

Update README.md
Browse files
README.md
CHANGED
|
@@ -1,3 +1,113 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: mit
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
thumbnail: >-
|
| 4 |
+
https://cdn-uploads.huggingface.co/production/uploads/6625f4a8a8d1362ebcc3851a/iyzgR89q50pp1T8HeeP15.png
|
| 5 |
+
base_model:
|
| 6 |
+
- cerebras/GLM-4.6
|
| 7 |
+
pipeline_tag: text-generation
|
| 8 |
+
tags:
|
| 9 |
+
- abliterated
|
| 10 |
+
- derestricted
|
| 11 |
+
- glm-4.6
|
| 12 |
+
- unlimited
|
| 13 |
+
- uncensored
|
| 14 |
+
library_name: transformers
|
| 15 |
+
---
|
| 16 |
+
<div align="left">
|
| 17 |
+
<img src=https://cdn-uploads.huggingface.co/production/uploads/6625f4a8a8d1362ebcc3851a/iyzgR89q50pp1T8HeeP15.png width="5%"/>
|
| 18 |
+
</div>
|
| 19 |
+
|
| 20 |
+
# Arli AI
|
| 21 |
+
|
| 22 |
+
# GLM-4.6-Derestricted
|
| 23 |
+
|
| 24 |
+
<div align="center">
|
| 25 |
+
<img src=https://cdn-uploads.huggingface.co/production/uploads/6625f4a8a8d1362ebcc3851a/XhCz9N4liIwWEh-yH37gR.png width="15%"/>
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
GLM-4.6-Derestricted is a **Derestricted** version of [GLM-4.6](https://huggingface.co/cerebras/GLM-4.6), created by **[Arli AI](https://www.arliai.com)**.
|
| 29 |
+
|
| 30 |
+
Our goal with this release is to provide a version of the model that removed refusal behaviors while maintaining the high-performance reasoning of the original GLM-4.6. This is unlike regular abliteration which often inadvertently "lobotomizes" the model.
|
| 31 |
+
|
| 32 |
+
### Methodology: Norm-Preserving Biprojected Abliteration
|
| 33 |
+
|
| 34 |
+
To achieve this, **[Arli AI](https://www.arliai.com)** utilized **Norm-Preserving Biprojected Abliteration**, a refined technique pioneered by Jim Lai (grimjim). You can read the full technical breakdown [in this article](https://huggingface.co/blog/grimjim/norm-preserving-biprojected-abliteration).
|
| 35 |
+
|
| 36 |
+
**Why this matters:**
|
| 37 |
+
|
| 38 |
+
Standard abliteration works by simply subtracting a "refusal vector" from the model's weights. While this works to uncensor a model, it is mathematically unprincipled. It alters the **magnitude** (or "loudness") of the neurons, destroying the delicate feature norms the model learned during training. This damage is why many uncensored models suffer from degraded logic or hallucinations.
|
| 39 |
+
|
| 40 |
+
**How Norm-Preserving Biprojected Abliteration fixes it:**
|
| 41 |
+
|
| 42 |
+
This model was modified using a three-step approach that removes refusals without breaking the model's brain:
|
| 43 |
+
|
| 44 |
+
1. **Biprojection (Targeting):** We refined the refusal direction to ensure it is mathematically orthogonal to "harmless" directions. This ensures that when we cut out the refusal behavior, we do not accidentally cut out healthy, harmless concepts.
|
| 45 |
+
2. **Decomposition:** Instead of a raw subtraction, we decomposed the model weights into **Magnitude** and **Direction**.
|
| 46 |
+
3. **Norm-Preservation:** We removed the refusal component solely from the *directional* aspect of the weights, then recombined them with their **original magnitudes**.
|
| 47 |
+
|
| 48 |
+
**The Result:**
|
| 49 |
+
|
| 50 |
+
By preserving the weight norms, we maintain the "importance" structure of the neural network. Benchmarks suggest that this method avoids the "Safety Tax"—not only effectively removing refusals but potentially **improving reasoning capabilities** over the baseline, as the model is no longer wasting compute resources on suppressing its own outputs.
|
| 51 |
+
|
| 52 |
+
In fact, you may find surprising new knowledge and capabilities that the original model does not initially expose.
