
mauricerupp
commited on
Commit
·
381af13
1
Parent(s):
b85bdac
init
Browse files- LR_BERT.png +0 -0
- README.md +38 -0
- config.json +21 -0
- evalloss_BERT.png +0 -0
- loss_BERT.png +0 -0
- pytorch_model.bin +3 -0
- training_args.bin +3 -0
LR_BERT.png
ADDED
|
README.md
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# PolitBERT
|
| 2 |
+
|
| 3 |
+
## Background
|
| 4 |
+
|
| 5 |
+
This model was created to specialize on political speeches, interviews and press briefings of English-speaking politicians.
|
| 6 |
+
|
| 7 |
+
## Training
|
| 8 |
+
The model was initialized using the pre-trained weights of BERT<sub>BASE</sub> and trained for 20 epochs on the standard MLM task with default parameters.
|
| 9 |
+
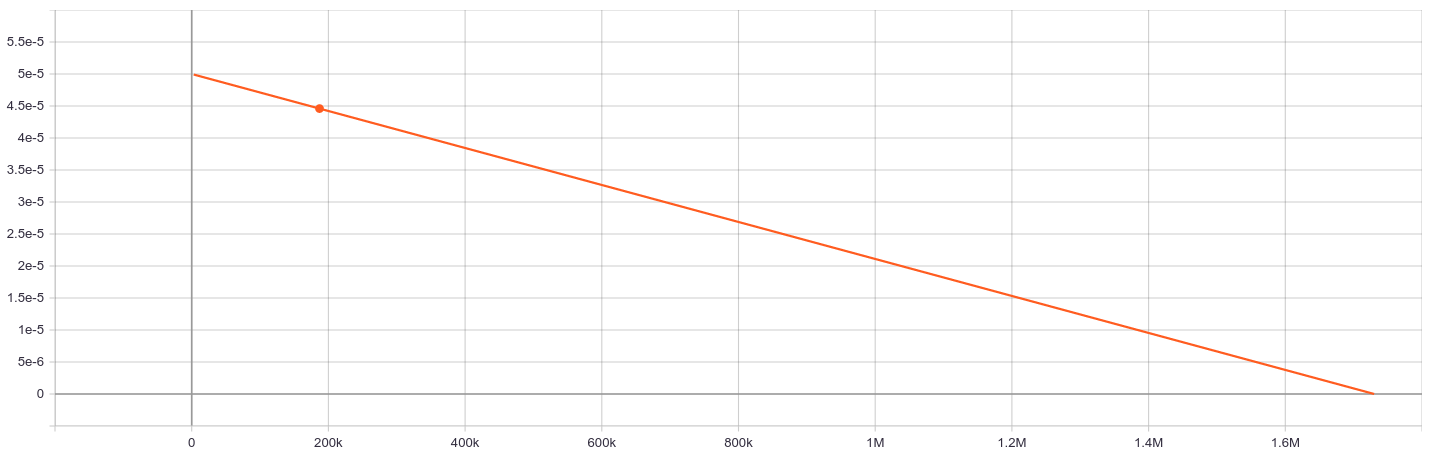
The used learning rate was 5e-5 with a linearly decreasing schedule and AdamW.
|
| 10 |
+
The used batch size is 8 per GPU while beeing trained on two Nvidia GTX TITAN X.
|
| 11 |
+
The rest of the used configuration is the same as in ```AutoConfig.from_pretrained('bert-base-uncased')```.
|
| 12 |
+
As a tokenizer the default tokenizer of BERT was used (```BertTokenizer.from_pretrained('bert-base-uncased')```)
|
| 13 |
+
|
| 14 |
+
## Dataset
|
| 15 |
+
PolitBERT was trained on the following dataset, which has been split up into single sentences:
|
| 16 |
+
<https://www.kaggle.com/mauricerupp/englishspeaking-politicians>
|
| 17 |
+
|
| 18 |
+
## Usage
|
| 19 |
+
To predict a missing word of a sentence, the following pipeline can be applied:
|
| 20 |
+
|
| 21 |
+
```
|
| 22 |
+
from transformers import pipeline, BertTokenizer, AutoModel
|
| 23 |
+
|
| 24 |
+
fill_mask = pipeline("fill-mask",
|
| 25 |
+
model=AutoModel.from_pretrained('maurice/PolitBERT'),
|
| 26 |
+
tokenizer=BertTokenizer.from_pretrained('bert-base-uncased'))
|
| 27 |
+
|
| 28 |
+
print(fill_mask('Donald Trump is a [MASK].'))
