $SLURM_JOB_ID"
|
| 29 |
+
echo "SLURM Node List: $SLURM_NODELIST"
|
| 30 |
+
echo "SLURM Number of Nodes: $SLURM_NNODES"
|
| 31 |
+
echo "SLURM Number of Tasks: $SLURM_NTASKS"
|
| 32 |
+
echo "SLURM Tasks per Node: $SLURM_NTASKS_PER_NODE"
|
| 33 |
+
echo "SLURM Local ID: $SLURM_LOCALID"
|
| 34 |
+
echo "SLURM Procedure ID: $SLURM_PROCID"
|
| 35 |
+
echo "SLURM Node ID: $SLURM_NODEID"
|
| 36 |
+
echo "MASTER_ADDR: $MASTER_ADDR"
|
| 37 |
+
echo "MASTER_PORT: $MASTER_PORT"
|
| 38 |
+
echo "RANK: $RANK"
|
| 39 |
+
echo "WORLD_SIZE: $WORLD_SIZE"
|
| 40 |
+
echo "CUDA_VISIBLE_DEVICES: $CUDA_VISIBLE_DEVICES"
|
| 41 |
+
|
| 42 |
+
# Change to the project directory
|
| 43 |
+
cd ~/modded-nanogpt
|
| 44 |
+
|
| 45 |
+
# Run the non-distributed job
|
| 46 |
+
./eval.sh
|
eval_grace_test.slurm
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
##NECESSARY JOB SPECIFICATIONS
|
| 4 |
+
#SBATCH --job-name=modded-nanogpt-eval # Set the job name to "get_activations"
|
| 5 |
+
#SBATCH --time=2:00:00 # Set the wall clock limit to 24 hours
|
| 6 |
+
#SBATCH --ntasks=1 # Total number of tasks (processes) across all nodes
|
| 7 |
+
#SBATCH --ntasks-per-node=1 # Number of tasks per node
|
| 8 |
+
#SBATCH --mem=16G # Request 16GB per node
|
| 9 |
+
#SBATCH --output=modded-nanogpt-eval.%j # Send stdout/err to "modded-nanogpt-eval.[jobID]"
|
| 10 |
+
#SBATCH --error=modded-nanogpt-eval.%j.err # Send stderr to separate file
|
| 11 |
+
#SBATCH --gres=gpu:a100:1 # Request 1 a100 per node
|
| 12 |
+
#SBATCH --partition=gpu # Request the GPU partition/queue
|
| 13 |
+
|
| 14 |
+
##OPTIONAL JOB SPECIFICATIONS
|
| 15 |
+
##SBATCH --account=123456 # Set billing account to 123456
|
| 16 |
+
##SBATCH --mail-type=ALL # Send email on all job events
|
| 17 |
+
##SBATCH --mail-user=email_address # Send all emails to email_address
|
| 18 |
+
|
| 19 |
+
# Enable detailed logging
|
| 20 |
+
set -x
|
| 21 |
+
|
| 22 |
+
export MASTER_ADDR=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
|
| 23 |
+
export MASTER_PORT=$(expr 10000 + $(echo -n $SLURM_JOBID | tail -c 4))
|
| 24 |
+
export RANK=$SLURM_PROCID
|
| 25 |
+
export WORLD_SIZE=$SLURM_NTASKS
|
| 26 |
+
|
| 27 |
+
# Print SLURM environment information for debugging
|
| 28 |
+
echo "SLURM Job ID: $SLURM_JOB_ID"
|
| 29 |
+
echo "SLURM Node List: $SLURM_NODELIST"
|
| 30 |
+
echo "SLURM Number of Nodes: $SLURM_NNODES"
|
| 31 |
+
echo "SLURM Number of Tasks: $SLURM_NTASKS"
|
| 32 |
+
echo "SLURM Tasks per Node: $SLURM_NTASKS_PER_NODE"
|
| 33 |
+
echo "SLURM Local ID: $SLURM_LOCALID"
|
| 34 |
+
echo "SLURM Procedure ID: $SLURM_PROCID"
|
| 35 |
+
echo "SLURM Node ID: $SLURM_NODEID"
|
| 36 |
+
echo "MASTER_ADDR: $MASTER_ADDR"
|
| 37 |
+
echo "MASTER_PORT: $MASTER_PORT"
|
| 38 |
+
echo "RANK: $RANK"
|
| 39 |
+
echo "WORLD_SIZE: $WORLD_SIZE"
|
| 40 |
+
echo "CUDA_VISIBLE_DEVICES: $CUDA_VISIBLE_DEVICES"
|
| 41 |
+
|
| 42 |
+
# Change to the project directory
|
| 43 |
+
cd ~/modded-nanogpt
|
| 44 |
+
|
| 45 |
+
# Run the non-distributed job
|
| 46 |
+
./eval_test.sh
|
eval_test.sh
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
uv run hellaswag.py logs DEBUG 100
|
hellaswag.py
ADDED
|
@@ -0,0 +1,285 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import time
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
import yaml
|
| 6 |
+
|
| 7 |
+
print("importing torch...")
|
| 8 |
+
|
| 9 |
+
import arguably
|
| 10 |
+
import torch as th
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
|
| 14 |
+
print("importing lm_eval...")
|
| 15 |
+
|
| 16 |
+
from lm_eval import evaluator
|
| 17 |
+
from lm_eval.models.huggingface import HFLM
|
| 18 |
+
from loguru import logger
|
| 19 |
+
|
| 20 |
+
logger.info("importing transformers...")
|
| 21 |
+
|
| 22 |
+
from transformers import AutoTokenizer, PretrainedConfig, PreTrainedModel
|
| 23 |
+
from transformers.modeling_outputs import CausalLMOutputWithPast
|
| 24 |
+
|
| 25 |
+
logger.info("importing train_gpt_medium...")
|
| 26 |
+
|
| 27 |
+
from train_gpt_medium import (
|
| 28 |
+
GPT,
|
| 29 |
+
args,
|
| 30 |
+
get_window_size_blocks_helper,
|
| 31 |
+
next_multiple_of_n,
|
| 32 |
+
norm,
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class EvaluationGPT(GPT):
|
| 37 |
+
def forward(
|
| 38 |
+
self, input_ids: th.Tensor, labels: th.Tensor | None = None
|
| 39 |
+
) -> CausalLMOutputWithPast:
|
| 40 |
+
assert input_ids.ndim == 2
|
| 41 |
+
assert labels is None or labels.ndim == 2
|
| 42 |
+
if input_ids.dtype not in (th.int32, th.int64):
|
| 43 |
+
logger.warning(f"Input IDs dtype is {input_ids.dtype}, converting to int32")
|
| 44 |
+
input_ids = input_ids.to(dtype=th.int32)
|
| 45 |
+
|
| 46 |
+
if input_ids.device != self.embed.weight.device:
|
| 47 |
+
logger.warning(
|
| 48 |
+
f"Input IDs device is {input_ids.device}, converting to {self.embed.weight.device}"
|
| 49 |
+
)
|
| 50 |
+
input_ids = input_ids.to(device=self.embed.weight.device)
|
| 51 |
+
|
| 52 |
+
input_ids_with_eos_separators = th.cat(
|
| 53 |
+
[
|
| 54 |
+
th.full(
|
| 55 |
+
(input_ids.shape[0], 1),
|
| 56 |
+
50256,
|
| 57 |
+
device=input_ids.device,
|
| 58 |
+
dtype=input_ids.dtype,
|
| 59 |
+
),
|
| 60 |
+
input_ids,
|
| 61 |
+
],
|
| 62 |
+
dim=1,
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
del input_ids
|
| 66 |
+
|
| 67 |
+
num_samples = input_ids_with_eos_separators.shape[0]
|
| 68 |
+
|
| 69 |
+
input_ids_flat_unpadded = input_ids_with_eos_separators.flatten().to(
|
| 70 |
+
device=self.embed.weight.device
|
| 71 |
+
)
|
| 72 |
+
unpadded_len = input_ids_flat_unpadded.shape[0]
|
| 73 |
+
padded_len = next_multiple_of_n(unpadded_len, n=128)
|
| 74 |
+
padding_len = padded_len - unpadded_len
|
| 75 |
+
|
| 76 |
+
input_ids_flat = th.cat(
|
| 77 |
+
[
|
| 78 |
+
input_ids_flat_unpadded,
|
| 79 |
+
th.full(
|
| 80 |
+
(padding_len,),
|
| 81 |
+
50256,
|
| 82 |
+
device=input_ids_flat_unpadded.device,
|
| 83 |
+
dtype=input_ids_flat_unpadded.dtype,
|
| 84 |
+
),
|
| 85 |
+
],
|
| 86 |
+
dim=0,
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
del input_ids_flat_unpadded
|
| 90 |
+
|
| 91 |
+
labels_flat = labels.flatten() if labels is not None else None
|
| 92 |
+
|
| 93 |
+
ve = [value_embed(input_ids_flat) for value_embed in self.value_embeds]
|
| 94 |
+
# 012 ... 012 structure on token value embeddings by @YouJiacheng, improved on @leloykun's U-net structure
|
| 95 |
+
ve = (
|
| 96 |
+
[ve[0], ve[1], ve[2]]
|
| 97 |
+
+ [None] * (len(self.blocks) - 6)
|
| 98 |
+
+ [ve[0], ve[1], ve[2]]
|
| 99 |
+
)
|
| 100 |
+
assert len(ve) == len(self.blocks)
|
| 101 |
+
|
| 102 |
+
sliding_window_num_blocks = get_window_size_blocks_helper(3584)
|
| 103 |
+
|
| 104 |
+
long_bm, short_bm = self.create_blockmasks(
|
| 105 |
+
input_ids_flat, sliding_window_num_blocks
|
| 106 |
+
)
|
| 107 |
+
block_masks = [
|
| 108 |
+
long_bm,
|
| 109 |
+
short_bm,
|
| 110 |
+
short_bm,
|
| 111 |
+
short_bm,
|
| 112 |
+
long_bm,
|
| 113 |
+
short_bm,
|
| 114 |
+
short_bm,
|
| 115 |
+
short_bm,
|
| 116 |
+
short_bm,
|
| 117 |
+
short_bm,
|
| 118 |
+
short_bm,
|
| 119 |
+
long_bm,
|
| 120 |
+
short_bm,
|
| 121 |
+
short_bm,
|
| 122 |
+
short_bm,
|
| 123 |
+
long_bm,
|
| 124 |
+
]
|
| 125 |
+
assert len(block_masks) == len(self.blocks)
|
| 126 |
+
|
| 127 |
+
logger.debug(long_bm.to_string())
|
| 128 |
+
logger.debug(short_bm.to_string())
|
| 129 |
+
|
| 130 |
+
x = x0 = norm(
|
| 131 |
+
self.embed(input_ids_flat)[None]
|
| 132 |
+
) # use of norm here by @Grad62304977
|
| 133 |
+
|
| 134 |
+
skip_connections = []
|
| 135 |
+
skip_map = {
|
| 136 |
+
9: 6,
|
| 137 |
+
10: 4,
|
| 138 |
+
11: 2,
|
| 139 |
+
}
|
| 140 |
+
skip_weights = self.scalars[: len(self.blocks)]
|
| 141 |
+
lambdas = self.scalars[1 * len(self.blocks) : 3 * len(self.blocks)].view(-1, 2)
|
| 142 |
+
sa_lambdas = self.scalars[3 * len(self.blocks) : 5 * len(self.blocks)].view(
|
| 143 |
+
-1, 2
|
| 144 |
+
)
|
| 145 |
+
for i in range(len(self.blocks)):
|
| 146 |
+
if i in skip_map:
|
| 147 |
+
x = x + skip_weights[skip_map[i]] * skip_connections[skip_map[i]]
|
| 148 |
+
x = self.blocks[i](x, ve[i], x0, block_masks[i], lambdas[i], sa_lambdas[i])
|
| 149 |
+
skip_connections.append(x)
|
| 150 |
+
|
| 151 |
+
x = norm(x)
|
| 152 |
+
|
| 153 |
+
unpadded_outputs = x[:, :unpadded_len]
|
| 154 |
+
unrolled_outputs = unpadded_outputs.view(
|
| 155 |
+
*input_ids_with_eos_separators.shape, -1
|
| 156 |
+
)
|
| 157 |
+
outputs = unrolled_outputs[:, 1:]
|
| 158 |
+
|
| 159 |
+
loss = None
|
| 160 |
+
if labels_flat is not None:
|
| 161 |
+
loss = 0
|
| 162 |
+
for i in range(num_samples):
|
| 163 |
+
logits: th.Tensor = F.linear(
|
| 164 |
+
outputs.flatten(end_dim=1).chunk(num_samples)[i],
|
| 165 |
+
self.lm_head_w.bfloat16(),
|
| 166 |
+
).float()
|
| 167 |
+
|
| 168 |
+
targets_padded = labels_flat.chunk(num_samples)[i]
|
| 169 |
+
# -100 where we have the padding token
|
| 170 |
+
targets = targets_padded.masked_fill(targets_padded == 50256, -100)
|
| 171 |
+
|
| 172 |
+
loss += (
|
| 173 |
+
F.cross_entropy(
|
| 174 |
+
15 * logits * th.rsqrt(logits.square() + 225),
|
| 175 |
+
targets,
|
| 176 |
+
)
|
| 177 |
+
/ num_samples
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
logits: th.Tensor = F.linear(outputs, self.lm_head_w.bfloat16()).float()
|
| 181 |
+
|
| 182 |
+
return CausalLMOutputWithPast(
|
| 183 |
+
loss=loss,
|
| 184 |
+
logits=logits,
|
| 185 |
+
past_key_values=None,
|
| 186 |
+
hidden_states=None,
|
| 187 |
+
attentions=None,
|
| 188 |
+
)
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
class CustomConfig(PretrainedConfig):
|
| 192 |
+
pass
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
class CustomModel(PreTrainedModel):
|
| 196 |
+
config_class = CustomConfig
|
| 197 |
+
|
| 198 |
+
def __init__(self, config: CustomConfig, model_path: Path):
|
| 199 |
+
super().__init__(config)
|
| 200 |
+
|
| 201 |
+
logger.info(f"Initializing model with hyperparameters: {args}")
|
| 202 |
+
self.model = EvaluationGPT(
|
| 203 |
+
vocab_size=args.vocab_size,
|
| 204 |
+
num_layers=16,
|
| 205 |
+
num_heads=8,
|
| 206 |
+
model_dim=1024,
|
| 207 |
+
max_seq_len=max(args.train_seq_len, args.val_seq_len),
|
| 208 |
+
use_normal_loss=True,
|
| 209 |
+
)
|
| 210 |
+
|
| 211 |
+
logger.info(f"Loading model state dict from {model_path}")
|
| 212 |
+
model_state_dict = th.load(model_path)
|
| 213 |
+
|
| 214 |
+
logger.info("Renaming keys in model state dict")
|
| 215 |
+
renamed_model_state_dict = {
|
| 216 |
+
key.replace("_orig_mod.", ""): value
|
| 217 |
+
for key, value in model_state_dict.items()
|
| 218 |
+
if key.startswith("_orig_mod.")
|
| 219 |
+
}
|
| 220 |
+
|
| 221 |
+
self.model.load_state_dict(renamed_model_state_dict)
|
| 222 |
+
|
| 223 |
+
del model_state_dict, renamed_model_state_dict
|
| 224 |
+
|
| 225 |
+
logger.info("Initializing tokenizer")
|
| 226 |
+
self.tokenizer = AutoTokenizer.from_pretrained("gpt2")
|
| 227 |
+
|
| 228 |
+
def forward(self, input_ids: th.Tensor, labels: th.Tensor | None = None):
|
| 229 |
+
return self.model(input_ids, labels)
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
@arguably.command()
|
| 233 |
+
def main(logs_dirpath: str = "logs", log_level: str = "INFO", limit: int | None = None):
|
| 234 |
+
logger.remove()
|
| 235 |
+
logger.add(sys.stderr, level=log_level)
|
| 236 |
+
|
| 237 |
+
# Single GPU setup
|
| 238 |
+
assert th.cuda.is_available()
|
| 239 |
+
device = th.device("cuda", 0)
|
| 240 |
+
th.cuda.set_device(device)
|
| 241 |
+
|
| 242 |
+
start_time = time.time()
|
| 243 |
+
|
| 244 |
+
logger.info(f"Evaluating logs in {logs_dirpath}")
|
| 245 |
+
logs_dir = Path(logs_dirpath)
|
| 246 |
+
|
| 247 |
+
assert logs_dir.exists(), f"Logs directory {logs_dirpath} does not exist"
|
| 248 |
+
|
| 249 |
+
run_dirpaths = set(child for child in logs_dir.iterdir() if child.is_dir())
|
| 250 |
+
|
| 251 |
+
assert len(run_dirpaths) <= 1, f"Multiple run directories found in {logs_dirpath}"
|
| 252 |
+
assert len(run_dirpaths) > 0, f"No run directories found in {logs_dirpath}"
|
| 253 |
+
|
| 254 |
+
run_dirpath = run_dirpaths.pop()
|
| 255 |
+
|
| 256 |
+
logger.info(f"Finding latest model in {run_dirpath}")
|
| 257 |
+
model_path = run_dirpath / "latest_model.pt"
|
| 258 |
+
assert model_path.exists(), f"Model path {model_path} does not exist"
|
| 259 |
+
|
| 260 |
+
logger.info(f"Loading model from {model_path}")
|
| 261 |
+
model = CustomModel(CustomConfig(), model_path).to(device)
|
| 262 |
+
|
| 263 |
+
logger.info("Wrapping model in HFLM")
|
| 264 |
+
wrapped_model = HFLM(pretrained=model, tokenizer=model.tokenizer)
|
| 265 |
+
for m in model.modules():
|
| 266 |
+
if isinstance(m, nn.Embedding):
|
| 267 |
+
m.bfloat16()
|
| 268 |
+
|
| 269 |
+
logger.info("Evaluating model")
|
| 270 |
+
results_raw = evaluator.simple_evaluate(
|
| 271 |
+
model=wrapped_model, tasks=["hellaswag"], limit=limit, verbosity="DEBUG"
|
| 272 |
+
)
|
| 273 |
+
results = results_raw["results"]["hellaswag"]
|
| 274 |
+
logger.info(results)
|
| 275 |
+
logger.info(f"Saving results to {run_dirpath / 'hellaswag.json'}")
|
| 276 |
+
with open(run_dirpath / "hellaswag.yaml", "w") as f:
|
| 277 |
+
yaml.dump(results, f)
|
| 278 |
+
|
| 279 |
+
end_time = time.time()
|
| 280 |
+
logger.info(f"Total evaluation time: {end_time - start_time:.2f}s")
|
| 281 |
+
logger.success(f"Final accuracy: {results['acc,none']}")
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
if __name__ == "__main__":
|
| 285 |
+
arguably.run()
|
img/algo_optimizer.png
ADDED

|
Git LFS Details
|
img/dofa.jpg
ADDED

|
img/fig_optimizer.png
ADDED

|
Git LFS Details
|
img/fig_tuned_nanogpt.png
ADDED

|
Git LFS Details
|
img/nanogpt_speedrun51.png
ADDED

|
Git LFS Details
|
img/nanogpt_speedrun52.png
ADDED
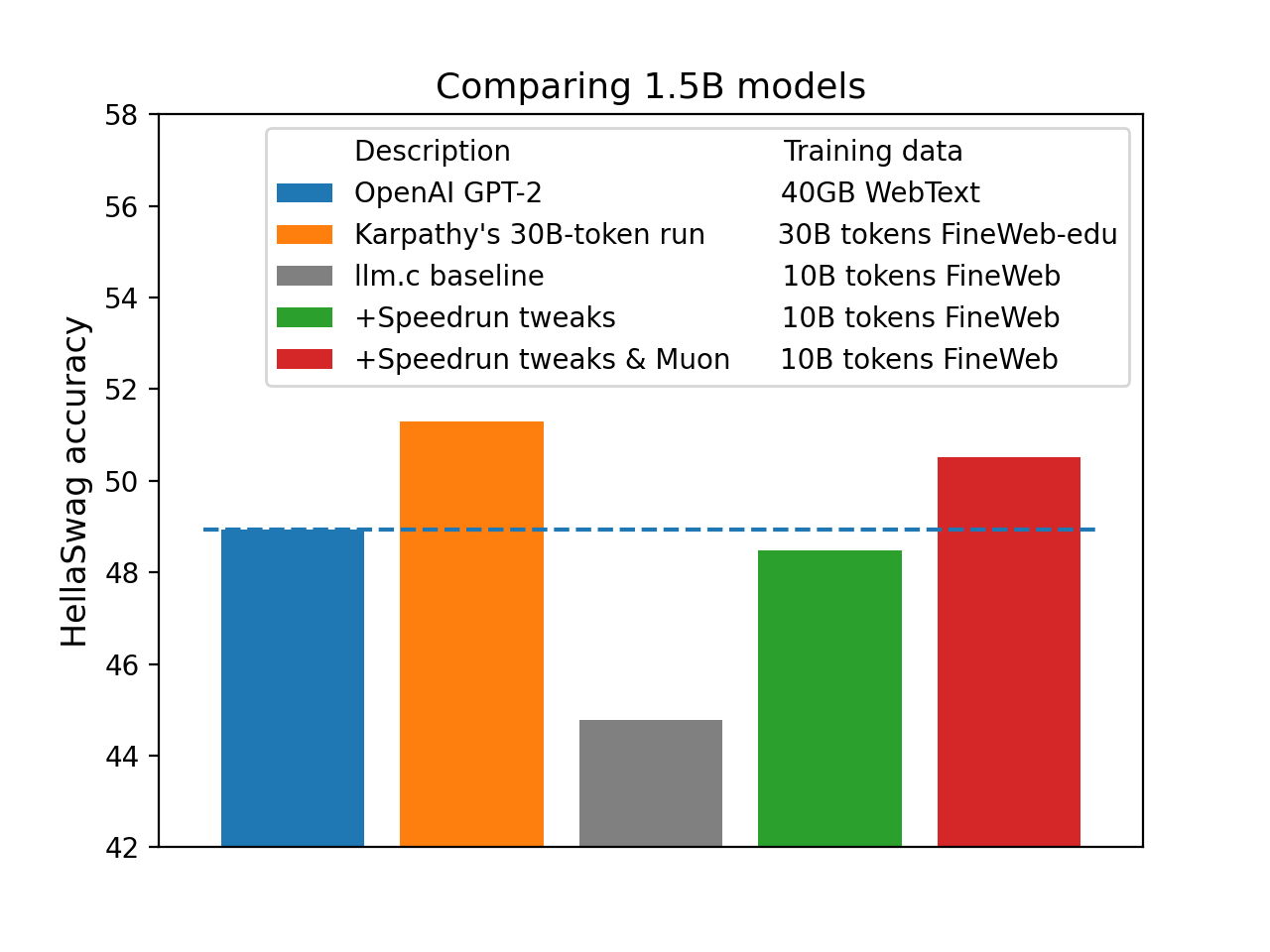
|
img/nanogpt_speedrun53.png
ADDED

|
Git LFS Details
|
img/nanogpt_speedrun54.png
ADDED
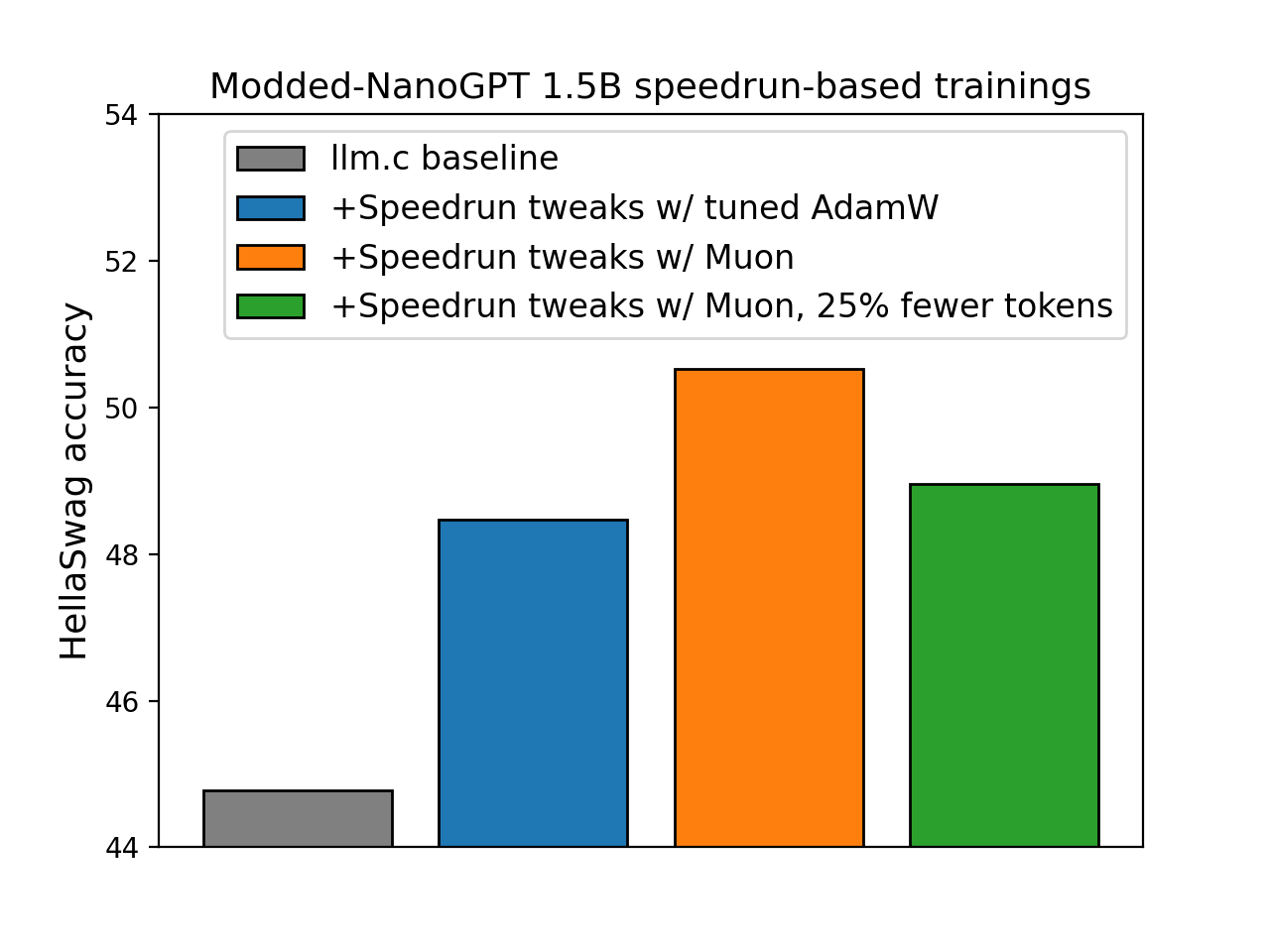
|
logs/000_c2e7a920-6eca-4f21-8a3c-6022d81a4f29.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
logs/000_c2e7a920-6eca-4f21-8a3c-6022d81a4f29/hellaswag.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0d1732b0b75ef581f5ea694c5e32c0526cacf2e7d4e281c4e080da5c1df6915a
|
| 3 |
+
size 42056535
|
logs/000_c2e7a920-6eca-4f21-8a3c-6022d81a4f29/hellaswag.yaml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
acc,none: 0.25403306114319857
|
| 2 |
+
acc_norm,none: 0.25473013343955386
|
| 3 |
+
acc_norm_stderr,none: 0.0043481894593367845
|
| 4 |
+
acc_stderr,none: 0.004344266179634878
|
| 5 |
+
alias: hellaswag
|
logs/000_c2e7a920-6eca-4f21-8a3c-6022d81a4f29/latest_model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3c78ef87b6c319f98eee0e6df393f81fe9d4266ddd748c03573c7c379a7cabe8
|
| 3 |
+
size 1012036843
|
logs/000_c2e7a920-6eca-4f21-8a3c-6022d81a4f29/state_step057344.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7a0a5c2df89a1255807c601a6f54344eada4c16110b18c393ef444ee948e0e02
|
| 3 |
+
size 3430398968
|
modded-nanogpt-eval.16715025
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
SLURM Job ID: 16715025
|
| 2 |
+
SLURM Node List: g064
|
| 3 |
+
SLURM Number of Nodes: 1
|
| 4 |
+
SLURM Number of Tasks: 1
|
| 5 |
+
SLURM Tasks per Node: 1
|
| 6 |
+
SLURM Local ID: 0
|
| 7 |
+
SLURM Procedure ID: 0
|
| 8 |
+
SLURM Node ID: 0
|
| 9 |
+
MASTER_ADDR: g064
|
| 10 |
+
MASTER_PORT: 15025
|
| 11 |
+
RANK: 0
|
| 12 |
+
WORLD_SIZE: 1
|
| 13 |
+
CUDA_VISIBLE_DEVICES: 0
|
| 14 |
+
importing torch...
|
| 15 |
+
importing lm_eval...
|
modded-nanogpt-eval.16715025.err
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
modded-nanogpt-train.16700835
ADDED
|
@@ -0,0 +1,911 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
SLURM Job ID: 16700835
|
| 2 |
+
SLURM Node List: g061
|
| 3 |
+
SLURM Number of Nodes: 1
|
| 4 |
+
SLURM Number of Tasks: 1
|
| 5 |
+