|
| 53 |
+
|
| 54 |
+
**Quantization:**
|
| 55 |
+
|
| 56 |
+
- Original: https://huggingface.co/ArliAI/GLM-4.6-Derestricted
|
| 57 |
+
- FP8: https://huggingface.co/ArliAI/GLM-4.6-Derestricted-FP8
|
| 58 |
+
- INT8: https://huggingface.co/ArliAI/GLM-4.6-Derestricted-W8A8-INT8
|
| 59 |
+
- W4A16: https://huggingface.co/ArliAI/GLM-4.6-Derestricted-GPTQ-W4A16
|
| 60 |
+
|
| 61 |
+
---
|
| 62 |
+
|
| 63 |
+
## Original model card:
|
| 64 |
+
|
| 65 |
+
-# GLM-4.6
|
| 66 |
+
|
| 67 |
+
<div align="center">
|
| 68 |
+
<img src=https://raw.githubusercontent.com/zai-org/GLM-4.5/refs/heads/main/resources/logo.svg width="15%"/>
|
| 69 |
+
</div>
|
| 70 |
+
<p align="center">
|
| 71 |
+
👋 Join our <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community.
|
| 72 |
+
<br>
|
| 73 |
+
📖 Check out the GLM-4.6 <a href="https://z.ai/blog/glm-4.6" target="_blank">technical blog</a>, <a href="https://arxiv.org/abs/2508.06471" target="_blank">technical report(GLM-4.5)</a>, and <a href="https://zhipu-ai.feishu.cn/wiki/Gv3swM0Yci7w7Zke9E0crhU7n7D" target="_blank">Zhipu AI technical documentation</a>.
|
| 74 |
+
<br>
|
| 75 |
+
📍 Use GLM-4.6 API services on <a href="https://docs.z.ai/guides/llm/glm-4.6">Z.ai API Platform. </a>
|
| 76 |
+
<br>
|
| 77 |
+
👉 One click to <a href="https://chat.z.ai">GLM-4.6</a>.
|
| 78 |
+
</p>
|
| 79 |
+
|
| 80 |
+
## Model Introduction
|
| 81 |
+
|
| 82 |
+
Compared with GLM-4.5, **GLM-4.6** brings several key improvements:
|
| 83 |
+
|
| 84 |
+
* **Longer context window:** The context window has been expanded from 128K to 200K tokens, enabling the model to handle more complex agentic tasks.
|
| 85 |
+
* **Superior coding performance:** The model achieves higher scores on code benchmarks and demonstrates better real-world performance in applications such as Claude Code、Cline、Roo Code and Kilo Code, including improvements in generating visually polished front-end pages.
|
| 86 |
+
* **Advanced reasoning:** GLM-4.6 shows a clear improvement in reasoning performance and supports tool use during inference, leading to stronger overall capability.
|
| 87 |
+
* **More capable agents:** GLM-4.6 exhibits stronger performance in tool using and search-based agents, and integrates more effectively within agent frameworks.
|
| 88 |
+
* **Refined writing:** Better aligns with human preferences in style and readability, and performs more naturally in role-playing scenarios.
|
| 89 |
+
|
| 90 |
+
We evaluated GLM-4.6 across eight public benchmarks covering agents, reasoning, and coding. Results show clear gains over GLM-4.5, with GLM-4.6 also holding competitive advantages over leading domestic and international models such as **DeepSeek-V3.1-Terminus** and **Claude Sonnet 4**.
