---
license: apache-2.0
language:
- en
metrics:
- recall
base_model:
- friedrichor/Unite-Base-Qwen2-VL-7B
tags:
- sentence-transformers
- sentence-similarity
- transformers
- multimodal
- retrieval
- feature-extraction
- image-text-to-text
- video-text-to-text
- any-to-any
datasets:
- friedrichor/Unite-Instruct-Retrieval-Train
---
## Modality Curation: Building Universal Embeddings for Advanced Multimodal Information Retrieval
[](https://opensource.org/licenses/Apache-2.0)
[](https://huggingface.co/papers/2505.19650)
[](https://github.com/friedrichor/UNITE)
[](https://friedrichor.github.io/projects/UNITE)
[](https://huggingface.co/collections/friedrichor/unite-682da30c4540abccd3da3a6b)
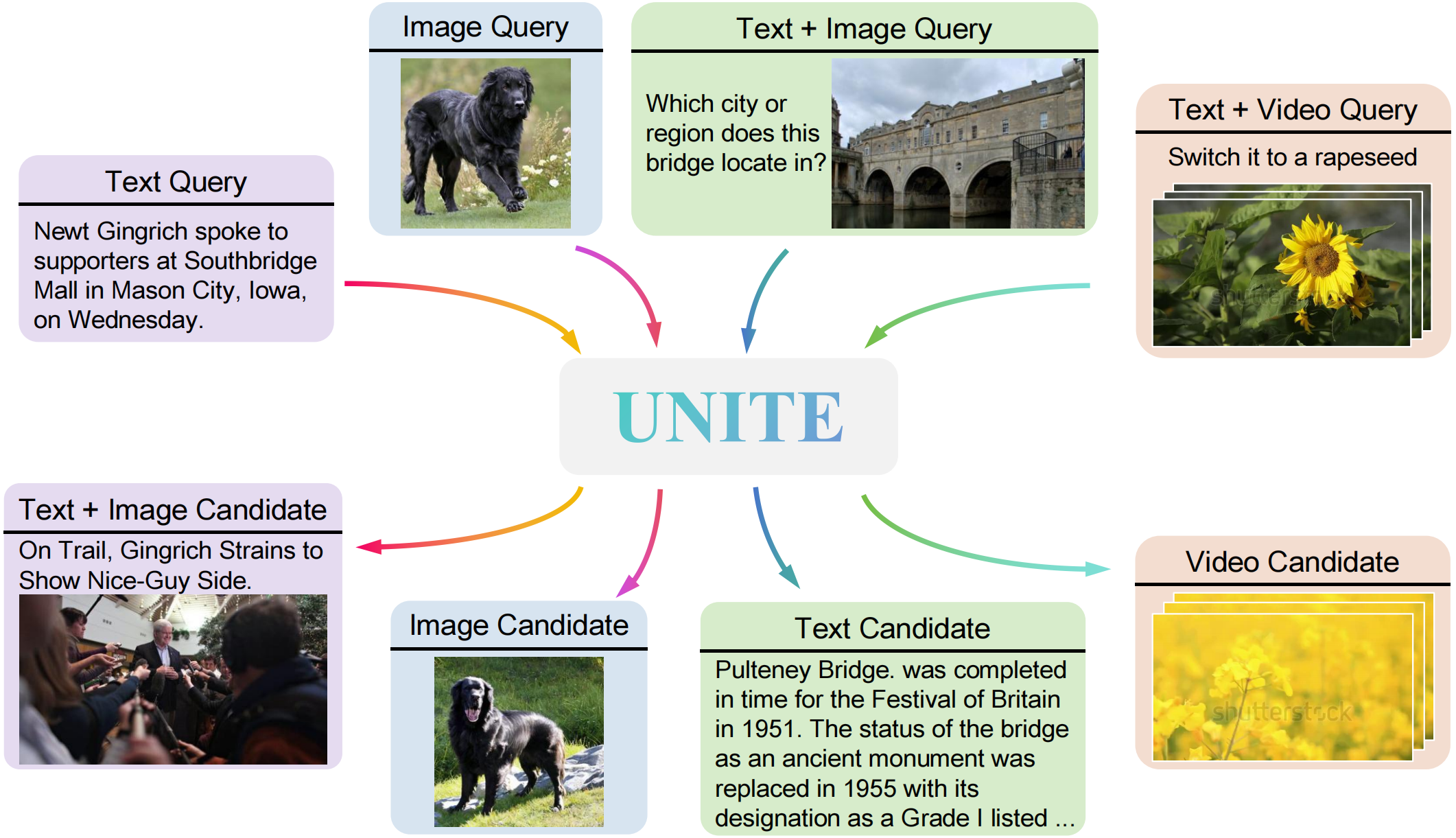
## UNITE: UNIversal mulTimodal Embedder
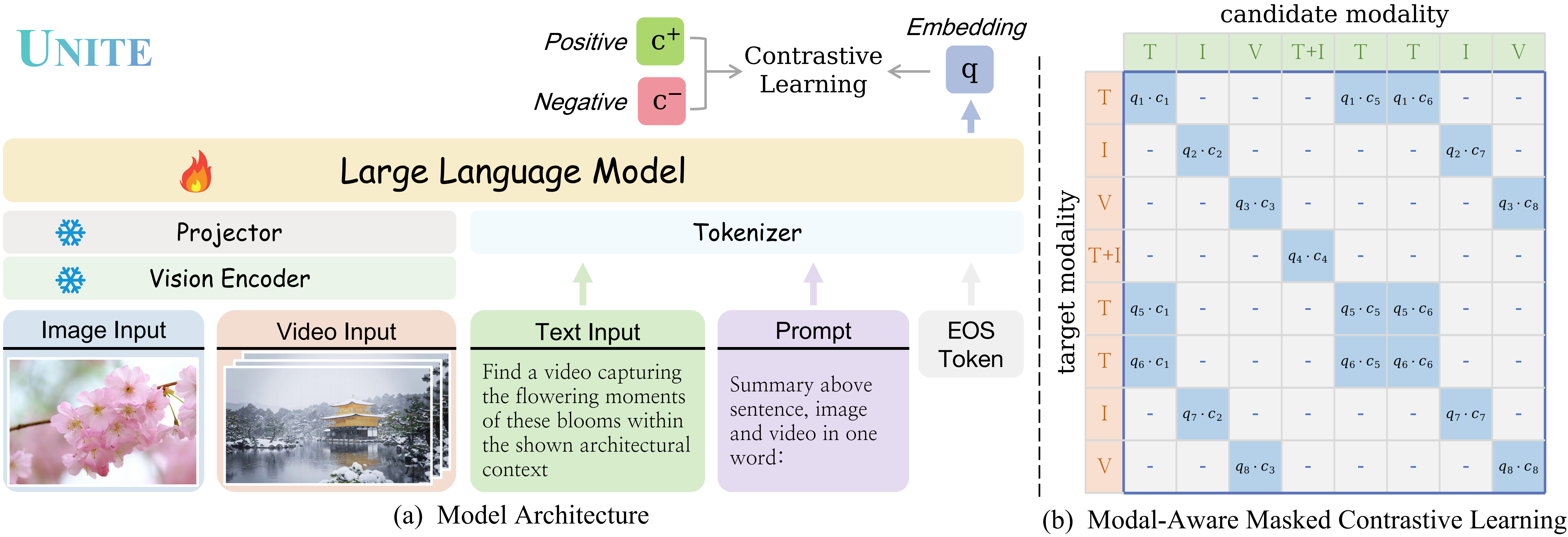
**Support Modalities and Tasks:**
⚡ **Unified Multimodal Representations:** *text*, *image*, *video*, and *their fusion*.