SLURM Tasks per Node: 1
|
| 6 |
+
SLURM Local ID: 0
|
| 7 |
+
SLURM Procedure ID: 0
|
| 8 |
+
SLURM Node ID: 0
|
| 9 |
+
MASTER_ADDR: g061
|
| 10 |
+
MASTER_PORT: 10835
|
| 11 |
+
RANK: 0
|
| 12 |
+
WORLD_SIZE: 1
|
| 13 |
+
CUDA_VISIBLE_DEVICES: 0
|
| 14 |
+
logs/000_c2e7a920-6eca-4f21-8a3c-6022d81a4f29.txt
|
| 15 |
+
step:0/57344 val_loss:10.825846 train_time:49497ms step_avg:49496.54ms
|
| 16 |
+
step:64/57344 val_loss:7.268824 train_time:112068ms step_avg:1751.06ms
|
| 17 |
+
step:128/57344 val_loss:7.868536 train_time:139973ms step_avg:1093.54ms
|
| 18 |
+
step:192/57344 val_loss:7.894432 train_time:167886ms step_avg:874.40ms
|
| 19 |
+
step:256/57344 val_loss:7.892108 train_time:195848ms step_avg:765.03ms
|
| 20 |
+
step:320/57344 val_loss:7.884940 train_time:223782ms step_avg:699.32ms
|
| 21 |
+
step:384/57344 val_loss:7.894324 train_time:251648ms step_avg:655.33ms
|
| 22 |
+
step:448/57344 val_loss:7.885835 train_time:279487ms step_avg:623.85ms
|
| 23 |
+
step:512/57344 val_loss:7.861404 train_time:307303ms step_avg:600.20ms
|
| 24 |
+
step:576/57344 val_loss:7.886768 train_time:335115ms step_avg:581.80ms
|
| 25 |
+
step:640/57344 val_loss:7.896187 train_time:362939ms step_avg:567.09ms
|
| 26 |
+
step:704/57344 val_loss:7.831467 train_time:390740ms step_avg:555.03ms
|
| 27 |
+
step:768/57344 val_loss:7.814738 train_time:418728ms step_avg:545.22ms
|
| 28 |
+
step:832/57344 val_loss:7.819521 train_time:446848ms step_avg:537.08ms
|
| 29 |
+
step:896/57344 val_loss:7.808165 train_time:475003ms step_avg:530.14ms
|
| 30 |
+
step:960/57344 val_loss:8.015900 train_time:508745ms step_avg:529.94ms
|
| 31 |
+
step:1024/57344 val_loss:7.776239 train_time:536896ms step_avg:524.31ms
|
| 32 |
+
step:1088/57344 val_loss:7.767220 train_time:565031ms step_avg:519.33ms
|
| 33 |
+
step:1152/57344 val_loss:7.740644 train_time:593535ms step_avg:515.22ms
|
| 34 |
+
step:1216/57344 val_loss:7.748327 train_time:621713ms step_avg:511.28ms
|
| 35 |
+
step:1280/57344 val_loss:7.739236 train_time:649898ms step_avg:507.73ms
|
| 36 |
+
step:1344/57344 val_loss:7.731204 train_time:678089ms step_avg:504.53ms
|
| 37 |
+
step:1408/57344 val_loss:7.720304 train_time:706296ms step_avg:501.63ms
|
| 38 |
+
step:1472/57344 val_loss:7.720869 train_time:734485ms step_avg:498.97ms
|
| 39 |
+
step:1536/57344 val_loss:7.711709 train_time:762880ms step_avg:496.67ms
|
| 40 |
+
step:1600/57344 val_loss:7.718039 train_time:791386ms step_avg:494.62ms
|
| 41 |
+
step:1664/57344 val_loss:7.701055 train_time:822510ms step_avg:494.30ms
|
| 42 |
+
step:1728/57344 val_loss:7.690996 train_time:851055ms step_avg:492.51ms
|
| 43 |
+
step:1792/57344 val_loss:7.680806 train_time:879628ms step_avg:490.86ms
|
| 44 |
+
step:1856/57344 val_loss:7.694116 train_time:908227ms step_avg:489.35ms
|
| 45 |
+
step:1920/57344 val_loss:7.679022 train_time:936851ms step_avg:487.94ms
|
| 46 |
+
step:1984/57344 val_loss:7.671133 train_time:966348ms step_avg:487.07ms
|
| 47 |
+
step:2048/57344 val_loss:7.682602 train_time:994951ms step_avg:485.82ms
|
| 48 |
+
step:2112/57344 val_loss:7.683117 train_time:1023534ms step_avg:484.63ms
|
| 49 |
+
step:2176/57344 val_loss:7.671322 train_time:1052098ms step_avg:483.50ms
|
| 50 |
+
step:2240/57344 val_loss:7.671769 train_time:1080662ms step_avg:482.44ms
|
| 51 |
+
step:2304/57344 val_loss:7.721270 train_time:1109210ms step_avg:481.43ms
|
| 52 |
+
step:2368/57344 val_loss:7.682425 train_time:1138975ms step_avg:480.99ms
|
| 53 |
+
step:2432/57344 val_loss:7.659926 train_time:1168401ms step_avg:480.43ms
|
| 54 |
+
step:2496/57344 val_loss:7.657366 train_time:1197782ms step_avg:479.88ms
|
| 55 |
+
step:2560/57344 val_loss:7.671144 train_time:1227424ms step_avg:479.46ms
|
| 56 |
+
step:2624/57344 val_loss:7.665736 train_time:1257202ms step_avg:479.12ms
|
| 57 |
+
step:2688/57344 val_loss:7.658612 train_time:1287061ms step_avg:478.82ms
|
| 58 |
+
step:2752/57344 val_loss:7.654680 train_time:1317100ms step_avg:478.60ms
|
| 59 |
+
step:2816/57344 val_loss:7.668962 train_time:1365570ms step_avg:484.93ms
|
| 60 |
+
step:2880/57344 val_loss:7.658406 train_time:1395282ms step_avg:484.47ms
|
| 61 |
+
step:2944/57344 val_loss:7.661676 train_time:1425036ms step_avg:484.05ms
|
| 62 |
+
step:3008/57344 val_loss:7.658646 train_time:1454808ms step_avg:483.65ms
|
| 63 |
+
step:3072/57344 val_loss:7.662162 train_time:1484577ms step_avg:483.26ms
|
| 64 |
+
step:3136/57344 val_loss:7.658408 train_time:1514355ms step_avg:482.89ms
|
| 65 |
+
step:3200/57344 val_loss:7.672349 train_time:1544242ms step_avg:482.58ms
|
| 66 |
+
step:3264/57344 val_loss:7.672679 train_time:1748797ms step_avg:535.78ms
|
| 67 |
+
step:3328/57344 val_loss:7.652864 train_time:1778462ms step_avg:534.39ms
|
| 68 |
+
step:3392/57344 val_loss:7.665180 train_time:1808364ms step_avg:533.13ms
|
| 69 |
+
step:3456/57344 val_loss:7.667527 train_time:1838477ms step_avg:531.97ms
|
| 70 |
+
step:3520/57344 val_loss:7.654069 train_time:1868547ms step_avg:530.84ms
|
| 71 |
+
step:3584/57344 val_loss:7.655974 train_time:1899400ms step_avg:529.97ms
|
| 72 |
+
step:3648/57344 val_loss:7.667745 train_time:1929456ms step_avg:528.91ms
|
| 73 |
+
step:3712/57344 val_loss:7.656830 train_time:1959355ms step_avg:527.84ms
|
| 74 |
+
step:3776/57344 val_loss:7.658441 train_time:1989406ms step_avg:526.86ms
|
| 75 |
+
step:3840/57344 val_loss:7.663338 train_time:2019221ms step_avg:525.84ms
|
| 76 |
+
step:3904/57344 val_loss:7.677653 train_time:2049323ms step_avg:524.93ms
|
| 77 |
+
step:3968/57344 val_loss:7.659332 train_time:2079474ms step_avg:524.06ms
|
| 78 |
+
step:4032/57344 val_loss:7.704954 train_time:2109571ms step_avg:523.21ms
|
| 79 |
+
step:4096/57344 val_loss:7.691890 train_time:2139562ms step_avg:522.35ms
|
| 80 |
+
step:4160/57344 val_loss:7.703646 train_time:2170457ms step_avg:521.74ms
|
| 81 |
+
step:4224/57344 val_loss:7.705266 train_time:2201369ms step_avg:521.16ms
|
| 82 |
+
step:4288/57344 val_loss:7.716187 train_time:2329339ms step_avg:543.22ms
|
| 83 |
+
step:4352/57344 val_loss:7.718926 train_time:2360103ms step_avg:542.30ms
|
| 84 |
+
step:4416/57344 val_loss:7.717360 train_time:2391116ms step_avg:541.47ms
|
| 85 |
+
step:4480/57344 val_loss:7.713251 train_time:2855734ms step_avg:637.44ms
|
| 86 |
+
step:4544/57344 val_loss:7.724630 train_time:2887193ms step_avg:635.39ms
|
| 87 |
+
step:4608/57344 val_loss:7.735681 train_time:2983562ms step_avg:647.47ms
|
| 88 |
+
step:4672/57344 val_loss:7.736219 train_time:3014413ms step_avg:645.21ms
|
| 89 |
+
step:4736/57344 val_loss:7.716004 train_time:3045483ms step_avg:643.05ms
|
| 90 |
+
step:4800/57344 val_loss:7.705821 train_time:3172744ms step_avg:660.99ms
|
| 91 |
+
step:4864/57344 val_loss:7.705976 train_time:3224982ms step_avg:663.03ms
|
| 92 |
+
step:4928/57344 val_loss:7.694653 train_time:3255953ms step_avg:660.70ms
|
| 93 |
+
step:4992/57344 val_loss:7.678105 train_time:3287098ms step_avg:658.47ms
|
| 94 |
+
step:5056/57344 val_loss:7.682966 train_time:3318193ms step_avg:656.29ms
|
| 95 |
+
step:5120/57344 val_loss:7.662866 train_time:3349483ms step_avg:654.20ms
|
| 96 |
+
step:5184/57344 val_loss:7.657860 train_time:3443992ms step_avg:664.35ms
|
| 97 |
+
step:5248/57344 val_loss:7.645894 train_time:3475104ms step_avg:662.18ms
|
| 98 |
+
step:5312/57344 val_loss:7.632289 train_time:3506478ms step_avg:660.11ms
|
| 99 |
+
step:5376/57344 val_loss:7.624333 train_time:3624432ms step_avg:674.19ms
|
| 100 |
+
step:5440/57344 val_loss:7.623236 train_time:3655544ms step_avg:671.97ms
|
| 101 |
+
step:5504/57344 val_loss:7.609012 train_time:3687800ms step_avg:670.02ms
|
| 102 |
+
step:5568/57344 val_loss:7.585613 train_time:3719285ms step_avg:667.97ms
|
| 103 |
+
step:5632/57344 val_loss:7.579461 train_time:3750646ms step_avg:665.95ms
|
| 104 |
+
step:5696/57344 val_loss:7.564924 train_time:3781955ms step_avg:663.97ms
|
| 105 |
+
step:5760/57344 val_loss:7.561890 train_time:3814320ms step_avg:662.21ms
|
| 106 |
+
step:5824/57344 val_loss:7.537563 train_time:3845619ms step_avg:660.31ms
|
| 107 |
+
step:5888/57344 val_loss:7.519125 train_time:3876972ms step_avg:658.45ms
|
| 108 |
+
step:5952/57344 val_loss:7.499354 train_time:3908362ms step_avg:656.65ms
|
| 109 |
+
step:6016/57344 val_loss:7.477836 train_time:3939672ms step_avg:654.87ms
|
| 110 |
+
step:6080/57344 val_loss:7.459615 train_time:3971061ms step_avg:653.14ms
|
| 111 |
+
step:6144/57344 val_loss:7.435397 train_time:4002430ms step_avg:651.44ms
|
| 112 |
+
step:6208/57344 val_loss:7.421387 train_time:4033895ms step_avg:649.79ms
|
| 113 |
+
step:6272/57344 val_loss:7.422082 train_time:4066063ms step_avg:648.29ms
|
| 114 |
+
step:6336/57344 val_loss:7.390254 train_time:4098255ms step_avg:646.82ms
|
| 115 |
+
step:6400/57344 val_loss:7.379295 train_time:4134419ms step_avg:646.00ms
|
| 116 |
+
step:6464/57344 val_loss:7.352916 train_time:4166470ms step_avg:644.57ms
|
| 117 |
+
step:6528/57344 val_loss:7.353693 train_time:4224343ms step_avg:647.11ms
|
| 118 |
+
step:6592/57344 val_loss:7.355770 train_time:4256555ms step_avg:645.72ms
|
| 119 |
+
step:6656/57344 val_loss:7.331154 train_time:4288830ms step_avg:644.36ms
|
| 120 |
+
step:6720/57344 val_loss:7.320140 train_time:4321226ms step_avg:643.04ms
|
| 121 |
+
step:6784/57344 val_loss:7.303020 train_time:4355477ms step_avg:642.02ms
|
| 122 |
+
step:6848/57344 val_loss:7.333101 train_time:4387579ms step_avg:640.71ms
|
| 123 |
+
step:6912/57344 val_loss:7.345509 train_time:4419724ms step_avg:639.43ms
|
| 124 |
+
step:6976/57344 val_loss:7.340341 train_time:4451903ms step_avg:638.17ms
|
| 125 |
+
step:7040/57344 val_loss:7.340064 train_time:4484141ms step_avg:636.95ms
|
| 126 |
+
step:7104/57344 val_loss:7.338420 train_time:4519324ms step_avg:636.17ms
|
| 127 |
+
step:7168/57344 val_loss:7.325290 train_time:4551476ms step_avg:634.97ms
|
| 128 |
+
step:7232/57344 val_loss:7.317104 train_time:4583656ms step_avg:633.80ms
|
| 129 |
+
step:7296/57344 val_loss:7.306343 train_time:4615876ms step_avg:632.66ms
|
| 130 |
+
step:7360/57344 val_loss:7.293196 train_time:4648062ms step_avg:631.53ms
|
| 131 |
+
step:7424/57344 val_loss:7.285810 train_time:4680293ms step_avg:630.43ms
|
| 132 |
+
step:7488/57344 val_loss:7.275821 train_time:4712571ms step_avg:629.35ms
|
| 133 |
+
step:7552/57344 val_loss:7.248770 train_time:4744935ms step_avg:628.30ms
|
| 134 |
+
step:7616/57344 val_loss:7.234798 train_time:4777304ms step_avg:627.27ms
|
| 135 |
+
step:7680/57344 val_loss:7.221576 train_time:4809649ms step_avg:626.26ms
|
| 136 |
+
step:7744/57344 val_loss:7.207185 train_time:4841892ms step_avg:625.24ms
|
| 137 |
+
step:7808/57344 val_loss:7.189125 train_time:4875120ms step_avg:624.37ms
|
| 138 |
+
step:7872/57344 val_loss:7.187330 train_time:4907404ms step_avg:623.40ms
|
| 139 |
+
step:7936/57344 val_loss:7.182116 train_time:4939728ms step_avg:622.45ms
|
| 140 |
+
step:8000/57344 val_loss:7.149826 train_time:4972031ms step_avg:621.50ms
|
| 141 |
+
step:8064/57344 val_loss:7.138590 train_time:5004296ms step_avg:620.57ms
|
| 142 |
+
step:8128/57344 val_loss:7.127815 train_time:5036610ms step_avg:619.66ms
|
| 143 |
+
step:8192/57344 val_loss:7.110021 train_time:5068937ms step_avg:618.77ms
|
| 144 |
+
step:8256/57344 val_loss:7.109468 train_time:5101290ms step_avg:617.89ms
|
| 145 |
+
step:8320/57344 val_loss:7.096864 train_time:5133602ms step_avg:617.02ms
|
| 146 |
+
step:8384/57344 val_loss:7.088062 train_time:5183023ms step_avg:618.20ms
|
| 147 |
+
step:8448/57344 val_loss:7.069827 train_time:5215293ms step_avg:617.34ms
|
| 148 |
+
step:8512/57344 val_loss:7.057210 train_time:5247523ms step_avg:616.49ms
|
| 149 |
+
step:8576/57344 val_loss:7.057277 train_time:5279815ms step_avg:615.65ms
|
| 150 |
+
step:8640/57344 val_loss:7.051640 train_time:5312137ms step_avg:614.83ms
|
| 151 |
+
step:8704/57344 val_loss:7.042135 train_time:5344556ms step_avg:614.03ms
|
| 152 |
+
step:8768/57344 val_loss:7.022151 train_time:5377346ms step_avg:613.29ms
|
| 153 |
+
step:8832/57344 val_loss:7.020913 train_time:5410081ms step_avg:612.55ms
|
| 154 |
+
step:8896/57344 val_loss:7.011633 train_time:5443095ms step_avg:611.86ms
|
| 155 |
+
step:8960/57344 val_loss:7.005154 train_time:5476093ms step_avg:611.17ms
|
| 156 |
+
step:9024/57344 val_loss:6.996831 train_time:5509149ms step_avg:610.50ms
|
| 157 |
+
step:9088/57344 val_loss:6.996270 train_time:5544060ms step_avg:610.04ms
|
| 158 |
+
step:9152/57344 val_loss:6.975245 train_time:5577019ms step_avg:609.38ms
|
| 159 |
+
step:9216/57344 val_loss:6.971144 train_time:5610070ms step_avg:608.73ms
|
| 160 |
+
step:9280/57344 val_loss:6.959331 train_time:5643110ms step_avg:608.09ms
|
| 161 |
+
step:9344/57344 val_loss:6.947041 train_time:5676612ms step_avg:607.51ms
|
| 162 |
+
step:9408/57344 val_loss:6.943706 train_time:5709710ms step_avg:606.90ms
|
| 163 |
+
step:9472/57344 val_loss:6.932907 train_time:5742682ms step_avg:606.28ms
|
| 164 |
+
step:9536/57344 val_loss:6.923458 train_time:5775902ms step_avg:605.69ms
|
| 165 |
+
step:9600/57344 val_loss:6.904294 train_time:5808929ms step_avg:605.10ms
|
| 166 |
+
step:9664/57344 val_loss:6.895104 train_time:5841922ms step_avg:604.50ms
|
| 167 |
+
step:9728/57344 val_loss:6.919672 train_time:5875112ms step_avg:603.94ms
|
| 168 |
+
step:9792/57344 val_loss:6.897346 train_time:5909453ms step_avg:603.50ms
|
| 169 |
+
step:9856/57344 val_loss:6.873909 train_time:5942453ms step_avg:602.93ms
|
| 170 |
+
step:9920/57344 val_loss:6.848538 train_time:5975530ms step_avg:602.37ms
|
| 171 |
+
step:9984/57344 val_loss:6.834342 train_time:6008529ms step_avg:601.82ms
|
| 172 |
+
step:10048/57344 val_loss:6.803728 train_time:6041518ms step_avg:601.27ms
|
| 173 |
+
step:10112/57344 val_loss:6.795698 train_time:6074579ms step_avg:600.73ms
|
| 174 |
+
step:10176/57344 val_loss:6.764917 train_time:6109053ms step_avg:600.34ms
|
| 175 |
+
step:10240/57344 val_loss:6.742457 train_time:6142110ms step_avg:599.82ms
|
| 176 |
+
step:10304/57344 val_loss:6.716063 train_time:6176059ms step_avg:599.38ms
|
| 177 |
+
step:10368/57344 val_loss:6.749411 train_time:6209130ms step_avg:598.87ms
|
| 178 |
+
step:10432/57344 val_loss:6.760437 train_time:6242412ms step_avg:598.39ms
|
| 179 |
+
step:10496/57344 val_loss:6.781706 train_time:6275531ms step_avg:597.90ms
|
| 180 |
+
step:10560/57344 val_loss:6.785400 train_time:6322879ms step_avg:598.76ms
|
| 181 |
+
step:10624/57344 val_loss:6.800114 train_time:6356619ms step_avg:598.33ms
|
| 182 |
+
step:10688/57344 val_loss:6.797913 train_time:6389724ms step_avg:597.84ms
|
| 183 |
+
step:10752/57344 val_loss:6.798851 train_time:6422918ms step_avg:597.37ms
|
| 184 |
+
step:10816/57344 val_loss:6.835824 train_time:6456027ms step_avg:596.90ms
|
| 185 |
+
step:10880/57344 val_loss:6.815319 train_time:6489232ms step_avg:596.44ms
|
| 186 |
+
step:10944/57344 val_loss:6.821844 train_time:6522262ms step_avg:595.97ms
|
| 187 |
+
step:11008/57344 val_loss:6.818879 train_time:6555343ms step_avg:595.51ms
|
| 188 |
+
step:11072/57344 val_loss:6.813581 train_time:6594659ms step_avg:595.62ms
|
| 189 |
+
step:11136/57344 val_loss:6.821119 train_time:6632542ms step_avg:595.59ms
|
| 190 |
+
step:11200/57344 val_loss:6.829227 train_time:6665655ms step_avg:595.15ms
|
| 191 |
+
step:11264/57344 val_loss:6.825552 train_time:6698758ms step_avg:594.71ms
|
| 192 |
+
step:11328/57344 val_loss:6.823633 train_time:6731799ms step_avg:594.26ms
|
| 193 |
+
step:11392/57344 val_loss:6.831137 train_time:6766457ms step_avg:593.97ms
|
| 194 |
+
step:11456/57344 val_loss:6.834339 train_time:6799691ms step_avg:593.55ms
|
| 195 |
+
step:11520/57344 val_loss:6.832121 train_time:6832887ms step_avg:593.13ms
|
| 196 |
+
step:11584/57344 val_loss:6.843909 train_time:6866151ms step_avg:592.73ms
|
| 197 |
+
step:11648/57344 val_loss:6.840989 train_time:6899449ms step_avg:592.33ms
|
| 198 |
+