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
## Training Results
|
| 32 |
+
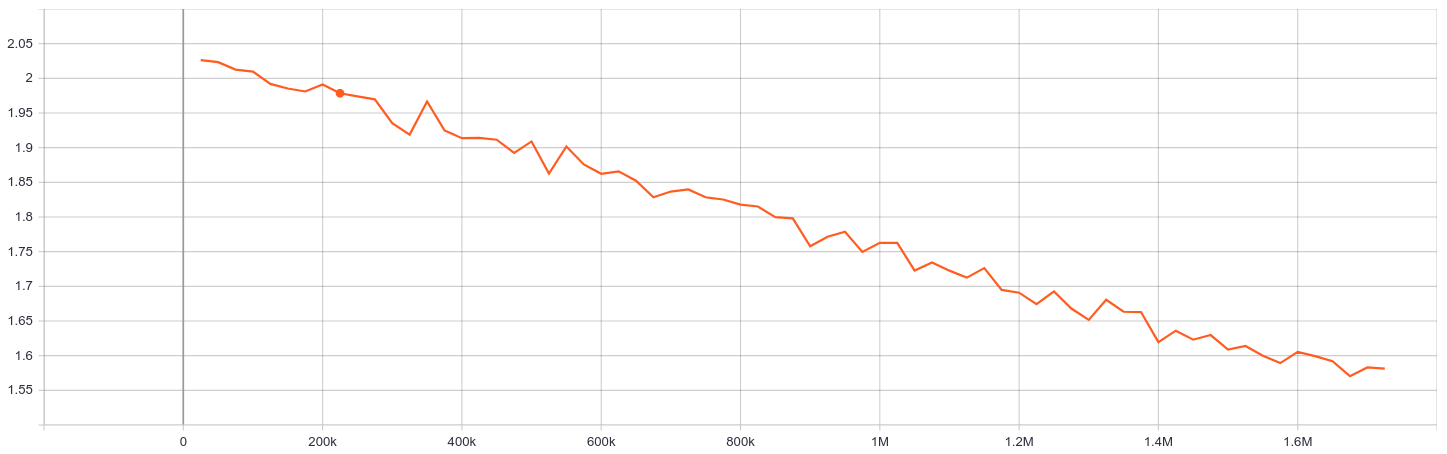
Evaluation Loss:
|
| 33 |
+

|
| 34 |
+
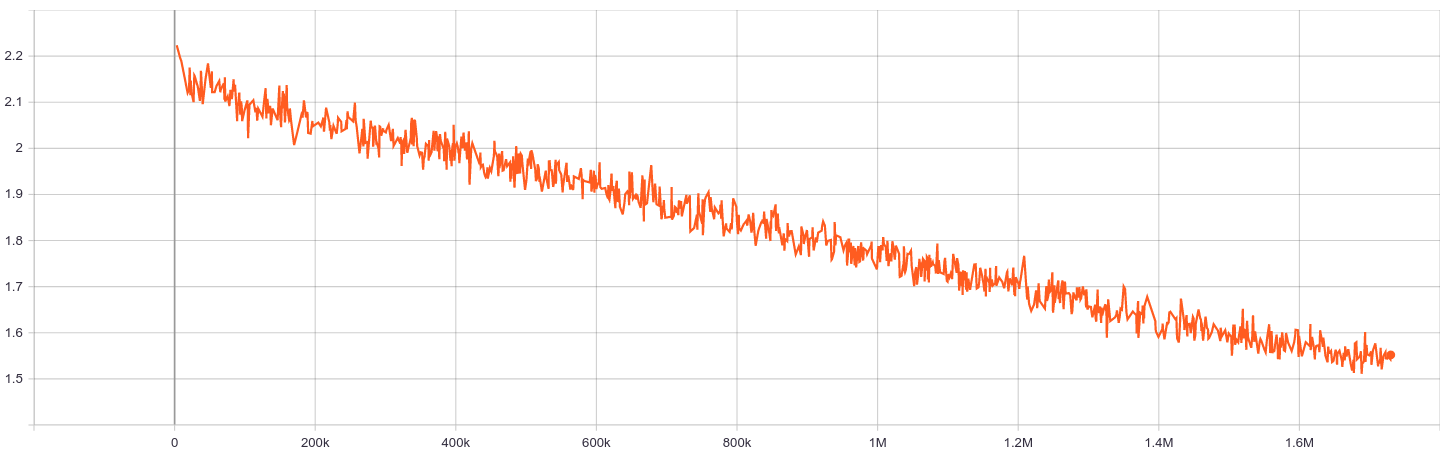
Training Loss:
|
| 35 |
+

|
| 36 |
+
Learning Rate Schedule:
|
| 37 |
+

|
| 38 |
+
|
config.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "bert-base-uncased",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"BertForMaskedLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"gradient_checkpointing": false,
|
| 8 |
+
"hidden_act": "gelu",
|
| 9 |
+
"hidden_dropout_prob": 0.1,
|
| 10 |
+
"hidden_size": 768,
|
| 11 |
+
"initializer_range": 0.02,
|
| 12 |
+
"intermediate_size": 3072,
|
| 13 |
+
"layer_norm_eps": 1e-12,
|
| 14 |
+
"max_position_embeddings": 512,
|
| 15 |
+
"model_type": "bert",
|
| 16 |
+
"num_attention_heads": 12,
|
| 17 |
+
"num_hidden_layers": 12,
|
| 18 |
+
"pad_token_id": 0,
|
| 19 |
+
"type_vocab_size": 2,
|
| 20 |
+
"vocab_size": 30522
|
| 21 |
+
}
|
evalloss_BERT.png
ADDED
|
loss_BERT.png
ADDED
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bd89d77f92b6cc7ea4eeae1fbfa86d78d5477e871919fec352c3582837c3b813
|
| 3 |
+
size 438147282
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ac5123eac1bfaa1ee8670a68373af816ddceca90e6bcf4102f6d1cb72df4ec5a
|
| 3 |
+
size 1839
|