⚡ **Enhancements in Diverse Tasks:** *coarse-grained retrieval*, *fine-grained retrieval* (Recommended UNITE-Base), and *instruction-based retrieval* (Recommended UNITE-Instruct)
## Requirements
```bash
pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0
pip install flash-attn --no-build-isolation
pip install transformers==4.47.1
pip install qwen-vl-utils[decord]==0.0.8
```
## Quickstart
```bash
# get inference code from https://huggingface.co/friedrichor/Unite-Base-Qwen2-VL-2B/tree/main/inference_demo
cd inference_demo
```
### Load Model
```python
import torch
from transformers import AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
from modeling_unite import UniteQwen2VL
model_path = 'friedrichor/Unite-Instruct-Qwen2-VL-7B'
model = UniteQwen2VL.from_pretrained(
model_path,
device_map="cuda",
torch_dtype=torch.bfloat16,
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = UniteQwen2VL.from_pretrained(
# model_path,
# device_map="cuda",
# torch_dtype=torch.bfloat16,
# attn_implementation='flash_attention_2',
# low_cpu_mem_usage=True,
# )
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
processor = AutoProcessor.from_pretrained(model_path, min_pixels=256*28*28, max_pixels=1280*28*28)
def process_messages(msg):
text = processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True) + "<|endoftext|>"
image_inputs, video_inputs = process_vision_info(msg)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
return inputs
```
### Inference
Image-Text Retrieval
```python
messages_txt = [
{
"role": "user",
"content": [
{"type": "text", "text": "The book titled 'Riding with Reindeer - A Bicycle Odyssey through Finland, Lapland, and the Arctic' provides a detailed account of a journey that explores the regions of Lapland and the Arctic, focusing on the experience of riding with reindeer."},
{"type": "text", "text": "\nSummary above sentence in one word:"},
],
}
]
messages_img = [
{
"role": "user",
"content": [
{"type": "image", "image": "./examples/518L0uDGe0L.jpg"},
{"type": "text", "text": "\nSummary above image in one word:"},
],
}
]
inputs_txt = process_messages(messages_txt)
inputs_img = process_messages(messages_img)
with torch.no_grad():
embeddings_txt = model(**inputs_txt) # [1, 3584]
embeddings_img = model(**inputs_img) # [1, 3584]
print(torch.matmul(embeddings_txt, embeddings_img.T))
# tensor([[0.7578]], dtype=torch.bfloat16)
```
Video-Text Retrieval
```python
messages_txt = [
{
"role": "user",
"content": [
{"type": "text", "text": "Timelapse of stormy clouds over open sea and snowcapped mountain"},
{"type": "text", "text": "\nSummary above sentence in one word:"},
],
}
]
messages_vid = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "./examples/stock-footage-timelapse-of-stormy-clouds-over-open-sea-and-snowcapped-mountain.mp4",
"max_pixels": 360 * 420,
"fps": 1,
"max_frames": 32
},
{"type": "text", "text": "\nSummary above video in one word:"},
],
}
]
inputs_txt = process_messages(messages_txt)
inputs_vid = process_messages(messages_vid)
with torch.no_grad():
embeddings_txt = model(**inputs_txt) # [1, 3584]
embeddings_vid = model(**inputs_vid) # [1, 3584]
print(torch.matmul(embeddings_txt, embeddings_vid.T))
# tensor([[0.4883]], dtype=torch.bfloat16)
```
Fused-Modal Retrieval
```python
messages_qry = [
{
"role": "user",
"content": [
{"type": "image", "image": "./examples/oven_05011373.jpg"},
{"type": "text", "text": "What is the name of this place?"},
{"type": "text", "text": "\nSummary above sentence and image in one word:"},
],
}
]
messages_tgt = [
{
"role": "user",
"content": [
{"type": "image", "image": "./examples/Q673659.jpg"},
{"type": "text", "text": "Marina Beach."},
{"type": "text", "text": "\nSummary above sentence and image in one word:"},
],
}
]
inputs_qry = process_messages(messages_qry)
inputs_tgt = process_messages(messages_tgt)
with torch.no_grad():
embeddings_qry = model(**inputs_qry) # [1, 3584]
embeddings_tgt = model(**inputs_tgt) # [1, 3584]
print(torch.matmul(embeddings_qry, embeddings_tgt.T))
# tensor([[0.6719]], dtype=torch.bfloat16)
```
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{kong2025modality,
title={Modality Curation: Building Universal Embeddings for Advanced Multimodal Information Retrieval},
author={Kong, Fanheng and Zhang, Jingyuan and Liu, Yahui and Zhang, Hongzhi and Feng, Shi and Yang, Xiaocui and Wang, Daling and Tian, Yu and W., Victoria and Zhang, Fuzheng and Zhou, Guorui},
journal={arXiv preprint arXiv:2505.19650},
year={2025}
}
```