step:11712/57344 val_loss:6.845339 train_time:6932546ms step_avg:591.92ms
|
| 199 |
+
step:11776/57344 val_loss:6.858196 train_time:6965690ms step_avg:591.52ms
|
| 200 |
+
step:11840/57344 val_loss:6.831332 train_time:6998739ms step_avg:591.11ms
|
| 201 |
+
step:11904/57344 val_loss:6.828391 train_time:7031793ms step_avg:590.71ms
|
| 202 |
+
step:11968/57344 val_loss:6.826741 train_time:7064865ms step_avg:590.31ms
|
| 203 |
+
step:12032/57344 val_loss:6.813456 train_time:7097864ms step_avg:589.92ms
|
| 204 |
+
step:12096/57344 val_loss:6.816004 train_time:7154951ms step_avg:591.51ms
|
| 205 |
+
step:12160/57344 val_loss:6.811965 train_time:7204778ms step_avg:592.50ms
|
| 206 |
+
step:12224/57344 val_loss:6.795401 train_time:7237714ms step_avg:592.09ms
|
| 207 |
+
step:12288/57344 val_loss:6.807929 train_time:7272256ms step_avg:591.82ms
|
| 208 |
+
step:12352/57344 val_loss:6.793258 train_time:7305552ms step_avg:591.45ms
|
| 209 |
+
step:12416/57344 val_loss:6.786059 train_time:7339062ms step_avg:591.10ms
|
| 210 |
+
step:12480/57344 val_loss:6.784020 train_time:7372691ms step_avg:590.76ms
|
| 211 |
+
step:12544/57344 val_loss:6.784947 train_time:7406289ms step_avg:590.42ms
|
| 212 |
+
step:12608/57344 val_loss:6.778395 train_time:7439898ms step_avg:590.09ms
|
| 213 |
+
step:12672/57344 val_loss:6.777520 train_time:7473535ms step_avg:589.77ms
|
| 214 |
+
step:12736/57344 val_loss:6.763353 train_time:7510995ms step_avg:589.75ms
|
| 215 |
+
step:12800/57344 val_loss:6.765983 train_time:7570352ms step_avg:591.43ms
|
| 216 |
+
step:12864/57344 val_loss:6.761808 train_time:7605704ms step_avg:591.24ms
|
| 217 |
+
step:12928/57344 val_loss:6.779835 train_time:7639263ms step_avg:590.91ms
|
| 218 |
+
step:12992/57344 val_loss:6.764882 train_time:7672891ms step_avg:590.59ms
|
| 219 |
+
step:13056/57344 val_loss:6.759225 train_time:7706508ms step_avg:590.27ms
|
| 220 |
+
step:13120/57344 val_loss:6.753849 train_time:7740094ms step_avg:589.95ms
|
| 221 |
+
step:13184/57344 val_loss:6.770496 train_time:7773638ms step_avg:589.63ms
|
| 222 |
+
step:13248/57344 val_loss:6.761217 train_time:7807221ms step_avg:589.31ms
|
| 223 |
+
step:13312/57344 val_loss:6.756414 train_time:7841096ms step_avg:589.02ms
|
| 224 |
+
step:13376/57344 val_loss:6.762049 train_time:7874707ms step_avg:588.72ms
|
| 225 |
+
step:13440/57344 val_loss:6.750922 train_time:7908217ms step_avg:588.41ms
|
| 226 |
+
step:13504/57344 val_loss:6.759320 train_time:7941775ms step_avg:588.11ms
|
| 227 |
+
step:13568/57344 val_loss:6.764692 train_time:7975314ms step_avg:587.80ms
|
| 228 |
+
step:13632/57344 val_loss:6.766222 train_time:8008979ms step_avg:587.51ms
|
| 229 |
+
step:13696/57344 val_loss:6.771569 train_time:8042565ms step_avg:587.22ms
|
| 230 |
+
step:13760/57344 val_loss:6.767988 train_time:8076045ms step_avg:586.92ms
|
| 231 |
+
step:13824/57344 val_loss:6.757222 train_time:8109635ms step_avg:586.63ms
|
| 232 |
+
step:13888/57344 val_loss:6.789327 train_time:8143163ms step_avg:586.35ms
|
| 233 |
+
step:13952/57344 val_loss:6.772260 train_time:8176985ms step_avg:586.08ms
|
| 234 |
+
step:14016/57344 val_loss:6.775136 train_time:8210509ms step_avg:585.80ms
|
| 235 |
+
step:14080/57344 val_loss:6.769068 train_time:8244051ms step_avg:585.51ms
|
| 236 |
+
step:14144/57344 val_loss:6.781752 train_time:8277687ms step_avg:585.24ms
|
| 237 |
+
step:14208/57344 val_loss:6.777571 train_time:8311198ms step_avg:584.97ms
|
| 238 |
+
step:14272/57344 val_loss:6.772471 train_time:8344672ms step_avg:584.69ms
|
| 239 |
+
step:14336/57344 val_loss:6.780034 train_time:8381430ms step_avg:584.64ms
|
| 240 |
+
step:14400/57344 val_loss:6.792025 train_time:8415143ms step_avg:584.38ms
|
| 241 |
+
step:14464/57344 val_loss:6.779392 train_time:8448750ms step_avg:584.12ms
|
| 242 |
+
step:14528/57344 val_loss:6.787096 train_time:8482489ms step_avg:583.87ms
|
| 243 |
+
step:14592/57344 val_loss:6.773287 train_time:8515967ms step_avg:583.61ms
|
| 244 |
+
step:14656/57344 val_loss:6.783534 train_time:8549604ms step_avg:583.35ms
|
| 245 |
+
step:14720/57344 val_loss:6.806825 train_time:8601441ms step_avg:584.34ms
|
| 246 |
+
step:14784/57344 val_loss:6.786703 train_time:8635020ms step_avg:584.08ms
|
| 247 |
+
step:14848/57344 val_loss:6.803151 train_time:8669040ms step_avg:583.85ms
|
| 248 |
+
step:14912/57344 val_loss:6.791473 train_time:8713418ms step_avg:584.32ms
|
| 249 |
+
step:14976/57344 val_loss:6.801820 train_time:8778381ms step_avg:586.16ms
|
| 250 |
+
step:15040/57344 val_loss:6.810283 train_time:8812487ms step_avg:585.94ms
|
| 251 |
+
step:15104/57344 val_loss:6.793823 train_time:8846120ms step_avg:585.68ms
|
| 252 |
+
step:15168/57344 val_loss:6.816493 train_time:8879981ms step_avg:585.44ms
|
| 253 |
+
step:15232/57344 val_loss:6.796839 train_time:8913529ms step_avg:585.18ms
|
| 254 |
+
step:15296/57344 val_loss:6.805776 train_time:8947193ms step_avg:584.94ms
|
| 255 |
+
step:15360/57344 val_loss:6.809866 train_time:8980797ms step_avg:584.69ms
|
| 256 |
+
step:15424/57344 val_loss:6.811370 train_time:9014549ms step_avg:584.45ms
|
| 257 |
+
step:15488/57344 val_loss:6.804217 train_time:9048182ms step_avg:584.21ms
|
| 258 |
+
step:15552/57344 val_loss:6.798154 train_time:9088253ms step_avg:584.38ms
|
| 259 |
+
step:15616/57344 val_loss:6.791600 train_time:9121598ms step_avg:584.12ms
|
| 260 |
+
step:15680/57344 val_loss:6.777744 train_time:9155248ms step_avg:583.88ms
|
| 261 |
+
step:15744/57344 val_loss:6.765359 train_time:9188907ms step_avg:583.65ms
|
| 262 |
+
step:15808/57344 val_loss:6.745915 train_time:9222757ms step_avg:583.42ms
|
| 263 |
+
step:15872/57344 val_loss:6.722579 train_time:9256376ms step_avg:583.19ms
|
| 264 |
+
step:15936/57344 val_loss:6.718524 train_time:9290043ms step_avg:582.96ms
|
| 265 |
+
step:16000/57344 val_loss:6.762109 train_time:9323720ms step_avg:582.73ms
|
| 266 |
+
step:16064/57344 val_loss:6.754011 train_time:9358025ms step_avg:582.55ms
|
| 267 |
+
step:16128/57344 val_loss:6.763496 train_time:9391628ms step_avg:582.32ms
|
| 268 |
+
step:16192/57344 val_loss:6.770032 train_time:9425434ms step_avg:582.10ms
|
| 269 |
+
step:16256/57344 val_loss:6.806127 train_time:9459225ms step_avg:581.89ms
|
| 270 |
+
step:16320/57344 val_loss:6.793598 train_time:9492808ms step_avg:581.67ms
|
| 271 |
+
step:16384/57344 val_loss:6.812854 train_time:9526467ms step_avg:581.45ms
|
| 272 |
+
step:16448/57344 val_loss:6.807650 train_time:9561269ms step_avg:581.30ms
|
| 273 |
+
step:16512/57344 val_loss:6.819201 train_time:9595723ms step_avg:581.14ms
|
| 274 |
+
step:16576/57344 val_loss:6.821900 train_time:9629341ms step_avg:580.92ms
|
| 275 |
+
step:16640/57344 val_loss:6.835638 train_time:9663013ms step_avg:580.71ms
|
| 276 |
+
step:16704/57344 val_loss:6.838716 train_time:9698661ms step_avg:580.62ms
|
| 277 |
+
step:16768/57344 val_loss:6.850279 train_time:9732409ms step_avg:580.42ms
|
| 278 |
+
step:16832/57344 val_loss:6.851334 train_time:9766062ms step_avg:580.21ms
|
| 279 |
+
step:16896/57344 val_loss:6.866141 train_time:9799817ms step_avg:580.01ms
|
| 280 |
+
step:16960/57344 val_loss:6.858786 train_time:9833416ms step_avg:579.80ms
|
| 281 |
+
step:17024/57344 val_loss:6.862143 train_time:9894785ms step_avg:581.23ms
|
| 282 |
+
step:17088/57344 val_loss:6.874677 train_time:9988794ms step_avg:584.55ms
|
| 283 |
+
step:17152/57344 val_loss:6.874232 train_time:10022391ms step_avg:584.33ms
|
| 284 |
+
step:17216/57344 val_loss:6.878744 train_time:10055947ms step_avg:584.10ms
|
| 285 |
+
step:17280/57344 val_loss:6.877972 train_time:10089520ms step_avg:583.88ms
|
| 286 |
+
step:17344/57344 val_loss:6.898927 train_time:10123166ms step_avg:583.67ms
|
| 287 |
+
step:17408/57344 val_loss:6.921997 train_time:10164603ms step_avg:583.90ms
|
| 288 |
+
step:17472/57344 val_loss:6.906083 train_time:10198133ms step_avg:583.68ms
|
| 289 |
+
step:17536/57344 val_loss:6.916491 train_time:10231842ms step_avg:583.48ms
|
| 290 |
+
step:17600/57344 val_loss:6.908957 train_time:10265419ms step_avg:583.26ms
|
| 291 |
+
step:17664/57344 val_loss:6.902090 train_time:10299128ms step_avg:583.06ms
|
| 292 |
+
step:17728/57344 val_loss:6.908919 train_time:10342415ms step_avg:583.39ms
|
| 293 |
+
step:17792/57344 val_loss:6.925640 train_time:10396280ms step_avg:584.32ms
|
| 294 |
+
step:17856/57344 val_loss:6.928489 train_time:10457087ms step_avg:585.63ms
|
| 295 |
+
step:17920/57344 val_loss:6.934070 train_time:10490607ms step_avg:585.41ms
|
| 296 |
+
step:17984/57344 val_loss:6.948156 train_time:10524265ms step_avg:585.20ms
|
| 297 |
+
step:18048/57344 val_loss:6.952826 train_time:10558010ms step_avg:585.00ms
|
| 298 |
+
step:18112/57344 val_loss:6.956297 train_time:10591668ms step_avg:584.79ms
|
| 299 |
+
step:18176/57344 val_loss:6.964755 train_time:10716293ms step_avg:589.58ms
|
| 300 |
+
step:18240/57344 val_loss:6.981714 train_time:10749798ms step_avg:589.35ms
|
| 301 |
+
step:18304/57344 val_loss:6.982418 train_time:10783271ms step_avg:589.12ms
|
| 302 |
+
step:18368/57344 val_loss:7.002724 train_time:10817123ms step_avg:588.91ms
|
| 303 |
+
step:18432/57344 val_loss:7.004488 train_time:10858125ms step_avg:589.09ms
|
| 304 |
+
step:18496/57344 val_loss:7.008335 train_time:10896191ms step_avg:589.11ms
|
| 305 |
+
step:18560/57344 val_loss:7.001398 train_time:10929774ms step_avg:588.89ms
|
| 306 |
+
step:18624/57344 val_loss:6.994998 train_time:10965386ms step_avg:588.78ms
|
| 307 |
+
step:18688/57344 val_loss:6.993669 train_time:10999404ms step_avg:588.58ms
|
| 308 |
+
step:18752/57344 val_loss:6.993299 train_time:11045759ms step_avg:589.04ms
|
| 309 |
+
step:18816/57344 val_loss:6.991408 train_time:11079410ms step_avg:588.83ms
|
| 310 |
+
step:18880/57344 val_loss:6.994536 train_time:11113010ms step_avg:588.61ms
|
| 311 |
+
step:18944/57344 val_loss:6.994389 train_time:11146692ms step_avg:588.40ms
|
| 312 |
+
step:19008/57344 val_loss:6.993626 train_time:11180216ms step_avg:588.18ms
|
| 313 |
+
step:19072/57344 val_loss:6.999786 train_time:11213835ms step_avg:587.97ms
|
| 314 |
+
step:19136/57344 val_loss:6.992972 train_time:11247532ms step_avg:587.77ms
|
| 315 |
+
step:19200/57344 val_loss:6.989506 train_time:11281399ms step_avg:587.57ms
|
| 316 |
+
step:19264/57344 val_loss:7.006613 train_time:11315389ms step_avg:587.39ms
|
| 317 |
+
step:19328/57344 val_loss:7.000946 train_time:11350342ms step_avg:587.25ms
|
| 318 |
+
step:19392/57344 val_loss:6.998974 train_time:11389000ms step_avg:587.30ms
|
| 319 |
+
step:19456/57344 val_loss:7.010986 train_time:11422963ms step_avg:587.12ms
|
| 320 |
+
step:19520/57344 val_loss:7.025891 train_time:11459182ms step_avg:587.05ms
|
| 321 |
+
step:19584/57344 val_loss:6.998867 train_time:11498732ms step_avg:587.15ms
|
| 322 |
+
step:19648/57344 val_loss:7.006006 train_time:11532745ms step_avg:586.97ms
|
| 323 |
+
step:19712/57344 val_loss:7.039533 train_time:11566905ms step_avg:586.80ms
|
| 324 |
+
step:19776/57344 val_loss:7.015204 train_time:11601196ms step_avg:586.63ms
|
| 325 |
+
step:19840/57344 val_loss:7.008238 train_time:11635205ms step_avg:586.45ms
|
| 326 |
+
step:19904/57344 val_loss:7.005112 train_time:11669015ms step_avg:586.26ms
|
| 327 |
+
step:19968/57344 val_loss:7.013822 train_time:11703061ms step_avg:586.09ms
|
| 328 |
+
step:20032/57344 val_loss:7.006802 train_time:11737042ms step_avg:585.91ms
|
| 329 |
+
step:20096/57344 val_loss:7.017865 train_time:11771221ms step_avg:585.75ms
|
| 330 |
+
step:20160/57344 val_loss:7.015147 train_time:11805067ms step_avg:585.57ms
|
| 331 |
+
step:20224/57344 val_loss:7.019801 train_time:11839001ms step_avg:585.39ms
|
| 332 |
+
step:20288/57344 val_loss:7.012786 train_time:11883321ms step_avg:585.73ms
|
| 333 |
+
step:20352/57344 val_loss:7.009954 train_time:11917286ms step_avg:585.56ms
|
| 334 |
+
step:20416/57344 val_loss:7.017318 train_time:11951349ms step_avg:585.39ms
|
| 335 |
+
step:20480/57344 val_loss:7.022078 train_time:11985754ms step_avg:585.24ms
|
| 336 |
+
step:20544/57344 val_loss:7.030802 train_time:12019788ms step_avg:585.08ms
|
| 337 |
+
step:20608/57344 val_loss:7.019706 train_time:12053934ms step_avg:584.92ms
|
| 338 |
+
step:20672/57344 val_loss:7.024773 train_time:12088203ms step_avg:584.76ms
|
| 339 |
+
step:20736/57344 val_loss:7.032852 train_time:12122281ms step_avg:584.60ms
|
| 340 |
+
step:20800/57344 val_loss:7.021889 train_time:12156197ms step_avg:584.43ms
|
| 341 |
+
step:20864/57344 val_loss:7.018207 train_time:12190069ms step_avg:584.26ms
|
| 342 |
+
step:20928/57344 val_loss:7.020712 train_time:12237157ms step_avg:584.73ms
|
| 343 |
+
step:20992/57344 val_loss:7.029232 train_time:12271103ms step_avg:584.56ms
|
| 344 |
+
step:21056/57344 val_loss:7.028652 train_time:12305393ms step_avg:584.41ms
|
| 345 |
+
step:21120/57344 val_loss:7.018156 train_time:12339382ms step_avg:584.25ms
|
| 346 |
+
step:21184/57344 val_loss:7.007094 train_time:12373424ms step_avg:584.09ms
|
| 347 |
+
step:21248/57344 val_loss:7.012620 train_time:12407456ms step_avg:583.94ms
|
| 348 |
+
step:21312/57344 val_loss:7.001192 train_time:12441926ms step_avg:583.80ms
|
| 349 |
+
step:21376/57344 val_loss:7.009300 train_time:12476082ms step_avg:583.65ms
|
| 350 |
+
step:21440/57344 val_loss:6.929464 train_time:12510176ms step_avg:583.50ms
|
| 351 |
+
step:21504/57344 val_loss:6.897208 train_time:12580068ms step_avg:585.01ms
|
| 352 |
+
step:21568/57344 val_loss:6.871654 train_time:12613846ms step_avg:584.84ms
|
| 353 |
+
step:21632/57344 val_loss:6.841313 train_time:12647731ms step_avg:584.68ms
|
| 354 |
+
step:21696/57344 val_loss:6.823667 train_time:12682029ms step_avg:584.53ms
|
| 355 |
+
step:21760/57344 val_loss:6.782926 train_time:12716265ms step_avg:584.39ms
|
| 356 |
+
step:21824/57344 val_loss:6.754741 train_time:12750401ms step_avg:584.24ms
|
| 357 |
+
step:21888/57344 val_loss:6.727941 train_time:12784452ms step_avg:584.08ms
|
| 358 |
+
step:21952/57344 val_loss:6.702205 train_time:12818406ms step_avg:583.93ms
|
| 359 |
+
step:22016/57344 val_loss:6.669182 train_time:12852467ms step_avg:583.78ms
|
| 360 |
+
step:22080/57344 val_loss:6.655616 train_time:12886693ms step_avg:583.64ms
|
| 361 |
+
step:22144/57344 val_loss:6.619743 train_time:12920714ms step_avg:583.49ms
|
| 362 |
+
step:22208/57344 val_loss:6.601605 train_time:12954797ms step_avg:583.34ms
|
| 363 |
+
step:22272/57344 val_loss:6.576770 train_time:12988989ms step_avg:583.20ms
|
| 364 |
+
step:22336/57344 val_loss:6.559417 train_time:13023400ms step_avg:583.07ms
|
| 365 |
+
step:22400/57344 val_loss:6.537297 train_time:13057562ms step_avg:582.93ms
|
| 366 |
+
step:22464/57344 val_loss:6.502707 train_time:13091632ms step_avg:582.78ms
|
| 367 |
+
step:22528/57344 val_loss:6.483665 train_time:13125593ms step_avg:582.63ms
|
| 368 |
+
step:22592/57344 val_loss:6.478091 train_time:13159907ms step_avg:582.50ms
|
| 369 |
+
step:22656/57344 val_loss:6.442571 train_time:13193948ms step_avg:582.36ms
|
| 370 |
+
step:22720/57344 val_loss:6.423617 train_time:13228052ms step_avg:582.22ms
|
| 371 |
+
step:22784/57344 val_loss:6.400871 train_time:13263097ms step_avg:582.12ms
|
| 372 |
+
step:22848/57344 val_loss:6.387420 train_time:13297265ms step_avg:581.99ms
|
| 373 |
+
step:22912/57344 val_loss:6.355561 train_time:13331270ms step_avg:581.85ms
|
| 374 |
+
step:22976/57344 val_loss:6.372940 train_time:13365365ms step_avg:581.71ms
|
| 375 |
+
step:23040/57344 val_loss:6.555444 train_time:13399520ms step_avg:581.58ms
|
| 376 |
+
step:23104/57344 val_loss:6.459857 train_time:13433496ms step_avg:581.44ms
|
| 377 |
+
step:23168/57344 val_loss:6.471203 train_time:13467558ms step_avg:581.30ms
|
| 378 |
+
step:23232/57344 val_loss:6.495924 train_time:13501596ms step_avg:581.16ms
|
| 379 |
+
step:23296/57344 val_loss:6.520335 train_time:13535567ms step_avg:581.03ms
|
| 380 |
+