|
| 91 |
+
|
| 92 |
+
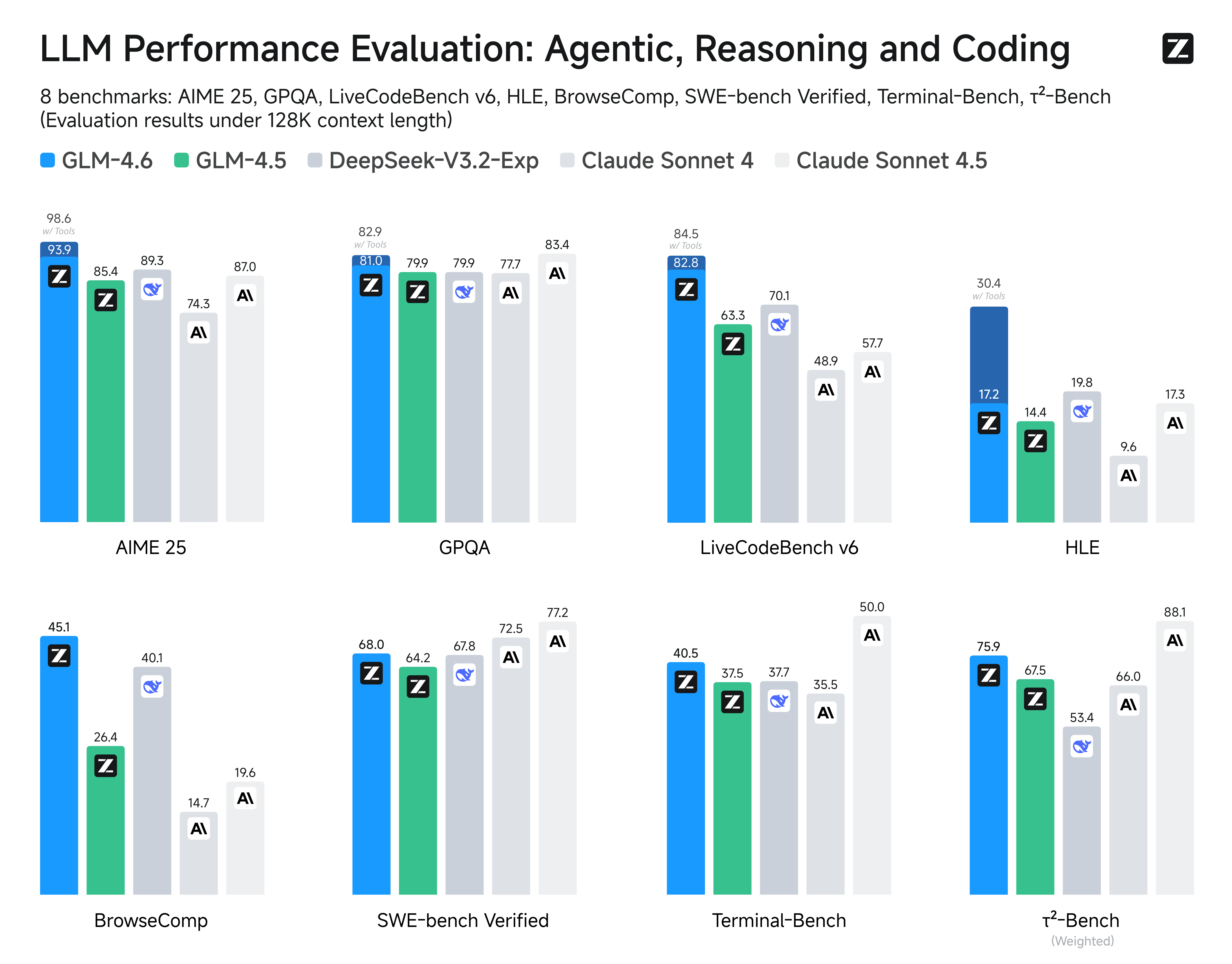
|
| 93 |
+
|
| 94 |
+
## Inference
|
| 95 |
+
|
| 96 |
+
**Both GLM-4.5 and GLM-4.6 use the same inference method.**
|
| 97 |
+
|
| 98 |
+
you can check our [github](https://github.com/zai-org/GLM-4.5) for more detail.
|
| 99 |
+
|
| 100 |
+
## Recommended Evaluation Parameters
|
| 101 |
+
|
| 102 |
+
For general evaluations, we recommend using a **sampling temperature of 1.0**.
|
| 103 |
+
|
| 104 |
+
For **code-related evaluation tasks** (such as LCB), it is further recommended to set:
|
| 105 |
+
|
| 106 |
+
- `top_p = 0.95`
|
| 107 |
+
- `top_k = 40`
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
## Evaluation
|
| 111 |
+
|
| 112 |
+
- For tool-integrated reasoning, please refer to [this doc](https://github.com/zai-org/GLM-4.5/blob/main/resources/glm_4.6_tir_guide.md).
|
| 113 |
+
- For search benchmark, we design a specific format for searching toolcall in thinking mode to support search agent, please refer to [this](https://github.com/zai-org/GLM-4.5/blob/main/resources/trajectory_search.json). for the detailed template.
|