step:23360/57344 val_loss:6.560977 train_time:13570655ms step_avg:580.94ms
|
| 381 |
+
step:23424/57344 val_loss:6.593538 train_time:13604604ms step_avg:580.80ms
|
| 382 |
+
step:23488/57344 val_loss:6.620380 train_time:13638686ms step_avg:580.67ms
|
| 383 |
+
step:23552/57344 val_loss:6.638693 train_time:13672576ms step_avg:580.53ms
|
| 384 |
+
step:23616/57344 val_loss:6.671075 train_time:13707830ms step_avg:580.45ms
|
| 385 |
+
step:23680/57344 val_loss:6.708018 train_time:13742033ms step_avg:580.32ms
|
| 386 |
+
step:23744/57344 val_loss:6.725985 train_time:13776077ms step_avg:580.19ms
|
| 387 |
+
step:23808/57344 val_loss:6.749393 train_time:13809949ms step_avg:580.05ms
|
| 388 |
+
step:23872/57344 val_loss:6.786535 train_time:13844173ms step_avg:579.93ms
|
| 389 |
+
step:23936/57344 val_loss:6.791564 train_time:13878236ms step_avg:579.81ms
|
| 390 |
+
step:24000/57344 val_loss:6.813724 train_time:13912361ms step_avg:579.68ms
|
| 391 |
+
step:24064/57344 val_loss:6.825016 train_time:13946256ms step_avg:579.55ms
|
| 392 |
+
step:24128/57344 val_loss:6.843540 train_time:13980345ms step_avg:579.42ms
|
| 393 |
+
step:24192/57344 val_loss:6.861302 train_time:14014405ms step_avg:579.30ms
|
| 394 |
+
step:24256/57344 val_loss:6.871196 train_time:14048288ms step_avg:579.17ms
|
| 395 |
+
step:24320/57344 val_loss:6.885727 train_time:14082307ms step_avg:579.04ms
|
| 396 |
+
step:24384/57344 val_loss:6.892621 train_time:14116283ms step_avg:578.92ms
|
| 397 |
+
step:24448/57344 val_loss:6.903215 train_time:14150403ms step_avg:578.80ms
|
| 398 |
+
step:24512/57344 val_loss:6.909631 train_time:14184433ms step_avg:578.67ms
|
| 399 |
+
step:24576/57344 val_loss:6.941854 train_time:14218493ms step_avg:578.55ms
|
| 400 |
+
step:24640/57344 val_loss:6.927251 train_time:14252531ms step_avg:578.43ms
|
| 401 |
+
step:24704/57344 val_loss:6.931237 train_time:14286629ms step_avg:578.31ms
|
| 402 |
+
step:24768/57344 val_loss:6.934501 train_time:14320684ms step_avg:578.19ms
|
| 403 |
+
step:24832/57344 val_loss:6.946264 train_time:14354929ms step_avg:578.08ms
|
| 404 |
+
step:24896/57344 val_loss:6.943892 train_time:14388776ms step_avg:577.96ms
|
| 405 |
+
step:24960/57344 val_loss:6.948223 train_time:14423012ms step_avg:577.85ms
|
| 406 |
+
step:25024/57344 val_loss:6.962749 train_time:14457220ms step_avg:577.73ms
|
| 407 |
+
step:25088/57344 val_loss:6.961961 train_time:14491559ms step_avg:577.63ms
|
| 408 |
+
step:25152/57344 val_loss:6.960940 train_time:14525474ms step_avg:577.51ms
|
| 409 |
+
step:25216/57344 val_loss:6.965730 train_time:14559412ms step_avg:577.39ms
|
| 410 |
+
step:25280/57344 val_loss:6.967648 train_time:14593239ms step_avg:577.26ms
|
| 411 |
+
step:25344/57344 val_loss:6.969640 train_time:14627325ms step_avg:577.15ms
|
| 412 |
+
step:25408/57344 val_loss:6.972083 train_time:14661340ms step_avg:577.04ms
|
| 413 |
+
step:25472/57344 val_loss:6.974039 train_time:14695376ms step_avg:576.92ms
|
| 414 |
+
step:25536/57344 val_loss:6.971818 train_time:14729223ms step_avg:576.80ms
|
| 415 |
+
step:25600/57344 val_loss:6.970633 train_time:14763175ms step_avg:576.69ms
|
| 416 |
+
step:25664/57344 val_loss:6.974714 train_time:14797341ms step_avg:576.58ms
|
| 417 |
+
step:25728/57344 val_loss:6.965921 train_time:14831512ms step_avg:576.47ms
|
| 418 |
+
step:25792/57344 val_loss:6.967148 train_time:14865523ms step_avg:576.36ms
|
| 419 |
+
step:25856/57344 val_loss:6.922833 train_time:14899799ms step_avg:576.26ms
|
| 420 |
+
step:25920/57344 val_loss:6.888264 train_time:14933768ms step_avg:576.15ms
|
| 421 |
+
step:25984/57344 val_loss:6.852927 train_time:14967713ms step_avg:576.04ms
|
| 422 |
+
step:26048/57344 val_loss:6.810912 train_time:15001594ms step_avg:575.92ms
|
| 423 |
+
step:26112/57344 val_loss:6.771035 train_time:15035559ms step_avg:575.81ms
|
| 424 |
+
step:26176/57344 val_loss:6.736585 train_time:15069495ms step_avg:575.70ms
|
| 425 |
+
step:26240/57344 val_loss:6.730480 train_time:15103654ms step_avg:575.60ms
|
| 426 |
+
step:26304/57344 val_loss:6.670739 train_time:15137848ms step_avg:575.50ms
|
| 427 |
+
step:26368/57344 val_loss:6.646334 train_time:15172143ms step_avg:575.40ms
|
| 428 |
+
step:26432/57344 val_loss:6.608521 train_time:15205903ms step_avg:575.28ms
|
| 429 |
+
step:26496/57344 val_loss:6.570975 train_time:15239840ms step_avg:575.18ms
|
| 430 |
+
step:26560/57344 val_loss:6.545394 train_time:15273686ms step_avg:575.06ms
|
| 431 |
+
step:26624/57344 val_loss:6.524185 train_time:15307714ms step_avg:574.96ms
|
| 432 |
+
step:26688/57344 val_loss:6.516870 train_time:15341911ms step_avg:574.86ms
|
| 433 |
+
step:26752/57344 val_loss:6.475085 train_time:15375757ms step_avg:574.75ms
|
| 434 |
+
step:26816/57344 val_loss:6.453985 train_time:15409750ms step_avg:574.65ms
|
| 435 |
+
step:26880/57344 val_loss:6.431835 train_time:15443581ms step_avg:574.54ms
|
| 436 |
+
step:26944/57344 val_loss:6.417792 train_time:15477675ms step_avg:574.44ms
|
| 437 |
+
step:27008/57344 val_loss:6.393958 train_time:15513483ms step_avg:574.40ms
|
| 438 |
+
step:27072/57344 val_loss:6.372041 train_time:15547728ms step_avg:574.31ms
|
| 439 |
+
step:27136/57344 val_loss:6.353952 train_time:15589757ms step_avg:574.50ms
|
| 440 |
+
step:27200/57344 val_loss:6.338624 train_time:15623843ms step_avg:574.41ms
|
| 441 |
+
step:27264/57344 val_loss:6.322062 train_time:15657958ms step_avg:574.31ms
|
| 442 |
+
step:27328/57344 val_loss:6.298830 train_time:15691977ms step_avg:574.21ms
|
| 443 |
+
step:27392/57344 val_loss:6.284842 train_time:15726187ms step_avg:574.12ms
|
| 444 |
+
step:27456/57344 val_loss:6.270062 train_time:15768088ms step_avg:574.30ms
|
| 445 |
+
step:27520/57344 val_loss:6.253415 train_time:15802041ms step_avg:574.20ms
|
| 446 |
+
step:27584/57344 val_loss:6.233905 train_time:15835982ms step_avg:574.10ms
|
| 447 |
+
step:27648/57344 val_loss:6.221201 train_time:15869896ms step_avg:574.00ms
|
| 448 |
+
step:27712/57344 val_loss:6.225038 train_time:15903749ms step_avg:573.89ms
|
| 449 |
+
step:27776/57344 val_loss:6.246658 train_time:15937582ms step_avg:573.79ms
|
| 450 |
+
step:27840/57344 val_loss:6.280988 train_time:15971602ms step_avg:573.69ms
|
| 451 |
+
step:27904/57344 val_loss:6.312466 train_time:16005608ms step_avg:573.60ms
|
| 452 |
+
step:27968/57344 val_loss:6.351825 train_time:16039606ms step_avg:573.50ms
|
| 453 |
+
step:28032/57344 val_loss:6.371429 train_time:16093155ms step_avg:574.10ms
|
| 454 |
+
step:28096/57344 val_loss:6.407415 train_time:16158594ms step_avg:575.12ms
|
| 455 |
+
step:28160/57344 val_loss:6.420421 train_time:16192635ms step_avg:575.02ms
|
| 456 |
+
step:28224/57344 val_loss:6.439218 train_time:16226520ms step_avg:574.92ms
|
| 457 |
+
step:28288/57344 val_loss:6.458371 train_time:16260581ms step_avg:574.82ms
|
| 458 |
+
step:28352/57344 val_loss:6.471800 train_time:16294696ms step_avg:574.73ms
|
| 459 |
+
step:28416/57344 val_loss:6.487670 train_time:16328880ms step_avg:574.64ms
|
| 460 |
+
step:28480/57344 val_loss:6.491364 train_time:16363110ms step_avg:574.55ms
|
| 461 |
+
step:28544/57344 val_loss:6.495669 train_time:16397167ms step_avg:574.45ms
|
| 462 |
+
step:28608/57344 val_loss:6.496770 train_time:16431164ms step_avg:574.36ms
|
| 463 |
+
step:28672/57344 val_loss:6.499097 train_time:16465240ms step_avg:574.26ms
|
| 464 |
+
step:28736/57344 val_loss:6.498493 train_time:16499564ms step_avg:574.18ms
|
| 465 |
+
step:28800/57344 val_loss:6.493935 train_time:16533631ms step_avg:574.08ms
|
| 466 |
+
step:28864/57344 val_loss:6.495569 train_time:16567805ms step_avg:574.00ms
|
| 467 |
+
step:28928/57344 val_loss:6.491815 train_time:16601894ms step_avg:573.90ms
|
| 468 |
+
step:28992/57344 val_loss:6.487421 train_time:16636259ms step_avg:573.82ms
|
| 469 |
+
step:29056/57344 val_loss:6.480526 train_time:16672426ms step_avg:573.80ms
|
| 470 |
+
step:29120/57344 val_loss:6.472998 train_time:16706354ms step_avg:573.71ms
|
| 471 |
+
step:29184/57344 val_loss:6.470836 train_time:16740297ms step_avg:573.61ms
|
| 472 |
+
step:29248/57344 val_loss:6.461094 train_time:16774150ms step_avg:573.51ms
|
| 473 |
+
step:29312/57344 val_loss:6.463924 train_time:16810211ms step_avg:573.49ms
|
| 474 |
+
step:29376/57344 val_loss:6.455650 train_time:16844223ms step_avg:573.40ms
|
| 475 |
+
step:29440/57344 val_loss:6.455267 train_time:16878323ms step_avg:573.31ms
|
| 476 |
+
step:29504/57344 val_loss:6.452744 train_time:16912458ms step_avg:573.23ms
|
| 477 |
+
step:29568/57344 val_loss:6.450254 train_time:16946562ms step_avg:573.14ms
|
| 478 |
+
step:29632/57344 val_loss:6.448990 train_time:16980672ms step_avg:573.05ms
|
| 479 |
+
step:29696/57344 val_loss:6.447800 train_time:17014854ms step_avg:572.97ms
|
| 480 |
+
step:29760/57344 val_loss:6.440109 train_time:17048931ms step_avg:572.88ms
|
| 481 |
+
step:29824/57344 val_loss:6.438864 train_time:17083546ms step_avg:572.81ms
|
| 482 |
+
step:29888/57344 val_loss:6.435298 train_time:17117505ms step_avg:572.72ms
|
| 483 |
+
step:29952/57344 val_loss:6.433727 train_time:17151591ms step_avg:572.64ms
|
| 484 |
+
step:30016/57344 val_loss:6.450425 train_time:17185884ms step_avg:572.56ms
|
| 485 |
+
step:30080/57344 val_loss:6.421892 train_time:17220054ms step_avg:572.48ms
|
| 486 |
+
step:30144/57344 val_loss:6.429942 train_time:17258882ms step_avg:572.55ms
|
| 487 |
+
step:30208/57344 val_loss:6.392270 train_time:17292891ms step_avg:572.46ms
|
| 488 |
+
step:30272/57344 val_loss:6.373115 train_time:17326876ms step_avg:572.37ms
|
| 489 |
+
step:30336/57344 val_loss:6.355168 train_time:17360840ms step_avg:572.29ms
|
| 490 |
+
step:30400/57344 val_loss:6.326638 train_time:17396376ms step_avg:572.25ms
|
| 491 |
+
step:30464/57344 val_loss:6.320801 train_time:17430568ms step_avg:572.17ms
|
| 492 |
+
step:30528/57344 val_loss:6.297551 train_time:17464938ms step_avg:572.10ms
|
| 493 |
+
step:30592/57344 val_loss:6.274022 train_time:17498999ms step_avg:572.01ms
|
| 494 |
+
step:30656/57344 val_loss:6.243879 train_time:17532860ms step_avg:571.92ms
|
| 495 |
+
step:30720/57344 val_loss:6.233229 train_time:17566949ms step_avg:571.84ms
|
| 496 |
+
step:30784/57344 val_loss:6.208236 train_time:17603383ms step_avg:571.84ms
|
| 497 |
+
step:30848/57344 val_loss:6.192863 train_time:17637615ms step_avg:571.76ms
|
| 498 |
+
step:30912/57344 val_loss:6.175398 train_time:17671507ms step_avg:571.67ms
|
| 499 |
+
step:30976/57344 val_loss:6.153916 train_time:17705483ms step_avg:571.59ms
|
| 500 |
+
step:31040/57344 val_loss:6.139095 train_time:17739547ms step_avg:571.51ms
|
| 501 |
+
step:31104/57344 val_loss:6.127968 train_time:17773591ms step_avg:571.42ms
|
| 502 |
+
step:31168/57344 val_loss:6.104289 train_time:17812380ms step_avg:571.50ms
|
| 503 |
+
step:31232/57344 val_loss:6.088856 train_time:17846246ms step_avg:571.41ms
|
| 504 |
+
step:31296/57344 val_loss:6.078449 train_time:17880202ms step_avg:571.33ms
|
| 505 |
+
step:31360/57344 val_loss:6.055421 train_time:17914090ms step_avg:571.24ms
|
| 506 |
+
step:31424/57344 val_loss:6.046597 train_time:17947859ms step_avg:571.15ms
|
| 507 |
+
step:31488/57344 val_loss:6.036800 train_time:17981874ms step_avg:571.07ms
|
| 508 |
+
step:31552/57344 val_loss:6.014101 train_time:18015676ms step_avg:570.98ms
|
| 509 |
+
step:31616/57344 val_loss:6.005621 train_time:18049535ms step_avg:570.90ms
|
| 510 |
+
step:31680/57344 val_loss:6.021158 train_time:18083510ms step_avg:570.82ms
|
| 511 |
+
step:31744/57344 val_loss:6.030588 train_time:18117652ms step_avg:570.74ms
|
| 512 |
+
step:31808/57344 val_loss:6.041026 train_time:18151738ms step_avg:570.67ms
|
| 513 |
+
step:31872/57344 val_loss:6.059294 train_time:18186025ms step_avg:570.60ms
|
| 514 |
+
step:31936/57344 val_loss:6.074324 train_time:18220069ms step_avg:570.52ms
|
| 515 |
+
step:32000/57344 val_loss:6.097003 train_time:18254013ms step_avg:570.44ms
|
| 516 |
+
step:32064/57344 val_loss:6.111945 train_time:18289949ms step_avg:570.42ms
|
| 517 |
+
step:32128/57344 val_loss:6.132194 train_time:18323886ms step_avg:570.34ms
|
| 518 |
+
step:32192/57344 val_loss:6.154255 train_time:18357872ms step_avg:570.26ms
|
| 519 |
+
step:32256/57344 val_loss:6.176447 train_time:18391860ms step_avg:570.18ms
|
| 520 |
+
step:32320/57344 val_loss:6.193738 train_time:18425770ms step_avg:570.10ms
|
| 521 |
+
step:32384/57344 val_loss:6.210797 train_time:18461908ms step_avg:570.09ms
|
| 522 |
+
step:32448/57344 val_loss:6.225993 train_time:18495810ms step_avg:570.01ms
|
| 523 |
+
step:32512/57344 val_loss:6.246869 train_time:18529684ms step_avg:569.93ms
|
| 524 |
+
step:32576/57344 val_loss:6.263676 train_time:18563669ms step_avg:569.86ms
|
| 525 |
+
step:32640/57344 val_loss:6.276979 train_time:18610784ms step_avg:570.18ms
|
| 526 |
+
step:32704/57344 val_loss:6.297549 train_time:18690503ms step_avg:571.51ms
|
| 527 |
+
step:32768/57344 val_loss:6.321110 train_time:18724630ms step_avg:571.43ms
|
| 528 |
+
step:32832/57344 val_loss:6.319574 train_time:18758748ms step_avg:571.36ms
|
| 529 |
+
step:32896/57344 val_loss:6.337848 train_time:18792940ms step_avg:571.28ms
|
| 530 |
+
step:32960/57344 val_loss:6.347533 train_time:18827088ms step_avg:571.21ms
|
| 531 |
+
step:33024/57344 val_loss:6.363330 train_time:18862601ms step_avg:571.18ms
|
| 532 |
+
step:33088/57344 val_loss:6.366555 train_time:18896556ms step_avg:571.10ms
|
| 533 |
+
step:33152/57344 val_loss:6.381602 train_time:18930496ms step_avg:571.02ms
|
| 534 |
+
step:33216/57344 val_loss:6.383929 train_time:18964364ms step_avg:570.94ms
|
| 535 |
+
step:33280/57344 val_loss:6.393970 train_time:19074756ms step_avg:573.16ms
|
| 536 |
+
step:33344/57344 val_loss:6.404038 train_time:19127971ms step_avg:573.66ms
|
| 537 |
+
step:33408/57344 val_loss:6.407627 train_time:19161802ms step_avg:573.57ms
|
| 538 |
+
step:33472/57344 val_loss:6.429492 train_time:19195995ms step_avg:573.49ms
|
| 539 |
+
step:33536/57344 val_loss:6.421330 train_time:19229887ms step_avg:573.41ms
|
| 540 |
+
step:33600/57344 val_loss:6.433446 train_time:19263823ms step_avg:573.33ms
|
| 541 |
+
step:33664/57344 val_loss:6.436284 train_time:19298011ms step_avg:573.25ms
|
| 542 |
+
step:33728/57344 val_loss:6.445465 train_time:19332092ms step_avg:573.18ms
|
| 543 |
+
step:33792/57344 val_loss:6.442889 train_time:19366003ms step_avg:573.09ms
|
| 544 |
+
step:33856/57344 val_loss:6.447213 train_time:19399918ms step_avg:573.01ms
|
| 545 |
+
step:33920/57344 val_loss:6.447993 train_time:19433846ms step_avg:572.93ms
|
| 546 |
+
step:33984/57344 val_loss:6.453583 train_time:19469827ms step_avg:572.91ms
|
| 547 |
+
step:34048/57344 val_loss:6.454758 train_time:19503987ms step_avg:572.84ms
|
| 548 |
+
step:34112/57344 val_loss:6.444719 train_time:19537802ms step_avg:572.75ms
|
| 549 |
+
step:34176/57344 val_loss:6.436030 train_time:19571893ms step_avg:572.68ms
|
| 550 |
+
step:34240/57344 val_loss:6.419268 train_time:19607349ms step_avg:572.64ms
|
| 551 |
+
step:34304/57344 val_loss:6.396570 train_time:19643605ms step_avg:572.63ms
|
| 552 |
+
step:34368/57344 val_loss:6.378235 train_time:19677684ms step_avg:572.56ms
|
| 553 |
+
step:34432/57344 val_loss:6.352869 train_time:19711674ms step_avg:572.48ms
|
| 554 |
+
step:34496/57344 val_loss:6.326517 train_time:19745820ms step_avg:572.41ms
|
| 555 |
+
step:34560/57344 val_loss:6.299848 train_time:19779775ms step_avg:572.33ms
|
| 556 |
+
step:34624/57344 val_loss:6.275382 train_time:19813842ms step_avg:572.26ms
|
| 557 |
+
step:34688/57344 val_loss:6.239287 train_time:19847898ms step_avg:572.18ms
|
| 558 |
+
step:34752/57344 val_loss:6.222122 train_time:19882034ms step_avg:572.11ms
|
| 559 |
+
step:34816/57344 val_loss:6.199553 train_time:19916253ms step_avg:572.04ms
|
| 560 |
+
step:34880/57344 val_loss:6.168828 train_time:19950300ms step_avg:571.97ms
|
| 561 |
+
step:34944/57344 val_loss:6.146615 train_time:19984595ms step_avg:571.90ms
|
| 562 |
+
step:35008/57344 val_loss:6.132919 train_time:20018805ms step_avg:571.84ms
|
| 563 |
+
step:35072/57344 val_loss:6.118301 train_time:20053076ms step_avg:571.77ms
|
| 564 |
+
step:35136/57344 val_loss:6.089632 train_time:20087191ms step_avg:571.70ms
|
| 565 |
+
step:35200/57344 val_loss:6.074313 train_time:20121263ms step_avg:571.63ms
|
| 566 |
+
step:35264/57344 val_loss:6.051312 train_time:20155222ms step_avg:571.55ms
|
| 567 |
+
step:35328/57344 val_loss:6.050741 train_time:20189539ms step_avg:571.49ms
|
| 568 |
+
step:35392/57344 val_loss:6.023050 train_time:20223647ms step_avg:571.42ms
|
| 569 |
+
step:35456/57344 val_loss:6.012047 train_time:20257875ms step_avg:571.35ms
|
| 570 |
+
step:35520/57344 val_loss:6.000558 train_time:20291931ms step_avg:571.28ms
|
| 571 |
+
step:35584/57344 val_loss:5.983496 train_time:20326001ms step_avg:571.21ms
|
| 572 |
+
step:35648/57344 val_loss:5.968700 train_time:20360067ms step_avg:571.14ms
|
| 573 |
+
step:35712/57344 val_loss:5.975152 train_time:20407470ms step_avg:571.45ms
|
| 574 |
+
step:35776/57344 val_loss:5.949347 train_time:20441302ms step_avg:571.37ms
|
| 575 |
+
step:35840/57344 val_loss:5.953311 train_time:20475595ms step_avg:571.31ms
|
| 576 |
+
step:35904/57344 val_loss:5.963206 train_time:20509716ms step_avg:571.24ms
|
| 577 |
+
step:35968/57344 val_loss:5.960691 train_time:20543756ms step_avg:571.17ms
|
| 578 |
+
step:36032/57344 val_loss:5.970256 train_time:20577836ms step_avg:571.10ms
|
| 579 |
+
step:36096/57344 val_loss:5.975174 train_time:20611835ms step_avg:571.03ms
|
| 580 |
+
step:36160/57344 val_loss:5.979783 train_time:20645639ms step_avg:570.95ms
|
| 581 |
+
step:36224/57344 val_loss:5.993697 train_time:20679675ms step_avg:570.88ms
|
| 582 |
+
step:36288/57344 val_loss:5.994636 train_time:20714144ms step_avg:570.83ms
|
| 583 |
+
step:36352/57344 val_loss:6.008160 train_time:20748389ms step_avg:570.76ms
|
| 584 |
+
step:36416/57344 val_loss:6.015017 train_time:20790767ms step_avg:570.92ms
|
| 585 |
+
step:36480/57344 val_loss:6.016824 train_time:20824497ms step_avg:570.85ms
|
| 586 |
+
step:36544/57344 val_loss:6.023655 train_time:20858353ms step_avg:570.77ms
|
| 587 |
+
step:36608/57344 val_loss:6.038690 train_time:20892492ms step_avg:570.71ms
|
| 588 |
+
step:36672/57344 val_loss:6.041234 train_time:20953342ms step_avg:571.37ms
|
| 589 |
+
step:36736/57344 val_loss:6.044783 train_time:20987288ms step_avg:571.30ms
|
| 590 |
+
step:36800/57344 val_loss:6.058211 train_time:21021907ms step_avg:571.25ms
|
| 591 |
+
step:36864/57344 val_loss:6.055545 train_time:21056047ms step_avg:571.18ms
|
| 592 |
+
step:36928/57344 val_loss:6.061031 train_time:21090075ms step_avg:571.11ms
|
| 593 |
+
step:36992/57344 val_loss:6.064785 train_time:21124167ms step_avg:571.05ms
|
| 594 |
+
step:37056/57344 val_loss:6.068419 train_time:21158473ms step_avg:570.99ms
|
| 595 |
+
step:37120/57344 val_loss:6.068573 train_time:21192804ms step_avg:570.93ms
|
| 596 |
+
step:37184/57344 val_loss:6.071270 train_time:21226650ms step_avg:570.85ms
|
| 597 |
+
step:37248/57344 val_loss:6.083017 train_time:21261708ms step_avg:570.81ms
|
| 598 |
+
step:37312/57344 val_loss:6.074487 train_time:21297127ms step_avg:570.78ms
|
| 599 |
+
step:37376/57344 val_loss:6.100016 train_time:21331383ms step_avg:570.72ms
|
| 600 |
+
step:37440/57344 val_loss:6.075029 train_time:21365422ms step_avg:570.66ms
|
| 601 |
+
step:37504/57344 val_loss:6.075674 train_time:21399384ms step_avg:570.59ms
|
| 602 |
+
step:37568/57344 val_loss:6.078236 train_time:21433537ms step_avg:570.53ms
|
| 603 |
+
step:37632/57344 val_loss:6.075828 train_time:21467578ms step_avg:570.46ms
|
| 604 |
+
step:37696/57344 val_loss:6.077408 train_time:21501649ms step_avg:570.40ms
|
| 605 |
+
step:37760/57344 val_loss:6.082530 train_time:21535827ms step_avg:570.33ms
|
| 606 |
+
step:37824/57344 val_loss:6.092300 train_time:21570177ms step_avg:570.28ms
|
| 607 |
+
step:37888/57344 val_loss:6.086246 train_time:21604371ms step_avg:570.22ms
|
| 608 |
+
step:37952/57344 val_loss:6.090149 train_time:21638493ms step_avg:570.15ms
|
| 609 |
+
step:38016/57344 val_loss:6.094055 train_time:21672651ms step_avg:570.09ms
|
| 610 |
+
step:38080/57344 val_loss:6.081831 train_time:21706702ms step_avg:570.03ms
|
| 611 |
+
step:38144/57344 val_loss:6.084065 train_time:21741042ms step_avg:569.97ms
|
| 612 |
+
step:38208/57344 val_loss:6.071197 train_time:21774996ms step_avg:569.91ms
|
| 613 |
+
step:38272/57344 val_loss:6.063191 train_time:21809555ms step_avg:569.86ms
|
| 614 |
+
step:38336/57344 val_loss:6.052119 train_time:21843598ms step_avg:569.79ms
|
| 615 |
+
step:38400/57344 val_loss:6.033501 train_time:21877620ms step_avg:569.73ms
|
| 616 |
+
step:38464/57344 val_loss:6.012586 train_time:21911681ms step_avg:569.67ms
|
| 617 |
+
step:38528/57344 val_loss:6.000410 train_time:21945841ms step_avg:569.61ms
|
| 618 |
+
step:38592/57344 val_loss:5.979206 train_time:21979915ms step_avg:569.55ms
|
| 619 |
+
step:38656/57344 val_loss:5.959765 train_time:22014034ms step_avg:569.49ms
|
| 620 |
+
step:38720/57344 val_loss:5.957704 train_time:22048298ms step_avg:569.43ms
|
| 621 |
+
step:38784/57344 val_loss:5.924534 train_time:22082281ms step_avg:569.37ms
|
| 622 |
+
step:38848/57344 val_loss:5.911640 train_time:22155241ms step_avg:570.31ms
|
| 623 |
+
step:38912/57344 val_loss:5.893886 train_time:22189187ms step_avg:570.24ms
|
| 624 |
+
step:38976/57344 val_loss:5.880382 train_time:22223275ms step_avg:570.18ms
|
| 625 |
+
step:39040/57344 val_loss:5.867537 train_time:22334939ms step_avg:572.10ms
|
| 626 |
+
step:39104/57344 val_loss:5.857060 train_time:22369096ms step_avg:572.04ms
|
| 627 |
+
step:39168/57344 val_loss:5.843616 train_time:22403256ms step_avg:571.98ms
|
| 628 |
+
step:39232/57344 val_loss:5.834862 train_time:22437509ms step_avg:571.92ms
|
| 629 |
+
step:39296/57344 val_loss:5.820549 train_time:22471590ms step_avg:571.85ms
|
| 630 |
+
step:39360/57344 val_loss:5.809020 train_time:22505436ms step_avg:571.78ms
|
| 631 |
+
step:39424/57344 val_loss:5.801020 train_time:22539737ms step_avg:571.73ms
|
| 632 |
+
step:39488/57344 val_loss:5.795458 train_time:22576002ms step_avg:571.72ms
|
| 633 |
+
step:39552/57344 val_loss:5.780212 train_time:22610594ms step_avg:571.67ms
|
| 634 |
+
step:39616/57344 val_loss:5.776663 train_time:22644944ms step_avg:571.61ms
|
| 635 |
+
step:39680/57344 val_loss:5.763973 train_time:22679028ms step_avg:571.55ms
|
| 636 |
+
step:39744/57344 val_loss:5.769980 train_time:22720949ms step_avg:571.68ms
|
| 637 |
+
step:39808/57344 val_loss:5.750341 train_time:22822029ms step_avg:573.30ms
|
| 638 |
+
step:39872/57344 val_loss:5.738113 train_time:22856612ms step_avg:573.25ms
|
| 639 |
+
step:39936/57344 val_loss:5.732807 train_time:22890831ms step_avg:573.19ms
|
| 640 |
+
step:40000/57344 val_loss:5.725449 train_time:22926057ms step_avg:573.15ms
|
| 641 |
+
step:40064/57344 val_loss:5.717214 train_time:22960136ms step_avg:573.09ms
|
| 642 |
+
step:40128/57344 val_loss:5.710665 train_time:22994398ms step_avg:573.03ms
|
| 643 |
+
step:40192/57344 val_loss:5.701880 train_time:23028521ms step_avg:572.96ms
|
| 644 |
+
step:40256/57344 val_loss:5.703946 train_time:23072631ms step_avg:573.15ms
|
| 645 |
+
step:40320/57344 val_loss:5.691270 train_time:23113549ms step_avg:573.25ms
|
| 646 |
+
step:40384/57344 val_loss:5.681849 train_time:23215672ms step_avg:574.87ms
|
| 647 |
+
step:40448/57344 val_loss:5.675029 train_time:23249992ms step_avg:574.81ms
|
| 648 |
+
step:40512/57344 val_loss:5.666840 train_time:23284243ms step_avg:574.75ms
|
| 649 |
+
step:40576/57344 val_loss:5.659797 train_time:23318538ms step_avg:574.69ms
|
| 650 |
+
step:40640/57344 val_loss:5.650706 train_time:23352688ms step_avg:574.62ms
|
| 651 |
+
step:40704/57344 val_loss:5.643932 train_time:23402365ms step_avg:574.94ms
|
| 652 |
+
step:40768/57344 val_loss:5.638920 train_time:23436351ms step_avg:574.87ms
|
| 653 |
+
step:40832/57344 val_loss:5.637269 train_time:23470417ms step_avg:574.80ms
|
| 654 |
+
step:40896/57344 val_loss:5.642417 train_time:23504619ms step_avg:574.74ms
|
| 655 |
+
step:40960/57344 val_loss:5.645013 train_time:23538855ms step_avg:574.68ms
|
| 656 |
+
step:41024/57344 val_loss:5.651797 train_time:23572951ms step_avg:574.61ms
|
| 657 |
+
step:41088/57344 val_loss:5.661096 train_time:23607124ms step_avg:574.55ms
|
| 658 |
+
step:41152/57344 val_loss:5.672447 train_time:23641352ms step_avg:574.49ms
|
| 659 |
+
step:41216/57344 val_loss:5.681271 train_time:23675456ms step_avg:574.42ms
|
| 660 |
+
step:41280/57344 val_loss:5.690168 train_time:23709425ms step_avg:574.36ms
|
| 661 |
+
step:41344/57344 val_loss:5.714119 train_time:23743967ms step_avg:574.30ms
|
| 662 |
+
step:41408/57344 val_loss:5.713656 train_time:23778128ms step_avg:574.24ms
|
| 663 |
+
step:41472/57344 val_loss:5.725800 train_time:23812238ms step_avg:574.18ms
|
| 664 |
+
step:41536/57344 val_loss:5.742362 train_time:23846757ms step_avg:574.12ms
|
| 665 |
+
step:41600/57344 val_loss:5.748781 train_time:23880749ms step_avg:574.06ms
|
| 666 |
+
step:41664/57344 val_loss:5.762106 train_time:23915949ms step_avg:574.02ms
|
| 667 |
+
step:41728/57344 val_loss:5.774612 train_time:23950493ms step_avg:573.97ms
|
| 668 |
+
step:41792/57344 val_loss:5.786279 train_time:23984608ms step_avg:573.90ms
|
| 669 |
+
step:41856/57344 val_loss:5.804955 train_time:24018674ms step_avg:573.84ms
|
| 670 |
+
step:41920/57344 val_loss:5.815269 train_time:24116686ms step_avg:575.30ms
|
| 671 |
+
step:41984/57344 val_loss:5.823739 train_time:24150664ms step_avg:575.23ms
|
| 672 |
+
step:42048/57344 val_loss:5.834544 train_time:24184724ms step_avg:575.17ms
|
| 673 |
+
step:42112/57344 val_loss:5.846921 train_time:24218896ms step_avg:575.11ms
|
| 674 |
+
step:42176/57344 val_loss:5.855831 train_time:24253156ms step_avg:575.05ms
|
| 675 |
+
step:42240/57344 val_loss:5.874364 train_time:24288127ms step_avg:575.00ms
|
| 676 |
+
step:42304/57344 val_loss:5.877427 train_time:24322683ms step_avg:574.95ms
|
| 677 |
+
step:42368/57344 val_loss:5.891029 train_time:24357337ms step_avg:574.90ms
|
| 678 |
+
step:42432/57344 val_loss:5.894765 train_time:24391947ms step_avg:574.85ms
|
| 679 |
+
step:42496/57344 val_loss:5.906126 train_time:24426454ms step_avg:574.79ms
|
| 680 |
+
step:42560/57344 val_loss:5.916362 train_time:24461050ms step_avg:574.74ms
|
| 681 |
+
step:42624/57344 val_loss:5.923081 train_time:24495730ms step_avg:574.69ms
|
| 682 |
+
step:42688/57344 val_loss:5.931384 train_time:24530905ms step_avg:574.66ms
|
| 683 |
+
step:42752/57344 val_loss:5.939623 train_time:24569989ms step_avg:574.71ms
|
| 684 |
+
step:42816/57344 val_loss:5.941106 train_time:24604687ms step_avg:574.66ms
|
| 685 |
+
step:42880/57344 val_loss:5.949475 train_time:24640040ms step_avg:574.63ms
|
| 686 |
+
step:42944/57344 val_loss:5.944251 train_time:24743273ms step_avg:576.18ms
|
| 687 |
+
step:43008/57344 val_loss:5.937825 train_time:24777407ms step_avg:576.11ms
|
| 688 |
+
step:43072/57344 val_loss:5.929796 train_time:24812179ms step_avg:576.06ms
|
| 689 |
+
step:43136/57344 val_loss:5.913666 train_time:24847159ms step_avg:576.02ms
|
| 690 |
+
step:43200/57344 val_loss:5.891812 train_time:24882667ms step_avg:575.99ms
|
| 691 |
+
step:43264/57344 val_loss:5.870100 train_time:24917501ms step_avg:575.94ms
|
| 692 |
+
step:43328/57344 val_loss:5.847303 train_time:24952127ms step_avg:575.89ms
|
| 693 |
+
step:43392/57344 val_loss:5.814780 train_time:24989419ms step_avg:575.90ms
|
| 694 |
+
step:43456/57344 val_loss:5.802860 train_time:25056664ms step_avg:576.60ms
|
| 695 |
+
step:43520/57344 val_loss:5.776017 train_time:25106688ms step_avg:576.90ms
|
| 696 |
+
step:43584/57344 val_loss:5.755119 train_time:25141362ms step_avg:576.85ms
|
| 697 |
+
step:43648/57344 val_loss:5.734976 train_time:25176277ms step_avg:576.80ms
|
| 698 |
+
step:43712/57344 val_loss:5.717041 train_time:25211027ms step_avg:576.75ms
|
| 699 |
+
step:43776/57344 val_loss:5.703759 train_time:25245766ms step_avg:576.70ms
|
| 700 |
+
step:43840/57344 val_loss:5.692029 train_time:25280388ms step_avg:576.65ms
|
| 701 |
+
step:43904/57344 val_loss:5.675054 train_time:25314825ms step_avg:576.59ms
|
| 702 |
+
step:43968/57344 val_loss:5.667020 train_time:25355986ms step_avg:576.69ms
|
| 703 |
+
step:44032/57344 val_loss:5.655145 train_time:25396136ms step_avg:576.77ms
|
| 704 |
+
step:44096/57344 val_loss:5.643243 train_time:25430145ms step_avg:576.70ms
|
| 705 |
+
step:44160/57344 val_loss:5.637422 train_time:25515891ms step_avg:577.81ms
|
| 706 |
+
step:44224/57344 val_loss:5.627028 train_time:25551292ms step_avg:577.77ms
|
| 707 |
+
step:44288/57344 val_loss:5.620749 train_time:25700288ms step_avg:580.30ms
|
| 708 |
+
step:44352/57344 val_loss:5.608880 train_time:25734978ms step_avg:580.24ms
|
| 709 |
+
step:44416/57344 val_loss:5.600425 train_time:25769584ms step_avg:580.19ms
|
| 710 |
+
step:44480/57344 val_loss:5.594759 train_time:25804303ms step_avg:580.13ms
|
| 711 |
+
step:44544/57344 val_loss:5.592071 train_time:25838983ms step_avg:580.08ms
|
| 712 |
+
step:44608/57344 val_loss:5.579262 train_time:25874062ms step_avg:580.03ms
|
| 713 |
+
step:44672/57344 val_loss:5.572731 train_time:25908690ms step_avg:579.98ms
|
| 714 |
+
step:44736/57344 val_loss:5.566231 train_time:25943413ms step_avg:579.92ms
|
| 715 |
+
step:44800/57344 val_loss:5.560724 train_time:25978106ms step_avg:579.87ms
|
| 716 |
+
step:44864/57344 val_loss:5.553838 train_time:26013184ms step_avg:579.82ms
|
| 717 |
+
step:44928/57344 val_loss:5.549256 train_time:26047608ms step_avg:579.76ms
|
| 718 |
+
step:44992/57344 val_loss:5.542297 train_time:26082183ms step_avg:579.71ms
|
| 719 |
+
step:45056/57344 val_loss:5.544479 train_time:26128800ms step_avg:579.92ms
|
| 720 |
+
step:45120/57344 val_loss:5.551186 train_time:26163320ms step_avg:579.86ms
|
| 721 |
+
step:45184/57344 val_loss:5.559153 train_time:26197826ms step_avg:579.80ms
|
| 722 |
+
step:45248/57344 val_loss:5.567746 train_time:26232623ms step_avg:579.75ms
|
| 723 |
+
step:45312/57344 val_loss:5.576434 train_time:26267181ms step_avg:579.70ms
|
| 724 |
+
step:45376/57344 val_loss:5.587078 train_time:26302064ms step_avg:579.65ms
|
| 725 |
+
step:45440/57344 val_loss:5.598009 train_time:26337200ms step_avg:579.60ms
|
| 726 |
+
step:45504/57344 val_loss:5.610972 train_time:26372048ms step_avg:579.55ms
|
| 727 |
+
step:45568/57344 val_loss:5.621460 train_time:26406987ms step_avg:579.51ms
|
| 728 |
+
step:45632/57344 val_loss:5.638070 train_time:26446640ms step_avg:579.56ms
|
| 729 |
+
step:45696/57344 val_loss:5.647486 train_time:26481199ms step_avg:579.51ms
|
| 730 |
+
step:45760/57344 val_loss:5.659206 train_time:26516841ms step_avg:579.48ms
|
| 731 |
+
step:45824/57344 val_loss:5.673312 train_time:26551656ms step_avg:579.43ms
|
| 732 |
+
step:45888/57344 val_loss:5.688259 train_time:26586403ms step_avg:579.38ms
|
| 733 |
+
step:45952/57344 val_loss:5.700180 train_time:26621257ms step_avg:579.33ms
|
| 734 |
+
step:46016/57344 val_loss:5.713002 train_time:26656239ms step_avg:579.28ms
|
| 735 |
+
step:46080/57344 val_loss:5.725313 train_time:26690904ms step_avg:579.23ms
|
| 736 |
+
step:46144/57344 val_loss:5.738195 train_time:26725908ms step_avg:579.18ms
|
| 737 |
+
step:46208/57344 val_loss:5.756293 train_time:26760879ms step_avg:579.14ms
|
| 738 |
+
step:46272/57344 val_loss:5.767856 train_time:26795415ms step_avg:579.08ms
|
| 739 |
+
step:46336/57344 val_loss:5.775228 train_time:26829942ms step_avg:579.03ms
|
| 740 |
+
step:46400/57344 val_loss:5.789692 train_time:26864486ms step_avg:578.98ms
|
| 741 |
+
step:46464/57344 val_loss:5.799087 train_time:26899528ms step_avg:578.93ms
|
| 742 |
+
step:46528/57344 val_loss:5.813019 train_time:26934711ms step_avg:578.89ms
|
| 743 |
+
step:46592/57344 val_loss:5.820201 train_time:26969200ms step_avg:578.84ms
|
| 744 |
+
step:46656/57344 val_loss:5.835791 train_time:27036107ms step_avg:579.48ms
|
| 745 |
+
step:46720/57344 val_loss:5.844876 train_time:27086393ms step_avg:579.76ms
|
| 746 |
+
step:46784/57344 val_loss:5.853851 train_time:27120656ms step_avg:579.70ms
|
| 747 |
+
step:46848/57344 val_loss:5.871704 train_time:27157591ms step_avg:579.70ms
|
| 748 |
+
step:46912/57344 val_loss:5.877258 train_time:27192560ms step_avg:579.65ms
|
| 749 |
+
step:46976/57344 val_loss:5.897797 train_time:27228642ms step_avg:579.63ms
|
| 750 |
+
step:47040/57344 val_loss:5.894917 train_time:27263643ms step_avg:579.58ms
|
| 751 |
+
step:47104/57344 val_loss:5.899468 train_time:27299037ms step_avg:579.55ms
|
| 752 |
+
step:47168/57344 val_loss:5.901907 train_time:27334201ms step_avg:579.51ms
|
| 753 |
+
step:47232/57344 val_loss:5.902164 train_time:27369375ms step_avg:579.47ms
|
| 754 |
+
step:47296/57344 val_loss:5.892847 train_time:27404301ms step_avg:579.42ms
|
| 755 |
+
step:47360/57344 val_loss:5.879344 train_time:27461853ms step_avg:579.85ms
|
| 756 |
+
step:47424/57344 val_loss:5.857492 train_time:27630393ms step_avg:582.62ms
|
| 757 |
+
step:47488/57344 val_loss:5.831481 train_time:27665088ms step_avg:582.57ms
|
| 758 |
+
step:47552/57344 val_loss:5.802512 train_time:27740002ms step_avg:583.36ms
|
| 759 |
+
step:47616/57344 val_loss:5.777002 train_time:27774848ms step_avg:583.31ms
|
| 760 |
+
step:47680/57344 val_loss:5.752609 train_time:27810257ms step_avg:583.27ms
|
| 761 |
+
step:47744/57344 val_loss:5.728514 train_time:27845662ms step_avg:583.23ms
|
| 762 |
+
step:47808/57344 val_loss:5.709937 train_time:27880867ms step_avg:583.18ms
|
| 763 |
+
step:47872/57344 val_loss:5.692632 train_time:27916102ms step_avg:583.14ms
|
| 764 |
+
step:47936/57344 val_loss:5.681762 train_time:27951777ms step_avg:583.11ms
|
| 765 |
+
step:48000/57344 val_loss:5.659550 train_time:27986794ms step_avg:583.06ms
|
| 766 |
+
step:48064/57344 val_loss:5.645223 train_time:28050344ms step_avg:583.60ms
|
| 767 |
+
step:48128/57344 val_loss:5.632010 train_time:28187394ms step_avg:585.68ms
|
| 768 |
+
step:48192/57344 val_loss:5.621907 train_time:28257516ms step_avg:586.35ms
|
| 769 |
+
step:48256/57344 val_loss:5.611989 train_time:28321303ms step_avg:586.90ms
|
| 770 |
+
step:48320/57344 val_loss:5.599409 train_time:28394587ms step_avg:587.64ms
|
| 771 |
+
step:48384/57344 val_loss:5.596268 train_time:28429876ms step_avg:587.59ms
|
| 772 |
+
step:48448/57344 val_loss:5.582804 train_time:28465757ms step_avg:587.55ms
|
| 773 |
+
step:48512/57344 val_loss:5.570768 train_time:28500849ms step_avg:587.50ms
|
| 774 |
+
step:48576/57344 val_loss:5.563162 train_time:28546891ms step_avg:587.67ms
|
| 775 |
+
step:48640/57344 val_loss:5.555359 train_time:28581636ms step_avg:587.62ms
|
| 776 |
+
step:48704/57344 val_loss:5.550089 train_time:28617105ms step_avg:587.57ms
|
| 777 |
+
step:48768/57344 val_loss:5.544346 train_time:28652230ms step_avg:587.52ms
|
| 778 |
+
step:48832/57344 val_loss:5.536995 train_time:28687497ms step_avg:587.47ms
|
| 779 |
+
step:48896/57344 val_loss:5.531327 train_time:28722824ms step_avg:587.43ms
|
| 780 |
+
step:48960/57344 val_loss:5.526346 train_time:28757926ms step_avg:587.38ms
|
| 781 |
+
step:49024/57344 val_loss:5.524518 train_time:28793260ms step_avg:587.33ms
|
| 782 |
+
step:49088/57344 val_loss:5.516452 train_time:28830618ms step_avg:587.33ms
|
| 783 |
+
step:49152/57344 val_loss:5.509875 train_time:28872350ms step_avg:587.41ms
|
| 784 |
+
step:49216/57344 val_loss:5.505832 train_time:28907428ms step_avg:587.36ms
|
| 785 |
+
step:49280/57344 val_loss:5.502330 train_time:28942453ms step_avg:587.31ms
|
| 786 |
+
step:49344/57344 val_loss:5.494663 train_time:28977407ms step_avg:587.25ms
|
| 787 |
+
step:49408/57344 val_loss:5.492581 train_time:29012687ms step_avg:587.21ms
|
| 788 |
+
step:49472/57344 val_loss:5.487586 train_time:29047871ms step_avg:587.16ms
|
| 789 |
+
step:49536/57344 val_loss:5.484352 train_time:29082944ms step_avg:587.11ms
|
| 790 |
+
step:49600/57344 val_loss:5.480047 train_time:29184381ms step_avg:588.39ms
|
| 791 |
+
step:49664/57344 val_loss:5.477690 train_time:29226907ms step_avg:588.49ms
|
| 792 |
+
step:49728/57344 val_loss:5.474648 train_time:29261890ms step_avg:588.44ms
|
| 793 |
+
step:49792/57344 val_loss:5.469898 train_time:29297009ms step_avg:588.39ms
|
| 794 |
+
step:49856/57344 val_loss:5.466804 train_time:29332427ms step_avg:588.34ms
|
| 795 |
+
step:49920/57344 val_loss:5.462715 train_time:29367801ms step_avg:588.30ms
|
| 796 |
+
step:49984/57344 val_loss:5.460168 train_time:29402956ms step_avg:588.25ms
|
| 797 |
+
step:50048/57344 val_loss:5.456926 train_time:29438270ms step_avg:588.20ms
|
| 798 |
+
step:50112/57344 val_loss:5.455181 train_time:29473902ms step_avg:588.16ms
|
| 799 |
+
step:50176/57344 val_loss:5.449932 train_time:29509305ms step_avg:588.12ms
|
| 800 |
+
step:50240/57344 val_loss:5.446966 train_time:29544709ms step_avg:588.07ms
|
| 801 |
+
step:50304/57344 val_loss:5.445749 train_time:29580105ms step_avg:588.03ms
|
| 802 |
+
step:50368/57344 val_loss:5.442234 train_time:29615652ms step_avg:587.99ms
|
| 803 |
+
step:50432/57344 val_loss:5.437803 train_time:29652729ms step_avg:587.97ms
|
| 804 |
+
step:50496/57344 val_loss:5.436185 train_time:29687953ms step_avg:587.93ms
|
| 805 |
+
step:50560/57344 val_loss:5.431937 train_time:29722909ms step_avg:587.87ms
|
| 806 |
+
step:50624/57344 val_loss:5.430612 train_time:29758591ms step_avg:587.84ms
|
| 807 |
+
step:50688/57344 val_loss:5.428927 train_time:29797152ms step_avg:587.85ms
|
| 808 |
+
step:50752/57344 val_loss:5.425698 train_time:29832461ms step_avg:587.81ms
|
| 809 |
+
step:50816/57344 val_loss:5.422413 train_time:29868017ms step_avg:587.77ms
|
| 810 |
+
step:50880/57344 val_loss:5.421695 train_time:29904066ms step_avg:587.74ms
|
| 811 |
+
step:50944/57344 val_loss:5.418712 train_time:29940051ms step_avg:587.71ms
|
| 812 |
+
step:51008/57344 val_loss:5.415042 train_time:29975185ms step_avg:587.66ms
|
| 813 |
+
step:51072/57344 val_loss:5.411607 train_time:30016337ms step_avg:587.73ms
|
| 814 |
+
step:51136/57344 val_loss:5.409361 train_time:30094028ms step_avg:588.51ms
|
| 815 |
+
step:51200/57344 val_loss:5.407613 train_time:30198342ms step_avg:589.81ms
|
| 816 |
+
step:51264/57344 val_loss:5.406591 train_time:30233834ms step_avg:589.77ms
|
| 817 |
+
step:51328/57344 val_loss:5.404155 train_time:30269107ms step_avg:589.72ms
|
| 818 |
+
step:51392/57344 val_loss:5.401775 train_time:30304605ms step_avg:589.68ms
|
| 819 |
+
step:51456/57344 val_loss:5.404428 train_time:30340036ms step_avg:589.63ms
|
| 820 |
+
step:51520/57344 val_loss:5.397223 train_time:30375043ms step_avg:589.58ms
|
| 821 |
+
step:51584/57344 val_loss:5.395511 train_time:30410425ms step_avg:589.53ms
|
| 822 |
+
step:51648/57344 val_loss:5.393268 train_time:30445528ms step_avg:589.48ms
|
| 823 |
+
step:51712/57344 val_loss:5.390558 train_time:30480976ms step_avg:589.44ms
|
| 824 |
+
step:51776/57344 val_loss:5.389056 train_time:30516242ms step_avg:589.39ms
|
| 825 |
+
step:51840/57344 val_loss:5.388100 train_time:30551838ms step_avg:589.35ms
|
| 826 |
+
step:51904/57344 val_loss:5.383886 train_time:30587621ms step_avg:589.31ms
|
| 827 |
+
step:51968/57344 val_loss:5.381837 train_time:30623334ms step_avg:589.27ms
|
| 828 |
+
step:52032/57344 val_loss:5.380775 train_time:30659141ms step_avg:589.24ms
|
| 829 |
+
step:52096/57344 val_loss:5.378386 train_time:30694368ms step_avg:589.19ms
|
| 830 |
+
step:52160/57344 val_loss:5.376794 train_time:30729668ms step_avg:589.14ms
|
| 831 |
+
step:52224/57344 val_loss:5.375344 train_time:30765369ms step_avg:589.10ms
|
| 832 |
+
step:52288/57344 val_loss:5.375767 train_time:30801165ms step_avg:589.07ms
|
| 833 |
+
step:52352/57344 val_loss:5.371130 train_time:30848043ms step_avg:589.24ms
|
| 834 |
+
step:52416/57344 val_loss:5.369224 train_time:30901541ms step_avg:589.54ms
|
| 835 |
+
step:52480/57344 val_loss:5.370637 train_time:31037158ms step_avg:591.41ms
|
| 836 |
+
step:52544/57344 val_loss:5.366584 train_time:31090092ms step_avg:591.70ms
|
| 837 |
+
step:52608/57344 val_loss:5.364900 train_time:31149748ms step_avg:592.11ms
|
| 838 |
+
step:52672/57344 val_loss:5.362838 train_time:31185040ms step_avg:592.06ms
|
| 839 |
+
step:52736/57344 val_loss:5.362185 train_time:31221324ms step_avg:592.03ms
|
| 840 |
+
step:52800/57344 val_loss:5.360997 train_time:31257516ms step_avg:592.00ms
|
| 841 |
+
step:52864/57344 val_loss:5.359124 train_time:31293190ms step_avg:591.96ms
|
| 842 |
+
step:52928/57344 val_loss:5.358187 train_time:31329372ms step_avg:591.92ms
|
| 843 |
+
step:52992/57344 val_loss:5.356282 train_time:31364959ms step_avg:591.88ms
|
| 844 |
+
step:53056/57344 val_loss:5.355115 train_time:31400641ms step_avg:591.84ms
|
| 845 |
+
step:53120/57344 val_loss:5.352453 train_time:31436443ms step_avg:591.80ms
|
| 846 |
+
step:53184/57344 val_loss:5.351868 train_time:31471964ms step_avg:591.76ms
|
| 847 |
+
step:53248/57344 val_loss:5.350027 train_time:31507955ms step_avg:591.72ms
|
| 848 |
+
step:53312/57344 val_loss:5.349732 train_time:31544471ms step_avg:591.70ms
|
| 849 |
+
step:53376/57344 val_loss:5.346778 train_time:31579970ms step_avg:591.65ms
|
| 850 |
+
step:53440/57344 val_loss:5.346203 train_time:31615830ms step_avg:591.61ms
|
| 851 |
+
step:53504/57344 val_loss:5.344517 train_time:31651919ms step_avg:591.58ms
|
| 852 |
+
step:53568/57344 val_loss:5.345055 train_time:31688739ms step_avg:591.56ms
|
| 853 |
+
step:53632/57344 val_loss:5.341630 train_time:31724651ms step_avg:591.52ms
|
| 854 |
+
step:53696/57344 val_loss:5.341227 train_time:31766526ms step_avg:591.60ms
|
| 855 |
+
step:53760/57344 val_loss:5.339957 train_time:31973948ms step_avg:594.75ms
|
| 856 |
+
step:53824/57344 val_loss:5.338264 train_time:32067153ms step_avg:595.78ms
|
| 857 |
+
step:53888/57344 val_loss:5.337718 train_time:32102673ms step_avg:595.73ms
|
| 858 |
+
step:53952/57344 val_loss:5.336123 train_time:32138028ms step_avg:595.68ms
|
| 859 |
+
step:54016/57344 val_loss:5.334979 train_time:32174172ms step_avg:595.64ms
|
| 860 |
+
step:54080/57344 val_loss:5.334038 train_time:32209815ms step_avg:595.60ms
|
| 861 |
+
step:54144/57344 val_loss:5.332578 train_time:32245658ms step_avg:595.55ms
|
| 862 |
+
step:54208/57344 val_loss:5.331984 train_time:32281839ms step_avg:595.52ms
|
| 863 |
+
step:54272/57344 val_loss:5.330531 train_time:32317859ms step_avg:595.48ms
|
| 864 |
+
step:54336/57344 val_loss:5.331734 train_time:32354697ms step_avg:595.46ms
|
| 865 |
+
step:54400/57344 val_loss:5.329116 train_time:32390675ms step_avg:595.42ms
|
| 866 |
+
step:54464/57344 val_loss:5.327961 train_time:32426781ms step_avg:595.38ms
|
| 867 |
+
step:54528/57344 val_loss:5.327446 train_time:32463097ms step_avg:595.35ms
|
| 868 |
+
step:54592/57344 val_loss:5.326375 train_time:32499562ms step_avg:595.32ms
|
| 869 |
+
step:54656/57344 val_loss:5.324928 train_time:32535581ms step_avg:595.28ms
|
| 870 |
+
step:54720/57344 val_loss:5.323860 train_time:32571755ms step_avg:595.24ms
|
| 871 |
+
step:54784/57344 val_loss:5.322510 train_time:32697841ms step_avg:596.85ms
|
| 872 |
+
step:54848/57344 val_loss:5.322264 train_time:32786644ms step_avg:597.77ms
|
| 873 |
+
step:54912/57344 val_loss:5.321797 train_time:32823066ms step_avg:597.74ms
|
| 874 |
+
step:54976/57344 val_loss:5.319905 train_time:32858918ms step_avg:597.70ms
|
| 875 |
+
step:55040/57344 val_loss:5.319589 train_time:32895098ms step_avg:597.66ms
|
| 876 |
+
step:55104/57344 val_loss:5.318570 train_time:32931575ms step_avg:597.63ms
|
| 877 |
+
step:55168/57344 val_loss:5.317809 train_time:32967580ms step_avg:597.59ms
|
| 878 |
+
step:55232/57344 val_loss:5.317148 train_time:33003329ms step_avg:597.54ms
|
| 879 |
+
step:55296/57344 val_loss:5.316221 train_time:33039314ms step_avg:597.50ms
|
| 880 |
+
step:55360/57344 val_loss:5.315194 train_time:33075408ms step_avg:597.46ms
|
| 881 |
+
step:55424/57344 val_loss:5.314674 train_time:33111367ms step_avg:597.42ms
|
| 882 |
+
step:55488/57344 val_loss:5.314028 train_time:33147445ms step_avg:597.38ms
|
| 883 |
+
step:55552/57344 val_loss:5.313580 train_time:33183793ms step_avg:597.35ms
|
| 884 |
+
step:55616/57344 val_loss:5.312858 train_time:33219949ms step_avg:597.31ms
|
| 885 |
+
step:55680/57344 val_loss:5.311756 train_time:33256107ms step_avg:597.27ms
|
| 886 |
+
step:55744/57344 val_loss:5.311058 train_time:33293112ms step_avg:597.25ms
|
| 887 |
+
step:55808/57344 val_loss:5.311450 train_time:33330097ms step_avg:597.23ms
|
| 888 |
+
step:55872/57344 val_loss:5.310041 train_time:33367043ms step_avg:597.21ms
|
| 889 |
+
step:55936/57344 val_loss:5.309947 train_time:33403635ms step_avg:597.18ms
|
| 890 |
+
step:56000/57344 val_loss:5.308713 train_time:33439963ms step_avg:597.14ms
|
| 891 |
+
step:56064/57344 val_loss:5.308554 train_time:33476175ms step_avg:597.11ms
|
| 892 |
+
step:56128/57344 val_loss:5.307552 train_time:33512326ms step_avg:597.07ms
|
| 893 |
+
step:56192/57344 val_loss:5.307443 train_time:33548760ms step_avg:597.04ms
|
| 894 |
+
step:56256/57344 val_loss:5.306889 train_time:33585893ms step_avg:597.02ms
|
| 895 |
+
step:56320/57344 val_loss:5.306214 train_time:33622613ms step_avg:596.99ms
|
| 896 |
+
step:56384/57344 val_loss:5.305820 train_time:33658770ms step_avg:596.96ms
|
| 897 |
+
step:56448/57344 val_loss:5.305137 train_time:33695087ms step_avg:596.92ms
|
| 898 |
+
step:56512/57344 val_loss:5.304876 train_time:33731160ms step_avg:596.88ms
|
| 899 |
+
step:56576/57344 val_loss:5.304440 train_time:33767486ms step_avg:596.85ms
|
| 900 |
+
step:56640/57344 val_loss:5.304251 train_time:33803165ms step_avg:596.81ms
|
| 901 |
+
step:56704/57344 val_loss:5.303982 train_time:33839509ms step_avg:596.77ms
|
| 902 |
+
step:56768/57344 val_loss:5.303730 train_time:33877159ms step_avg:596.77ms
|
| 903 |
+
step:56832/57344 val_loss:5.303309 train_time:33913515ms step_avg:596.73ms
|
| 904 |
+
step:56896/57344 val_loss:5.302948 train_time:33950699ms step_avg:596.72ms
|
| 905 |
+
step:56960/57344 val_loss:5.302761 train_time:33987944ms step_avg:596.70ms
|
| 906 |
+
step:57024/57344 val_loss:5.302407 train_time:34024070ms step_avg:596.66ms
|
| 907 |
+
step:57088/57344 val_loss:5.302102 train_time:34060595ms step_avg:596.63ms
|
| 908 |
+
step:57152/57344 val_loss:5.301837 train_time:34097318ms step_avg:596.61ms
|
| 909 |
+
step:57216/57344 val_loss:5.301659 train_time:34133866ms step_avg:596.58ms
|
| 910 |
+
step:57280/57344 val_loss:5.301528 train_time:34170859ms step_avg:596.56ms
|
| 911 |
+
step:57344/57344 val_loss:5.301472 train_time:34207380ms step_avg:596.53ms
|
modded-nanogpt-train.16700835.err
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
pyproject.toml
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[project]
|
| 2 |
+
name = "modded-nanogpt"
|
| 3 |
+
version = "0.1.0"
|
| 4 |
+
description = "Add your description here"
|
| 5 |
+
readme = "README.md"
|
| 6 |
+
requires-python = ">=3.12"
|
| 7 |
+
dependencies = [
|
| 8 |
+
"arguably>=1.3.0",
|
| 9 |
+
"datasets>=4.1.1",
|
| 10 |
+
"loguru>=0.7.3",
|
| 11 |
+
"nvitop>=1.5.3",
|
| 12 |
+
"tiktoken>=0.11.0",
|
| 13 |
+
"torch>=2.8.0",
|
| 14 |
+
"tqdm>=4.67.1",
|
| 15 |
+
]
|
| 16 |
+
|
| 17 |
+
[[tool.uv.index]]
|
| 18 |
+
url = "https://pypi.org/simple"
|
| 19 |
+
default = true
|
records/010425_SoftCap/31d6c427-f1f7-4d8a-91be-a67b5dcd13fd.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/010425_SoftCap/README.md
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Softer softcap
|
| 2 |
+
|
| 3 |
+
This record, by Braden Koszarsky, increases the degree of logit softcapping, yielding a 7% speedup.
|
| 4 |
+
[reproducible log](31d6c427-f1f7-4d8a-91be-a67b5dcd13fd.txt)
|
| 5 |
+
|
| 6 |
+
Previously, logits were softcapped (via tanh) to be at most 30. The new record lowers that to 15,
|
| 7 |
+
which boosts performance such that the step count can be reduced from 1490 to 1390.
|
| 8 |
+
|
| 9 |
+
Lowering the tanh softcap can be understood as a form of extra structure which we are imposing on the network, which improves
|
| 10 |
+
performance in the small-scale regime.
|
| 11 |
+
|
| 12 |
+
Running this new record 80 times yielded the following series of val losses:
|
| 13 |
+
```
|
| 14 |
+
accs = [3.2798, 3.2804, 3.2837, 3.2808, 3.2782, 3.2801, 3.283, 3.2825, 3.2777, 3.2769, 3.2834, 3.2832, 3.2753,
|
| 15 |
+
3.2809, 3.2778, 3.2801, 3.2799, 3.2804, 3.2765, 3.2792, 3.2786, 3.2792, 3.2801, 3.2762, 3.2803, 3.2784,
|
| 16 |
+
3.2792, 3.2791, 3.2769, 3.279, 3.2784, 3.2775, 3.283, 3.2785, 3.2753, 3.2805, 3.2766, 3.2766, 3.2781,
|
| 17 |
+
3.2819, 3.2754, 3.2827, 3.2803, 3.2784, 3.2802, 3.2794, 3.2765, 3.278, 3.2782, 3.278, 3.2816, 3.279,
|
| 18 |
+
3.2771, 3.2791, 3.2768, 3.2781, 3.2794, 3.2798, 3.2785, 3.2804, 3.2777, 3.2765, 3.2796, 3.278, 3.2803,
|
| 19 |
+
3.2793, 3.2793, 3.2788, 3.2797, 3.278, 3.2799, 3.2813, 3.2803, 3.2768, 3.2803, 3.2796, 3.28, 3.2796,
|
| 20 |
+
3.2783, 3.278]
|
| 21 |
+
|
| 22 |
+
import scipy.stats
|
| 23 |
+
print('p=%.4f' % scipy.stats.ttest_1samp(accs, 3.28, alternative='less').pvalue)
|
| 24 |
+
# p=0.0001
|
| 25 |
+
|
| 26 |
+
import torch
|
| 27 |
+
print(torch.std_mean(torch.tensor(accs)))
|
| 28 |
+
# (tensor(0.0019), tensor(3.2791))
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+

|
| 32 |
+
|
records/010425_SoftCap/curves_010425.png
ADDED

|
Git LFS Details
|
records/011325_Fp8LmHead/README.md
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Note: statistical significance was obtained by @YouJiacheng [here](https://x.com/YouJiacheng/status/1878827972519772241).
|
records/011325_Fp8LmHead/c51969c2-d04c-40a7-bcea-c092c3c2d11a.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/011625_Sub3Min/1d3bd93b-a69e-4118-aeb8-8184239d7566.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/011625_Sub3Min/README.md
ADDED
|
@@ -0,0 +1,138 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Sub-3 minute record
|
| 2 |
+
|
| 3 |
+
## Evidence for <=3.28 mean loss
|
| 4 |
+
|
| 5 |
+
```bash
|
| 6 |
+
$ grep "1393/1393 val" * | python -c "import sys; ss = list(sys.stdin); accs = [float(s.split()[1].split(':')[1]) for s in ss]; print(accs); import scipy.stats; mvs = scipy.stats.bayes_mvs(accs); print(mvs[0]); print(mvs[2]); print(f'p={scipy.stats.ttest_1samp(accs, 3.28, alternative='less').pvalue:.4f}')"
|
| 7 |
+
[3.276, 3.2785, 3.2796, 3.2788, 3.2789, 3.2768, 3.2775, 3.2784, 3.2767, 3.2792, 3.2807, 3.2801, 3.2805, 3.2777, 3.2789, 3.2799, 3.2786, 3.2776, 3.2791, 3.2808, 3.2776, 3.2786, 3.2774, 3.2832, 3.277, 3.2789, 3.2784, 3.2766, 3.2755, 3.2784, 3.2798, 3.2825]
|
| 8 |
+
Mean(statistic=np.float64(3.27869375), minmax=(np.float64(3.2781784751445135), np.float64(3.2792090248554864)))
|
| 9 |
+
Std_dev(statistic=np.float64(0.0017621789337662857), minmax=(np.float64(0.0014271074116428265), np.float64(0.002179878373699496)))
|
| 10 |
+
p=0.0001
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
```
|
| 14 |
+
Mean runtime: 179.8 seconds
|
| 15 |
+
Stddev: 101ms
|
| 16 |
+
```
|
| 17 |
+
|
| 18 |
+
## Details on the changes made
|
| 19 |
+
|
| 20 |
+
### Long-Short Sliding Window Attention
|
| 21 |
+
|
| 22 |
+

|
| 23 |
+
|
| 24 |
+
This attention mechanism is inspired by the Local-Global Attention introduced by the [Gemma 2](https://arxiv.org/abs/2408.00118) paper (and more recent "hybrid" architectures). But there are two key differences:
|
| 25 |
+
|
| 26 |
+
1. We use [Sliding Window Attention](https://arxiv.org/abs/2004.05150) for both the "global attention" (i.e. "long SWA") and the "local attention" (i.e. "short SWA") parts. The difference between the two is that the "long SWA" has double the context length of the "short SWA".
|
| 27 |
+
2. We also **warmup the context length** of both the sliding window attention mechanisms, but **at different rates**. The "long SWA" context length is warmed up at a double the rate compared to the "short SWA".
|
| 28 |
+
|
| 29 |
+
We also made a speedrun-specific decision to only use "long SWA" in the first, fifth, and last layers. The first, because we do not want to compress information too early in the network. The last, because the model architecture we use for the speedrun follows a UNet-like structure, and we want the first and the last layers to be symmetric. And finally, the fifth layer, mainly because it is empirically the best choice for the speedrun.
|
| 30 |
+
|
| 31 |
+
This would have been very difficult to implement without PyTorch's [FlexAttention](https://pytorch.org/blog/flexattention/).
|
| 32 |
+
|
| 33 |
+
```diff
|
| 34 |
+
# In GPT.forward...
|
| 35 |
+
def dense_to_ordered(dense_mask: torch.Tensor):
|
| 36 |
+
num_blocks = dense_mask.sum(dim=-1, dtype=torch.int32)
|
| 37 |
+
- indices = dense_mask.argsort(dim=-1, descending=True, stable=True).to(torch.int32)
|
| 38 |
+
+ indices = dense_mask.argsort(dim=-1, descending=False, stable=True).flip(-1).to(torch.int32)
|
| 39 |
+
return num_blocks[None, None].contiguous(), indices[None, None].contiguous()
|
| 40 |
+
|
| 41 |
+
- def create_doc_swc_block_mask(sliding_window_num_blocks):
|
| 42 |
+
+ def create_doc_swc_block_masks(sliding_window_num_blocks: int):
|
| 43 |
+
kv_idx = block_idx = torch.arange(total_num_blocks, dtype=torch.int32, device='cuda')
|
| 44 |
+
q_idx = block_idx[:, None]
|
| 45 |
+
causal_bm = q_idx >= kv_idx
|
| 46 |
+
causal_full_bm = q_idx > kv_idx
|
| 47 |
+
- window_bm = q_idx - kv_idx < sliding_window_num_blocks
|
| 48 |
+
- window_full_bm = window_bm # block-wise sliding window by @YouJiacheng
|
| 49 |
+
document_bm = (docs_low[:, None] <= docs_high) & (docs_low <= docs_high[:, None])
|
| 50 |
+
document_full_bm = (docs_low[:, None] == docs_high) & (docs_low == docs_high[:, None])
|
| 51 |
+
- nonzero_bm = causal_bm & window_bm & document_bm
|
| 52 |
+
- full_bm = causal_full_bm & window_full_bm & document_full_bm
|
| 53 |
+
+ nonzero_bm = causal_bm & document_bm
|
| 54 |
+
+ full_bm = causal_full_bm & document_full_bm
|
| 55 |
+
kv_num_blocks, kv_indices = dense_to_ordered(nonzero_bm & ~full_bm)
|
| 56 |
+
full_kv_num_blocks, full_kv_indices = dense_to_ordered(full_bm)
|
| 57 |
+
- return BlockMask.from_kv_blocks(
|
| 58 |
+
- kv_num_blocks,
|
| 59 |
+
- kv_indices,
|
| 60 |
+
- full_kv_num_blocks,
|
| 61 |
+
- full_kv_indices,
|
| 62 |
+
- BLOCK_SIZE=BLOCK_SIZE,
|
| 63 |
+
- mask_mod=document_causal,
|
| 64 |
+
- )
|
| 65 |
+
+ def build_bm(sw_num_blocks: Tensor) -> BlockMask:
|
| 66 |
+
+ return BlockMask.from_kv_blocks(
|
| 67 |
+
+ torch.clamp_max(kv_num_blocks, torch.clamp_min(sw_num_blocks - full_kv_num_blocks, 1)),
|
| 68 |
+
+ kv_indices,
|
| 69 |
+
+ torch.clamp_max(full_kv_num_blocks, sw_num_blocks - 1),
|
| 70 |
+
+ full_kv_indices,
|
| 71 |
+
+ BLOCK_SIZE=BLOCK_SIZE,
|
| 72 |
+
+ mask_mod=document_causal,
|
| 73 |
+
+ )
|
| 74 |
+
+ return build_bm(sliding_window_num_blocks), build_bm(sliding_window_num_blocks // 2)
|
| 75 |
+
|
| 76 |
+
- block_mask = create_doc_swc_block_mask(sliding_window_num_blocks)
|
| 77 |
+
+ long_bm, short_bm = create_doc_swc_block_masks(sliding_window_num_blocks)
|
| 78 |
+
...
|
| 79 |
+
skip_connections = []
|
| 80 |
+
# Encoder pass - process only the first half of the blocks
|
| 81 |
+
+ block_masks = [long_bm, short_bm, short_bm, short_bm, long_bm, short_bm]
|
| 82 |
+
for i in range(self.num_encoder_layers):
|
| 83 |
+
- x = self.blocks[i](x, ve_enc[i], x0, block_mask)
|
| 84 |
+
+ x = self.blocks[i](x, ve_enc[i], x0, block_masks[i])
|
| 85 |
+
skip_connections.append(x)
|
| 86 |
+
# Decoder pass - process the remaining blocks with weighted skip connections
|
| 87 |
+
+ block_masks.reverse()
|
| 88 |
+
for i in range(self.num_decoder_layers):
|
| 89 |
+
x = x + self.skip_weights[i] * skip_connections.pop()
|
| 90 |
+
- x = self.blocks[self.num_encoder_layers + i](x, ve_dec[i], x0, block_mask)
|
| 91 |
+
+ x = self.blocks[self.num_encoder_layers + i](x, ve_dec[i], x0, block_masks[i])
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
### Attention Scale Modification
|
| 95 |
+
|
| 96 |
+
We currently use QK-Normalization to stabilize the attention coefficients. This helps [reduce the wallclock time of the speedrun](https://x.com/kellerjordan0/status/1845865698532450646). However, unlike in larger-scale models such as [ViT-22B](https://arxiv.org/pdf/2302.05442) and [Chameleon](https://arxiv.org/pdf/2405.09818v1), we use a parameter-free RMSNorm instead of the usual LayerNorm with learnable parameters.
|
| 97 |
+
|
| 98 |
+
But while the parameter-free RMSNorm is faster and leads to more stable training runs, it also constrains the logit sharpness and consequently the entropy of the attention coefficients to be in the same range across different layers. And in out setup, this leads to higher attention entropies which means the model is less "certain" which tokens to "attend to" during training. While not problematic early in training as we also don't want the model to overfit early on, it can be problematic later on when we want the model to "focus" on the most important tokens. And the current record is now tight-enough for this to be a problem.
|
| 99 |
+
|
| 100 |
+

|
| 101 |
+
|
| 102 |
+
To fix this issue, we first tried out (1) RMSNorm with learned channel-wise parameters and (2) a learned scalar "attention scale" parameter, one for each Attenion layer. Both approaches allowed us to reduce training steps by 20, with a ~0.5-0.7 ms/step overhead. Overall, the wallclock time reduction was ~2-3 secs.
|
| 103 |
+
|
| 104 |
+
Strangely, the models seemed to consistently learn a UNet-like attention scales pattern. And hardcoding this pattern lead to roughly the same results (e.g. `attn_scale(layer_idx) := 0.12 + 0.01 * min(layer_idx, 11 - layer_idx)`). We find this interesting and could be a potential area for future research. But fow now, we offer now explanation why this pattern emerges and why it works well aside from divine intervention.
|
| 105 |
+
|
| 106 |
+

|
| 107 |
+
|
| 108 |
+
We eventually settled with simply setting the attention scale to `0.12` (vs. the default `1.0 / sqrt(d_model)`) for all layers. This leads to the same 20 step reduction, but with no per-step overhead; an overall speed gain for ~3 secs.
|
| 109 |
+
|
| 110 |
+
```diff
|
| 111 |
+
# In CausalSelfAttention.__init__
|
| 112 |
+
+ self.attn_scale = 0.12
|
| 113 |
+
...
|
| 114 |
+
# In CausalSelfAttention.forward
|
| 115 |
+
- y = flex_attention(q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2), block_mask=block_mask)
|
| 116 |
+
+ y = flex_attention(q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2), block_mask=block_mask, scale=self.attn_scale)
|
| 117 |
+
```
|
| 118 |
+
|
| 119 |
+
For logs on learnable attention scales, see: [README for 01/12/25 record attempt](https://github.com/leloykun/modded-nanogpt/blob/fc--learnable-attn-scale/records/011225_LearnableAttnScale/README.md)
|
| 120 |
+
|
| 121 |
+
### Stacked QKV Weights & Batched Muon Implementation
|
| 122 |
+
|
| 123 |
+
This is an implementation/compiler-level optimization that leads to a 1-2 secs speed improvement. The crux is that, with a big enough GPU, doing one massive matmul for the QKV weights is faster than doing three smaller matmuls, one for each of the weights.
|
| 124 |
+
|
| 125 |
+
The problem, however, is that Muon performs better on the unmerged QKV weights primarily due to the massive matmuls in its Newton-Schulz iterations. Our previous implementation involved storing these weights separately as before but concatenating them in the forward pass. But this concatenation operation introduced a ~1 sec regression. Finally, we got rid of this overhead by stacking the QKV weights instead and using a batched implementation of Muon.
|
| 126 |
+
|
| 127 |
+
### Adam `eps=1e-10` fix
|
| 128 |
+
|
| 129 |
+
The speedrun is so tight now that even Adam's default epsilon parameter is already causing problems.
|
| 130 |
+
|
| 131 |
+
For context, we initialize our LM head as a zero matrix. This leads to small gradients early on in training which could sometimes be even smaller than Adam's default epsilon--causing training instability and increased validation loss.
|
| 132 |
+
|
| 133 |
+
To address this issue, we simply reduced Adam's `eps` from `1e-8` down to `1e-10`. This lead to a 0.0014 validation loss improvement with no per-step overhead; thereby allowing us to reduce training steps by 10.
|
| 134 |
+
|
| 135 |
+
```diff
|
| 136 |
+
- optimizer1 = torch.optim.Adam(adam_params, betas=(0.8, 0.95), fused=True)
|
| 137 |
+
+ optimizer1 = torch.optim.Adam(adam_params, betas=(0.8, 0.95), fused=True, eps=1e-10)
|
| 138 |
+
```
|
records/011625_Sub3Min/attn-entropy.png
ADDED

|
records/011625_Sub3Min/attn-scales-pattern.gif
ADDED
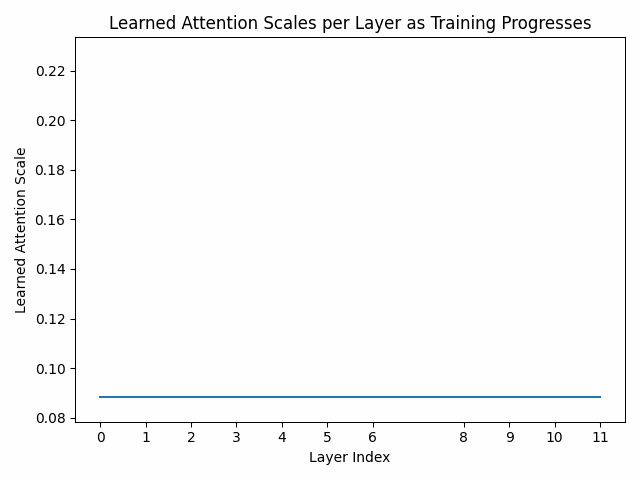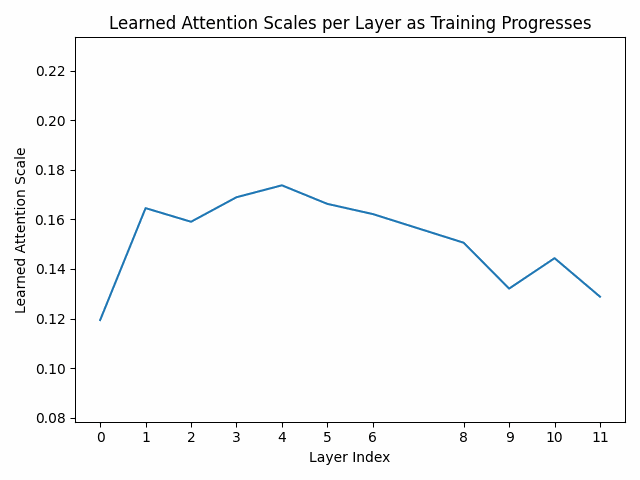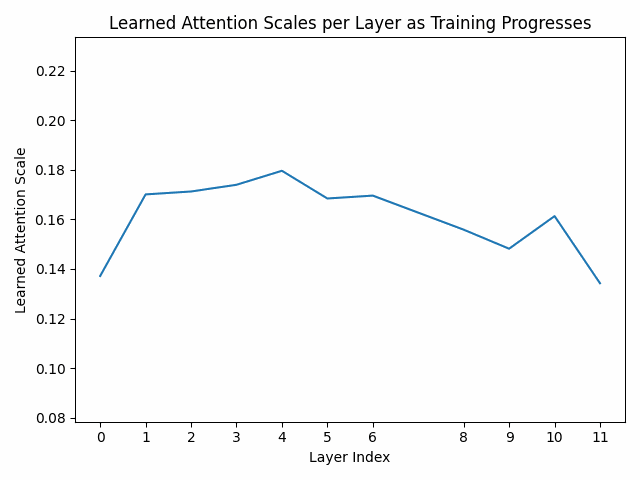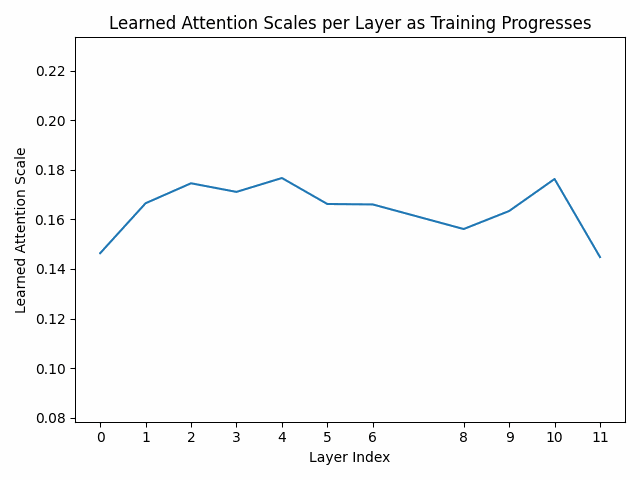
|
records/011625_Sub3Min/learned-attn-scales.png
ADDED
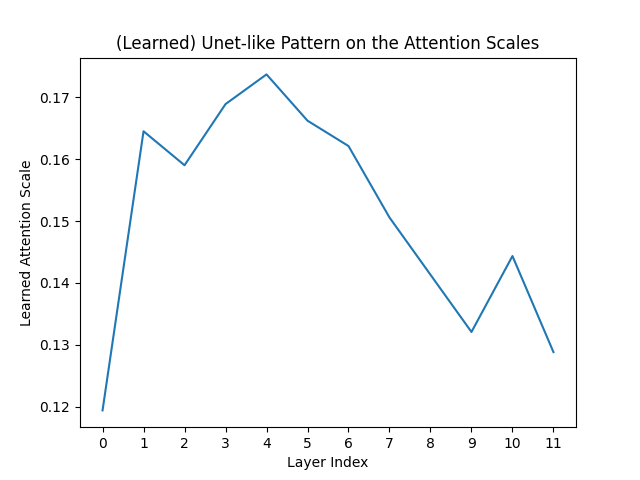
|
records/011625_Sub3Min/long-short-swa.png
ADDED

|
Git LFS Details
|
records/011825_GPT2Medium/241dd7a7-3d76-4dce-85a4-7df60387f32a.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/011825_GPT2Medium/main.log
ADDED
|
@@ -0,0 +1,241 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
s:0 tel:10.9830
|
| 2 |
+
s:250 tel:6.3097
|
| 3 |
+
s:500 tel:5.5887
|
| 4 |
+
s:750 tel:4.9040
|
| 5 |
+
s:1000 tel:4.3734
|
| 6 |
+
s:1250 tel:4.1307
|
| 7 |
+
s:1500 tel:3.9782
|
| 8 |
+
s:1750 tel:3.8681
|
| 9 |
+
s:2000 tel:3.7884
|
| 10 |
+
s:2250 tel:3.7278
|
| 11 |
+
s:2500 tel:3.6737
|
| 12 |
+
s:2750 tel:3.6324
|
| 13 |
+
s:3000 tel:3.6014
|
| 14 |
+
s:3250 tel:3.5695
|
| 15 |
+
s:3500 tel:3.5400
|
| 16 |
+
s:3750 tel:3.5161
|
| 17 |
+
s:4000 tel:3.4925
|
| 18 |
+
s:4250 tel:3.4754
|
| 19 |
+
s:4500 tel:3.4540
|
| 20 |
+
s:4750 tel:3.4349
|
| 21 |
+
s:5000 tel:3.4190
|
| 22 |
+
s:5250 tel:3.4076
|
| 23 |
+
s:5500 tel:3.3982
|
| 24 |
+
s:5750 tel:3.3842
|
| 25 |
+
s:6000 tel:3.3674
|
| 26 |
+
s:6250 tel:3.3589
|
| 27 |
+
s:6500 tel:3.3493
|
| 28 |
+
s:6750 tel:3.3442
|
| 29 |
+
s:7000 tel:3.3309
|
| 30 |
+
s:7250 tel:3.3207
|
| 31 |
+
s:7500 tel:3.3110
|
| 32 |
+
s:7750 tel:3.3055
|
| 33 |
+
s:8000 tel:3.2969
|
| 34 |
+
s:8250 tel:3.2885
|
| 35 |
+
s:8500 tel:3.2813
|
| 36 |
+
s:8750 tel:3.2780
|
| 37 |
+
s:9000 tel:3.2689
|
| 38 |
+
s:9250 tel:3.2654
|
| 39 |
+
s:9500 tel:3.2574
|
| 40 |
+
s:9750 tel:3.2507
|
| 41 |
+
s:10000 tel:3.2461
|
| 42 |
+
s:10250 tel:3.2401
|
| 43 |
+
s:10500 tel:3.2369
|
| 44 |
+
s:10750 tel:3.2297
|
| 45 |
+
s:11000 tel:3.2247
|
| 46 |
+
s:11250 tel:3.2212
|
| 47 |
+
s:11500 tel:3.2165
|
| 48 |
+
s:11750 tel:3.2135
|
| 49 |
+
s:12000 tel:3.2063
|
| 50 |
+
s:12250 tel:3.2048
|
| 51 |
+
s:12500 tel:3.1993
|
| 52 |
+
s:12750 tel:3.1969
|
| 53 |
+
s:13000 tel:3.1934
|
| 54 |
+
s:13250 tel:3.1887
|
| 55 |
+
s:13500 tel:3.1873
|
| 56 |
+
s:13750 tel:3.1823
|
| 57 |
+
s:14000 tel:3.1819
|
| 58 |
+
s:14250 tel:3.1758
|
| 59 |
+
s:14500 tel:3.1715
|
| 60 |
+
s:14750 tel:3.1668
|
| 61 |
+
s:15000 tel:3.1648
|
| 62 |
+
s:15250 tel:3.1618
|
| 63 |
+
s:15500 tel:3.1589
|
| 64 |
+
s:15750 tel:3.1562
|
| 65 |
+
s:16000 tel:3.1533
|
| 66 |
+
s:16250 tel:3.1508
|
| 67 |
+
s:16500 tel:3.1466
|
| 68 |
+
s:16750 tel:3.1450
|
| 69 |
+
s:17000 tel:3.1448
|
| 70 |
+
s:17250 tel:3.1398
|
| 71 |
+
s:17500 tel:3.1355
|
| 72 |
+
s:17750 tel:3.1342
|
| 73 |
+
s:18000 tel:3.1311
|
| 74 |
+
s:18250 tel:3.1281
|
| 75 |
+
s:18500 tel:3.1258
|
| 76 |
+
s:18750 tel:3.1229
|
| 77 |
+
s:19000 tel:3.1240
|
| 78 |
+
s:19250 tel:3.1195
|
| 79 |
+
s:19500 tel:3.1167
|
| 80 |
+
s:19750 tel:3.1144
|
| 81 |
+
s:20000 tel:3.1129
|
| 82 |
+
s:20250 tel:3.1115
|
| 83 |
+
s:20500 tel:3.1091
|
| 84 |
+
s:20750 tel:3.1074
|
| 85 |
+
s:21000 tel:3.1037
|
| 86 |
+
s:21250 tel:3.1012
|
| 87 |
+
s:21500 tel:3.1006
|
| 88 |
+
s:21750 tel:3.0981
|
| 89 |
+
s:22000 tel:3.0951
|
| 90 |
+
s:22250 tel:3.0938
|
| 91 |
+
s:22500 tel:3.0920
|
| 92 |
+
s:22750 tel:3.0897
|
| 93 |
+
s:23000 tel:3.0888
|
| 94 |
+
s:23250 tel:3.0845
|
| 95 |
+
s:23500 tel:3.0850
|
| 96 |
+
s:23750 tel:3.0812
|
| 97 |
+
s:24000 tel:3.0794
|
| 98 |
+
s:24250 tel:3.0773
|
| 99 |
+
s:24500 tel:3.0755
|
| 100 |
+
s:24750 tel:3.0758
|
| 101 |
+
s:25000 tel:3.0728
|
| 102 |
+
s:25250 tel:3.0708
|
| 103 |
+
s:25500 tel:3.0677
|
| 104 |
+
s:25750 tel:3.0676
|
| 105 |
+
s:26000 tel:3.0654
|
| 106 |
+
s:26250 tel:3.0631
|
| 107 |
+
s:26500 tel:3.0604
|
| 108 |
+
s:26750 tel:3.0589
|
| 109 |
+
s:27000 tel:3.0587
|
| 110 |
+
s:27250 tel:3.0572
|
| 111 |
+
s:27500 tel:3.0553
|
| 112 |
+
s:27750 tel:3.0534
|
| 113 |
+
s:28000 tel:3.0525
|
| 114 |
+
s:28250 tel:3.0501
|
| 115 |
+
s:28500 tel:3.0486
|
| 116 |
+
s:28750 tel:3.0462
|
| 117 |
+
s:29000 tel:3.0456
|
| 118 |
+
s:29250 tel:3.0437
|
| 119 |
+
s:29500 tel:3.0406
|
| 120 |
+
s:29750 tel:3.0409
|
| 121 |
+
s:30000 tel:3.0387
|
| 122 |
+
s:30250 tel:3.0370
|
| 123 |
+
s:30500 tel:3.0369
|
| 124 |
+
s:30750 tel:3.0334
|
| 125 |
+
s:31000 tel:3.0320
|
| 126 |
+
s:31250 tel:3.0306
|
| 127 |
+
s:31500 tel:3.0289
|
| 128 |
+
s:31750 tel:3.0280
|
| 129 |
+
s:32000 tel:3.0252
|
| 130 |
+
s:32250 tel:3.0259
|
| 131 |
+
s:32500 tel:3.0239
|
| 132 |
+
s:32750 tel:3.0227
|
| 133 |
+
s:33000 tel:3.0194
|
| 134 |
+
s:33250 tel:3.0189
|
| 135 |
+
s:33500 tel:3.0168
|
| 136 |
+
s:33750 tel:3.0168
|
| 137 |
+
s:34000 tel:3.0138
|
| 138 |
+
s:34250 tel:3.0125
|
| 139 |
+
s:34500 tel:3.0116
|
| 140 |
+
s:34750 tel:3.0100
|
| 141 |
+
s:35000 tel:3.0082
|
| 142 |
+
s:35250 tel:3.0075
|
| 143 |
+
s:35500 tel:3.0051
|
| 144 |
+
s:35750 tel:3.0037
|
| 145 |
+
s:36000 tel:3.0026
|
| 146 |
+
s:36250 tel:3.0015
|
| 147 |
+
s:36500 tel:3.0000
|
| 148 |
+
s:36750 tel:2.9987
|
| 149 |
+
s:37000 tel:2.9974
|
| 150 |
+
s:37250 tel:2.9954
|
| 151 |
+
s:37500 tel:2.9938
|
| 152 |
+
s:37750 tel:2.9927
|
| 153 |
+
s:38000 tel:2.9911
|
| 154 |
+
s:38250 tel:2.9901
|
| 155 |
+
s:38500 tel:2.9890
|
| 156 |
+
s:38750 tel:2.9871
|
| 157 |
+
s:39000 tel:2.9865
|
| 158 |
+
s:39250 tel:2.9847
|
| 159 |
+
s:39500 tel:2.9833
|
| 160 |
+
s:39750 tel:2.9818
|
| 161 |
+
s:40000 tel:2.9812
|
| 162 |
+
s:40250 tel:2.9798
|
| 163 |
+
s:40500 tel:2.9781
|
| 164 |
+
s:40750 tel:2.9772
|
| 165 |
+
s:41000 tel:2.9762
|
| 166 |
+
s:41250 tel:2.9749
|
| 167 |
+
s:41500 tel:2.9734
|
| 168 |
+
s:41750 tel:2.9724
|
| 169 |
+
s:42000 tel:2.9717
|
| 170 |
+
s:42250 tel:2.9702
|
| 171 |
+
s:42500 tel:2.9685
|
| 172 |
+
s:42750 tel:2.9681
|
| 173 |
+
s:43000 tel:2.9667
|
| 174 |
+
s:43250 tel:2.9651
|
| 175 |
+
s:43500 tel:2.9641
|
| 176 |
+
s:43750 tel:2.9633
|
| 177 |
+
s:44000 tel:2.9638
|
| 178 |
+
s:44250 tel:2.9612
|
| 179 |
+
s:44500 tel:2.9599
|
| 180 |
+
s:44750 tel:2.9592
|
| 181 |
+
s:45000 tel:2.9581
|
| 182 |
+
s:45250 tel:2.9569
|
| 183 |
+
s:45500 tel:2.9563
|
| 184 |
+
s:45750 tel:2.9549
|
| 185 |
+
s:46000 tel:2.9541
|
| 186 |
+
s:46250 tel:2.9530
|
| 187 |
+
s:46500 tel:2.9520
|
| 188 |
+
s:46750 tel:2.9515
|
| 189 |
+
s:47000 tel:2.9504
|
| 190 |
+
s:47250 tel:2.9494
|
| 191 |
+
s:47500 tel:2.9485
|
| 192 |
+
s:47750 tel:2.9475
|
| 193 |
+
s:48000 tel:2.9467
|
| 194 |
+
s:48250 tel:2.9459
|
| 195 |
+
s:48500 tel:2.9451
|
| 196 |
+
s:48750 tel:2.9440
|
| 197 |
+
s:49000 tel:2.9433
|
| 198 |
+
s:49250 tel:2.9428
|
| 199 |
+
s:49500 tel:2.9419
|
| 200 |
+
s:49750 tel:2.9413
|
| 201 |
+
s:50000 tel:2.9405
|
| 202 |
+
s:50250 tel:2.9399
|
| 203 |
+
s:50500 tel:2.9394
|
| 204 |
+
s:50750 tel:2.9388
|
| 205 |
+
s:51000 tel:2.9379
|
| 206 |
+
s:51250 tel:2.9374
|
| 207 |
+
s:51500 tel:2.9367
|
| 208 |
+
s:51750 tel:2.9361
|
| 209 |
+
s:52000 tel:2.9357
|
| 210 |
+
s:52250 tel:2.9350
|
| 211 |
+
s:52500 tel:2.9346
|
| 212 |
+
s:52750 tel:2.9341
|
| 213 |
+
s:53000 tel:2.9336
|
| 214 |
+
s:53250 tel:2.9332
|
| 215 |
+
s:53500 tel:2.9328
|
| 216 |
+
s:53750 tel:2.9324
|
| 217 |
+
s:54000 tel:2.9320
|
| 218 |
+
s:54250 tel:2.9317
|
| 219 |
+
s:54500 tel:2.9314
|
| 220 |
+
s:54750 tel:2.9309
|
| 221 |
+
s:55000 tel:2.9306
|
| 222 |
+
s:55250 tel:2.9303
|
| 223 |
+
s:55500 tel:2.9301
|
| 224 |
+
s:55750 tel:2.9299
|
| 225 |
+
s:56000 tel:2.9296
|
| 226 |
+
s:56250 tel:2.9294
|
| 227 |
+
s:56500 tel:2.9292
|
| 228 |
+
s:56750 tel:2.9290
|
| 229 |
+
s:57000 tel:2.9289
|
| 230 |
+
s:57250 tel:2.9287
|
| 231 |
+
s:57500 tel:2.9286
|
| 232 |
+
s:57750 tel:2.9285
|
| 233 |
+
s:58000 tel:2.9284
|
| 234 |
+
s:58250 tel:2.9283
|
| 235 |
+
s:58500 tel:2.9283
|
| 236 |
+
s:58750 tel:2.9282
|
| 237 |
+
s:59000 tel:2.9282
|
| 238 |
+
s:59250 tel:2.9282
|
| 239 |
+
s:59500 tel:2.9282
|
| 240 |
+
s:59750 tel:2.9281
|
| 241 |
+
s:60000 tel:2.9282
|
records/012625_BatchSize/0bdd5ee9-ac28-4202-bdf1-c906b102b0ec.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/012625_BatchSize/README.md
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 11/26/25 - Misc Tweaks
|
| 2 |
+
|
| 3 |
+
Changelogs:
|
| 4 |
+
|
| 5 |
+
1. Reduced per-device training sequence length from `64*1024` to `48*1024`. See [Critical Batch Size](https://arxiv.org/abs/2410.21676) literature.
|
| 6 |
+
2. Increased per-device eval sequence length from `64*1024` to `4*64*1024`. This improves `val_loss` by `~0.0015` or an equivalent of a reduction of 10 training steps. Overall it saves `~1 sec` of training time.
|
| 7 |
+
3. Modified scales for `fp8` training of LM Head. Saves `1 sec` and improves `val_loss` by as much as `~0.01` after reducing training sequence length down to `48*1024`. I don't know wtf is causing this and I'm NOT going crazy about this. I have evidence. See `records/012625_MiscTweaks/no-autocast-same-fp8-scales`.
|
| 8 |
+
- `w_s = 2.0**9` (from `2.0**5`)
|
| 9 |
+
- `grad_s = 2.0**19` (from `2.0**29`)
|
| 10 |
+
4. Upgraded PyTorch to 2.7.0 nightly version (20250125) for CUDA 12.6
|
| 11 |
+
- `pip install --pre torch==2.7.0.dev20250125+cu126 --index-url https://download.pytorch.org/whl/nightly/cu126`
|
| 12 |
+
|
| 13 |
+

|
| 14 |
+

|
| 15 |
+
|
| 16 |
+
```python
|
| 17 |
+
accs = [3.2806, 3.2771, 3.2829, 3.2813, 3.2789, 3.2774, 3.2798, 3.2759, 3.2794,
|
| 18 |
+
3.2775, 3.2768, 3.2793, 3.2838, 3.2779, 3.2782, 3.2770, 3.2775, 3.2784,
|
| 19 |
+
3.2782, 3.2776, 3.2814, 3.2785, 3.2793, 3.2797, 3.2782, 3.2789, 3.2759,
|
| 20 |
+
3.2803, 3.2780, 3.2782, 3.2744, 3.2819, 3.2801, 3.2782, 3.2771, 3.2782,
|
| 21 |
+
3.2792, 3.2778, 3.2774, 3.2798, 3.2799, 3.2768, 3.2814, 3.2816, 3.2785,
|
| 22 |
+
3.2817, 3.2801, 3.2755, 3.2780, 3.2774, 3.2797, 3.2789, 3.2843, 3.2777,
|
| 23 |
+
3.2777, 3.2768, 3.2763, 3.2773, 3.2792, 3.2819, 3.2778, 3.2792, 3.2782,
|
| 24 |
+
3.2776, 3.2752, 3.2792, 3.2786, 3.2793, 3.2773, 3.2804, 3.2802, 3.2779,
|
| 25 |
+
3.2780, 3.2779, 3.2801, 3.2773, 3.2802, 3.2770, 3.2785, 3.2772, 3.2818]
|
| 26 |
+
|
| 27 |
+
import scipy.stats
|
| 28 |
+
print(f'p={scipy.stats.ttest_1samp(accs, 3.28, alternative='less').pvalue:.8f}')
|
| 29 |
+
# p=0.00000002 (statistically significant)
|
| 30 |
+
|
| 31 |
+
import torch
|
| 32 |
+
print(torch.std_mean(torch.tensor(accs)))
|
| 33 |
+
# (tensor(0.0019), tensor(3.2787))
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
---
|
| 37 |
+
|
| 38 |
+

|
records/012625_BatchSize/ablations.png
ADDED

|
Git LFS Details
|
records/012625_BatchSize/c44090cc-1b99-4c95-8624-38fb4b5834f9.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/012625_BatchSize/val_losses.png
ADDED

|